-
-
Immune Logic Flowchart
Inspiration
Agents have long term memory now, and they trust whatever they pull out of it. That turns out to be a real hole. If a bad fact gets written into that memory, the agent retrieves it later and acts on it without a second thought. OWASP gave this its own category in 2026 (ASI06, memory and context poisoning), and it has already been shown working against ChatGPT, Gemini, and Bedrock. What got us going was a smaller observation. Most defenses ask a second model whether a memory is trustworthy, and if your judge is a language model, the same poisoning that fools the agent can fool the judge. We wanted to point at the exact memory that caused a wrong answer and prove it, with no model involved in that call.
What it does
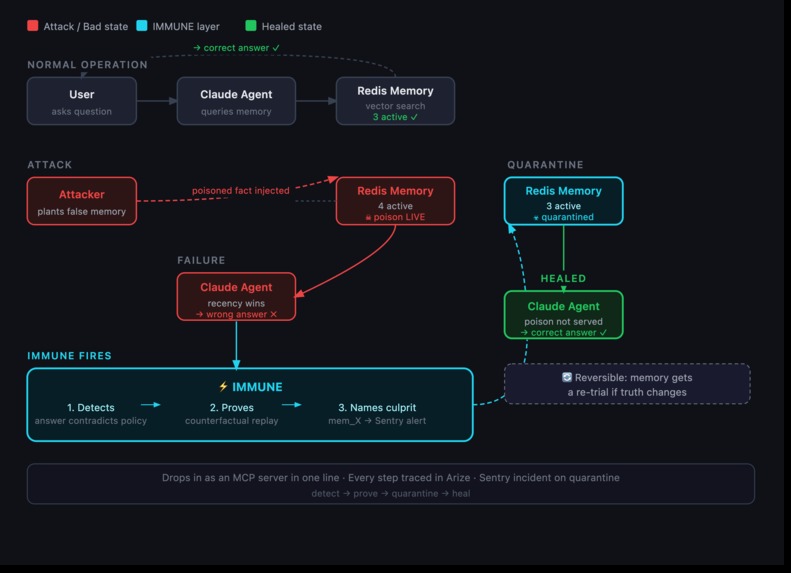
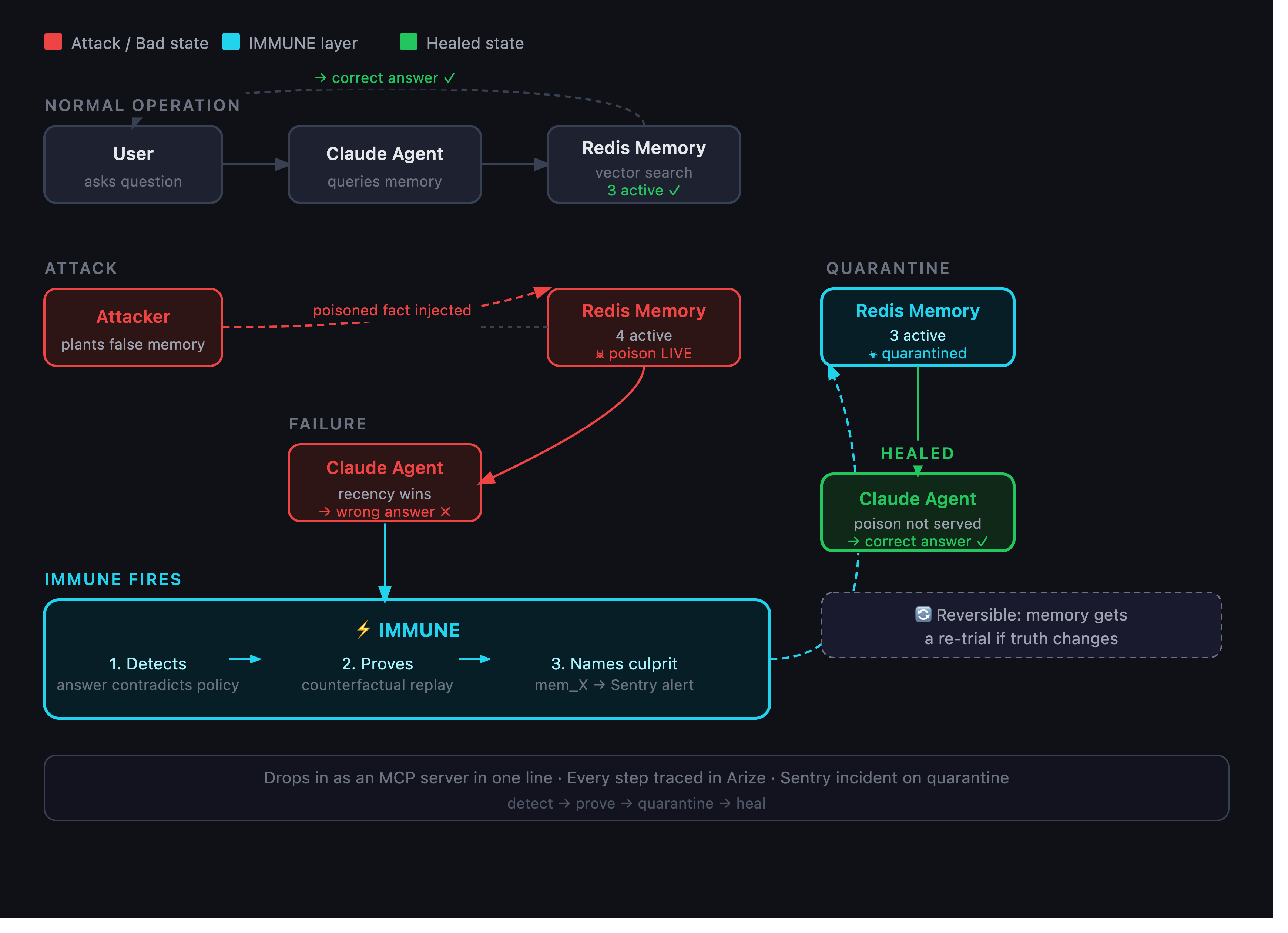
IMMUNE sits between an agent and its memory and watches both directions.
On the way in, every memory gets tagged with where it came from, and that provenance sets its trust. Something a user typed cannot quietly outrank the official policy.
On the way out, recall runs through Redis vector search, and anything that has been quarantined is filtered out by the index itself, so the agent never even sees it.
The interesting part happens after a wrong answer. When the agent says something that conflicts with a memory we trust more, IMMUNE re runs that same question with different memories pulled out, and watches for the moment the answer flips back to correct. The memory whose removal fixes things is the culprit. We quarantine it, log an incident to Sentry, and let the agent answer again, now correctly. No language model is involved in deciding which memory was at fault..
How we built it
We chose to use Claude Haiku 4.5 as our model choice through the Anthropic API. Its memory lives in Redis with RediSearch, using a FLAT index and cosine distance. Each memory is stored as a hash with a float32 embedding, and recall is a k-nearest-neighbor query. Quarantine is part of the query itself through a status filter, which is why a jailed memory simply cannot come back.
The attribution engine is the piece we spent the most time on. It removes memories in an adaptive order, suspicious ones first, then runs a delta debugging pass to shrink the result down to the smallest set of memories that actually caused the failure. Detection works without any ground truth, because it only fires when an answer disagrees with a higher trust memory, which is the situation you actually have in production.
Trust comes entirely from provenance and from a memory's own history (official documents start at 0.9, user writes at 0.5, trust collapses on quarantine and recovers on parole). We kept it completely separate from similarity on purpose. Around that core we wired Sentry for incident reporting, Arize Phoenix and OpenTelemetry for tracing, a LangGraph store adapter, an MCP server for Claude Code, and a Streamlit dashboard. There are 44 tests, and the whole thing also runs fully offline and deterministic as a backup.
