Inspiration
I bounce between Claude Code, Cursor, Codex, and Antigravity, and I live in hackathons — so I'm constantly opening fresh AI sessions. And every single time, the assistant knew nothing about me: not my stack, not the project I'd been building for two weeks, not my preferences. I re-explained myself every session, in every tool. The model was brilliant but completely amnesiac.
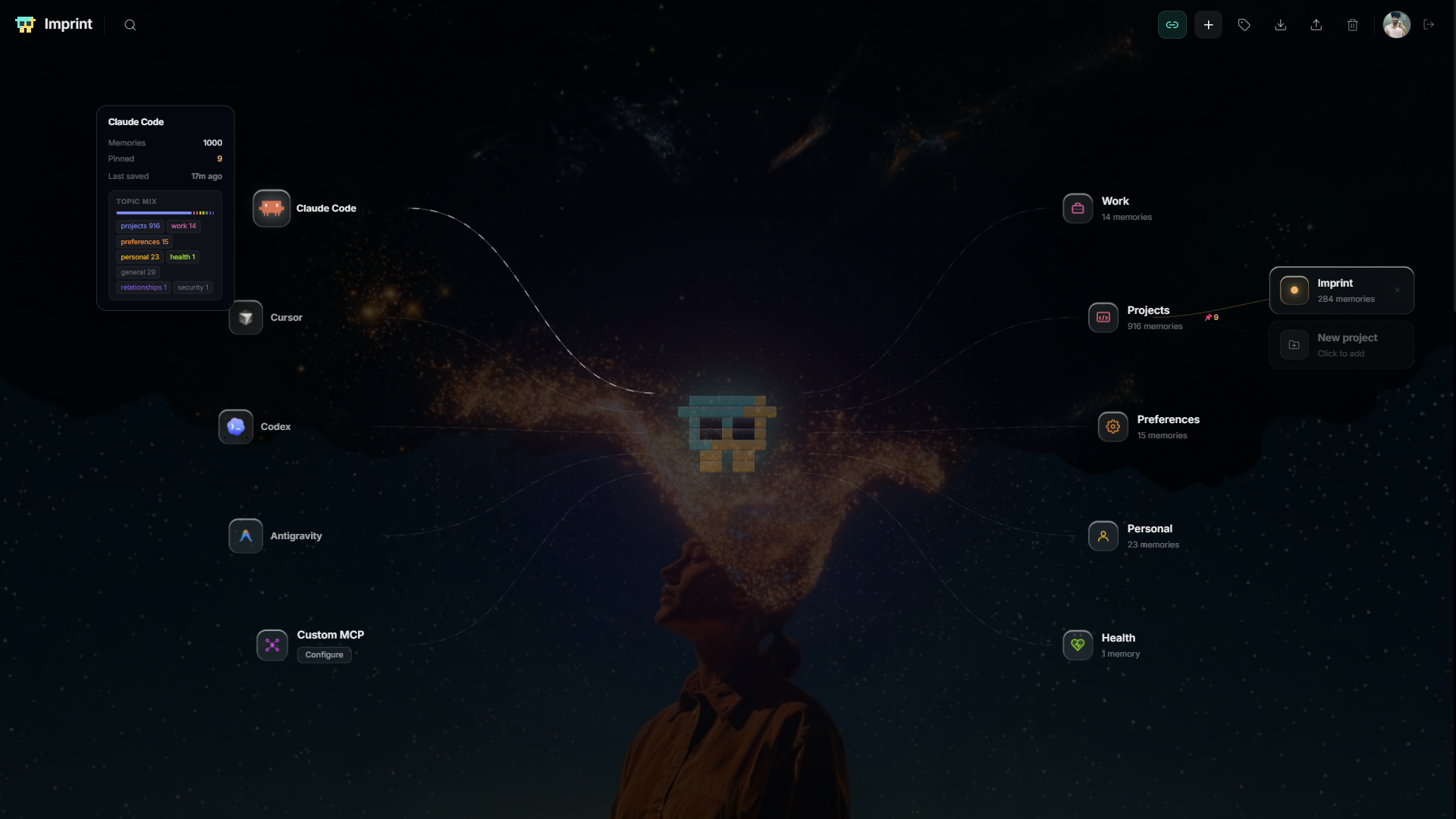
What bothered me most was that the memory features that did exist were trapped — ChatGPT's memory stays in ChatGPT, Cursor's stays in Cursor. None of it followed me across tools. So I asked one question: why can't my assistant just know me once, everywhere? That's Imprint. The name is the idea — a memory imprinted permanently, across every tool I use.
What it does
Imprint is a persistent memory layer for AI coding assistants. You just work — you never run commands or tag anything. As you talk to your assistant, Imprint silently extracts the durable facts worth keeping, stores them in the cloud, and injects the relevant ones back at the start of your next session. The assistant opens already knowing you.
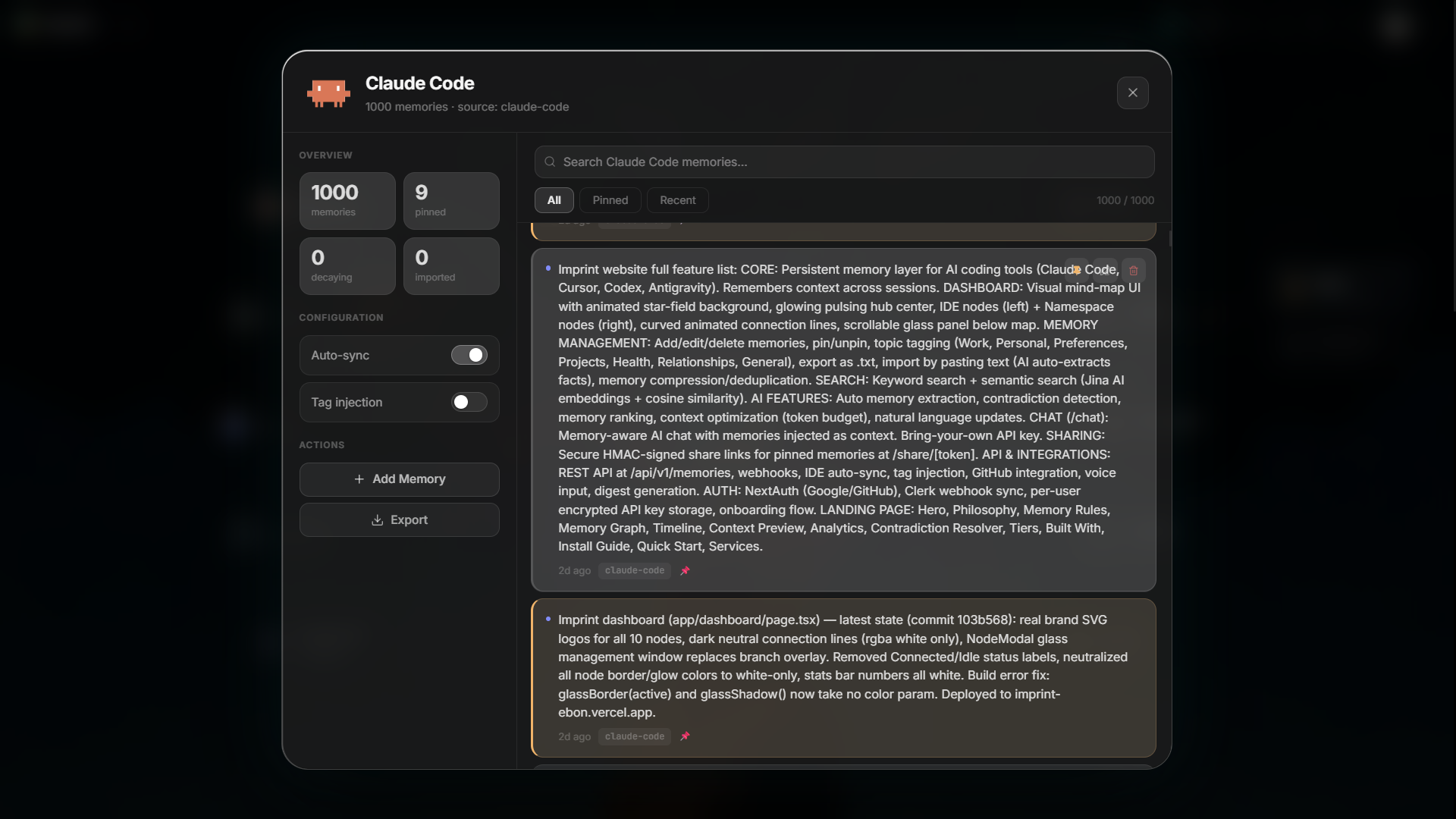
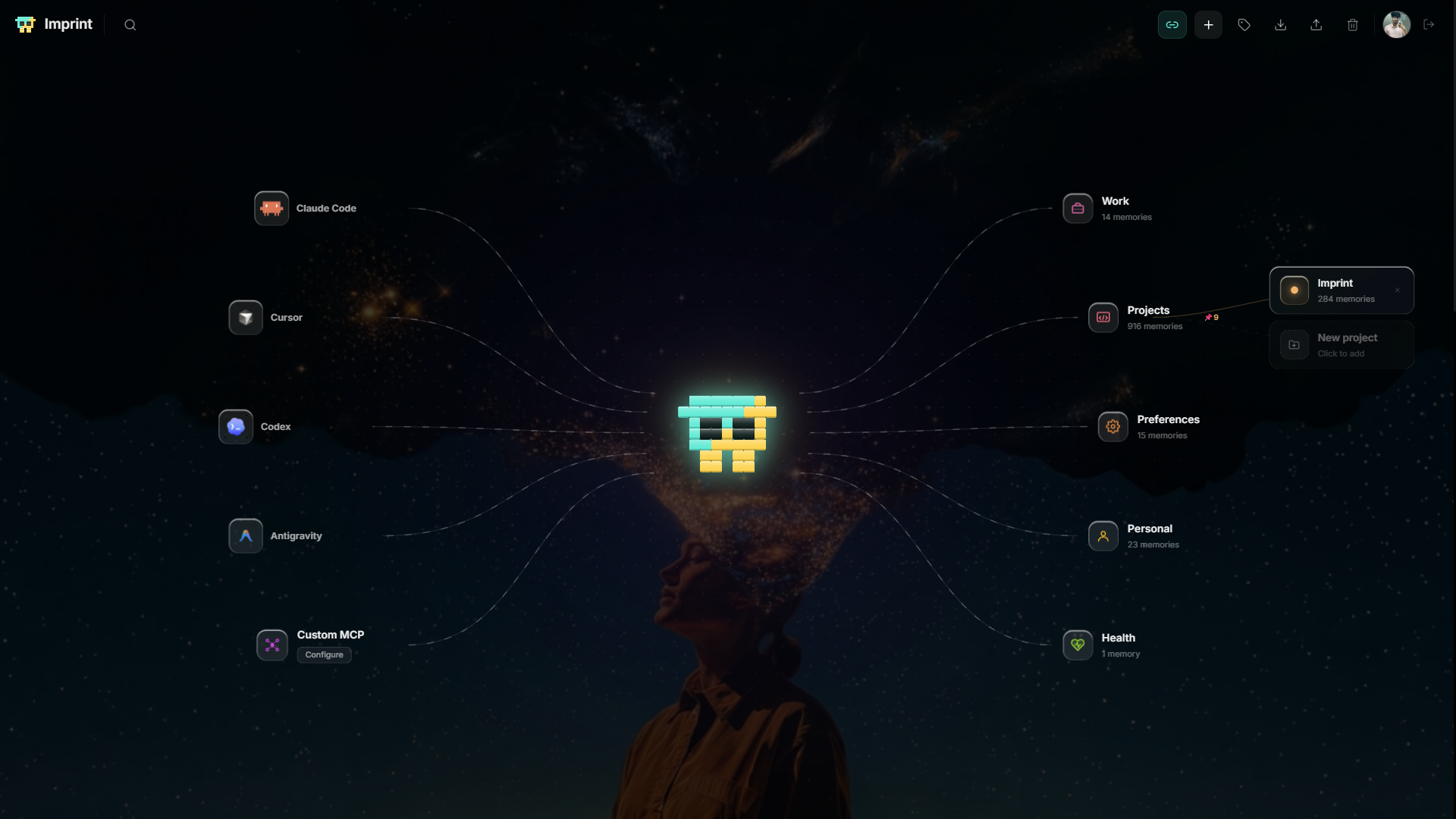
The key is that it's cross-IDE. A fact you teach in Claude Code is instantly available in Cursor, Codex, and Antigravity, because they all read the same store keyed to your user ID. A dashboard shows everything it remembers as a graph by topic — search, pin, edit, delete, and see conflicts. And it scales from a solo developer (a local MCP server) to an enterprise team sharing one memory pool, on the same backend, with no migration.
How we built it
I built it solo, from the storage layer up.