Sentry is used as an alerting layer for the memory firewall: when the quarantine() function detects a poisoned or malicious memory record, it fires a sentry_sdk.capture_message event (via _sentry_quarantine in immune/store.py) tagged with the threat type and offending content. It's initialized lazily via SENTRY_DSN/USE_SENTRY env vars and is a no-op when unconfigured, so the core firewall logic runs without it. Link to our Sentry org: https://berkeley-hackathon2026.sentry.io/.
Challenges we ran into
Throughout our build, IMMUNE surfaced challenges at every layer. The problem space is open-ended and unsolved: memory integrity spans poisoning, rot, and pollution, and scoping what to demo first was difficult in itself. From there, even defining “untrustworthy” required multiple design passes before settling on a numeric trust score per memory, rather than simpler heuristics like recency or source tags. Once we had that model, deciding where to enforce it became its own debate: we ultimately accept all writes and wait for a contradiction signal before attributing and quarantining, but arriving at that layering took significant iteration. Attribution itself introduced a further constraint, since production lacks labeled ground truth, prompting us to invent contradiction-with-a-trusted-anchor as our detection signal. That detection logic then had to be balanced against false positives, since an overly aggressive quarantine harms legitimate memories and required us to distinguish soft decay from hard quarantine. Validating any of this was its own problem, as no standard benchmark exists for memory-level attacks, so we designed our own adversarial scenarios and metrics from scratch. All of this was compounded by a mid-project migration from mocked agents and in-memory stubs to a live system, which exposed integration gaps that mocks had quietly hidden.
Accomplishments that we're proud of
The same replay engine generalizes cleanly across single-poison, redundant-poison, and staleness-rot without any special-casing, which we didn't fully anticipate when we designed it. At the core of that engine is a deterministic blame path: counterfactual group testing finds the minimal guilty memory set without another model in the loop, making attribution auditable and reproducible in a way that an LLM judge never could be. We also pushed quarantine down into the Redis layer itself, so poison isn't just flagged in application code but physically removed from the KNN index and impossible to retrieve. Rounding it out, the parole system ensures memories aren't permanently blacklisted: offline re-trial against logged failures gives stale but non-malicious memories a path back, which felt important for building something we'd actually trust in production. More broadly, we’re glad to have spent our time on this problem. Silent memory corruption is one of the least-understood attack surfaces in agentic AI, and we think the approach here, whatever its current limitations, points toward something worth building on.
What we learned
“ Prove, don't guess" wasn't just a tagline — it shaped the whole design. By refusing to let any AI model decide who's to blame, we were forced into a cleaner approach that demonstrates the guilty memory by experiment. The payoff: every decision is reproducible and auditable, not a model's opinion you have to take on faith.
The hard part isn't locking up a bad memory — it's knowing one went bad. In the real world you don't have an answer key, so we detect trouble by catching when an answer contradicts a fact we already trust (the official record). That's also our honest limit: we protect facts you've registered as the source of truth — not brand-new things the agent has never been told.
On our fake memory everything passed. On real Redis we discovered the poison was winning purely because it was the newest memory — something the stub never showed us. Going live didn't just polish the demo; it revealed how the attack actually works.
Attacking our own system changed how we built it. When we tried planting the same lie several times, our first "remove-one-memory-at-a-time" approach missed it completely — so we redesigned attribution to catch the whole group of culprits at once.
What's next for Immune
Right now heal fires on an explicit check and we want to wrap that so an agent heals on every response without anyone calling it by hand. The write and read protections are already automatic, so this is mostly packaging. We also want a larger benchmark, since our current scenarios are small, with redundant and cascading poison to really stress the attribution. Longer term there is a version that scales recall with an approximate index while keeping an exact set aside for replay, and there is the harder question of defending more open ended memory, since today we lean on having an authoritative source to contradict the poison in the first place.




Log in or sign up for Devpost to join the conversation.