- Storage first: a single DynamoDB table where every memory is keyed
USER#<id>/MEMORY#<timestamp>#<id>— so one user is one clean partition, and that key is exactly what lets any IDE read the same memory. - API: Next.js 16 on Vercel —
/api/memories(save, search, pin, delete), plus rules, sessions, and org endpoints; NextAuth + Google OAuth for the dashboard. - The bridge: an MCP server in Node exposing five tools —
get_memories,save_memory,search_memories,delete_memory,pin_memory— so any MCP-capable IDE plugs straight in. - Auto-capture, two layers: instruction files tell the model to call
save_memoryitself, and a guaranteed Stop hook runs after every response and extracts facts with Groq (llama-3.3-70b) even when the model forgets. - Intelligence: Jina embeddings (1024-dim) for semantic search, relevance ranking so a session loads what's relevant not just recent, dedup, and real-time contradiction detection.
Semantic dedup and retrieval both rest on cosine similarity between memory vectors:
$$\text{sim}(a,b) = \frac{a \cdot b}{|a|\,|b|}$$
A new fact scoring above 0.92 against an existing one is treated as a duplicate and dropped, so the same fact never piles up. I kept the whole thing on free tiers — Groq, DynamoDB, Vercel — so it runs at effectively zero cost.
Challenges we ran into
The hard parts weren't the flashy features — they were the unglamorous correctness details.
- One memory, four IDEs. Every IDE wants its config in a different place and shape —
mcpServersJSON for Claude Code and Cursor, TOML for Codex, a buried~/.geminipath for Antigravity. I hit a setup path that assumed the repo lived in one folder when it didn't (throwingCannot find module), and a split-brain bug where my auto-save hook wrote to one user ID while the save tool used another, quietly splitting memories across two stores. Unifying onto one ID and verifying files exist before writing a config fixed it. - Everything got filed as "projects." My first extraction prompt leaned on words like "completed" and "next," which show up constantly in coding sessions — so almost every memory was tagged
projectsand the other topics looked empty. I reworked it to classify by the fact itself, not the activity around it. - Topics showing zero when they weren't. DynamoDB returns ~1MB per page, embeddings made rows heavy, and my topic filter ran after the limit — so any topic below the recent flood showed up empty. I added pagination and stripped embeddings out of API responses.
- Reliable capture. Depending on the model to remember to save was never enough, which is why the guaranteed hook exists. And to make setup work for everyone, the install and configure steps run as a Node one-liner that behaves identically in PowerShell, cmd, bash, and zsh.
Accomplishments that we're proud of
- Real-time contradiction detection — save a fact that conflicts with one you already have, and Imprint catches it on the spot and flags both, in the IDE and the dashboard. I haven't found another memory tool that does this; it's what keeps the memory self-correcting instead of quietly storing contradictions.
- True cross-IDE memory — one fact, taught once, available in Claude Code, Cursor, Codex, and Antigravity. Most tools are locked to a single app.
- Capture that doesn't depend on the model behaving — the Stop hook saves facts even when the assistant forgets to call the tool.
- One backend, solo to enterprise — the same store serves a single developer and a whole team's shared pool, with zero migration.
- Effectively $0 to run, entirely on free tiers, while still doing LLM extraction and embeddings on every save.
What we learned
- A memory layer is only as good as how invisibly and reliably it captures and recalls. Most of my time went into boring correctness — dedup, decay, the right user ID, the right topic, the right page — because that's what makes it feel like the assistant simply knows you.
- Retrieval should be by relevance, not recency. Returning the most recent memories is the mistake that makes memory feel dumb; embedding the user's actual question and ranking by similarity changed the entire feel.
- Never trust the model to remember the bookkeeping — design a guaranteed fallback.
- Cross-platform support is mostly a thousand tiny details: shells, path separators, JSON vs TOML, and where each IDE hides its config.
- Privacy has to be a default, not a setting — which is why sensitive topics ship off until you turn them on.
What's next for Imprint
- More surfaces: first-class Windsurf, JetBrains, and VS Code Copilot support, plus a guaranteed-capture hook for IDEs beyond Claude Code.
- Smarter organization: auto-grouping memories into the specific project they belong to, so the dashboard maps cleanly to what you're actually building.
- Memory you can reason over: per-project memory digests, and surfacing why a given memory was recalled.
- Team depth: richer enterprise controls — roles, per-project pools, and an audit trail of what's shared.
- Trust & control: stronger handling of sensitive memories, full export/import, and one-click forget.
Built With
- aws-dynamodb
- groq
- jina-ai
- llama
- mcp
- next.js
- nextauth
- node.js
- react
- typescript
- vercel

Log in or sign up for Devpost to join the conversation.