ImmigLens
ImmigLens is a card-based reader for immigration news: you swipe (or scroll) through headlines, open a card for depth, and see what the story claims, how that lines up with primary and research sources, and how framing and missing context shape the takeaway. You can also paste an article URL so the same pipeline runs on a story you care about.
What inspired us
Immigration shows up everywhere—as headlines, threads, and group chats—and it touches high-stakes decisions and emotions. We kept seeing the same pattern: a piece could raise a real concern while still making a weak or lopsided factual claim. We wanted a tool that feels civic and calm (closer to “show me the receipts” than “pick a side”), and that helps people compare narratives without treating communities as the problem.
That led to three non-negotiables:
- Grounding — Verdicts should lean on fetched government, legal, and research text, not on whatever a model “remembers.”
- Transparency — Every serious claim should trace to sources users can open.
- Perspective without caricature — Separate immigrant- and non-immigrant–centered concerns from the factual question, so legitimate worries are not dismissed just because a headline overreaches.
How we built it
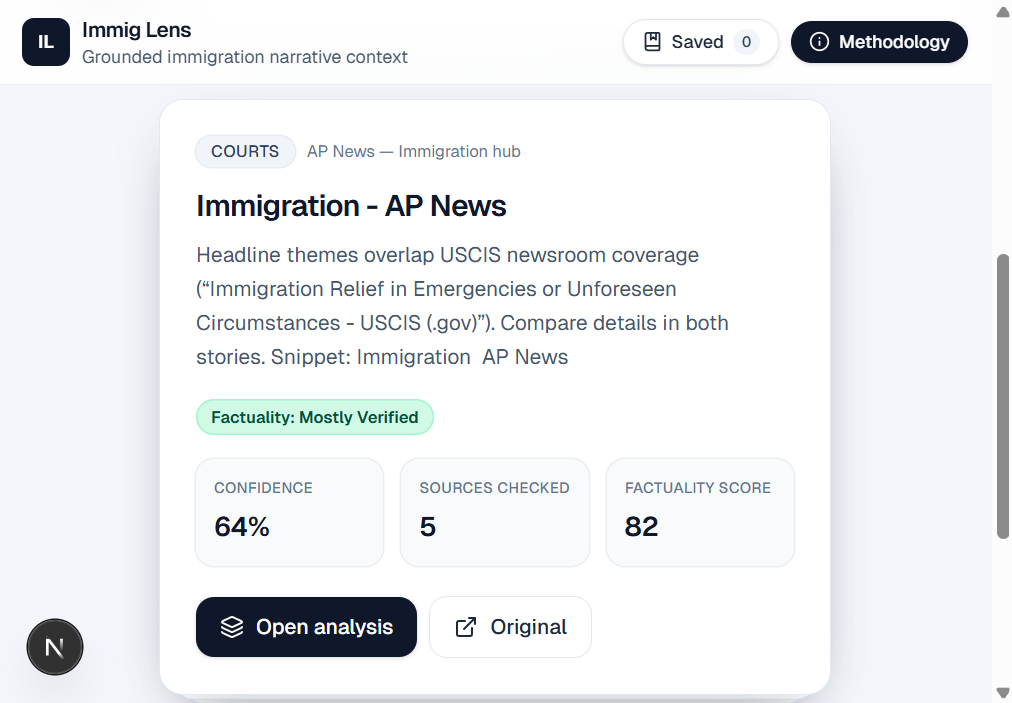
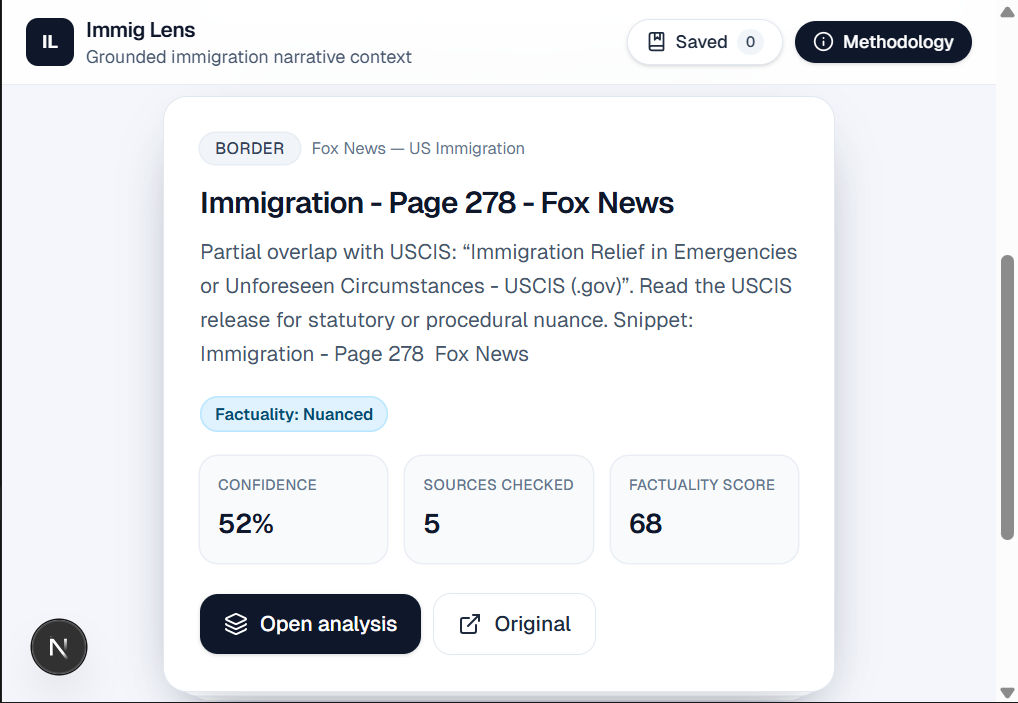
Product shape: A feed of cards (Framer Motion for swipe, scroll fallback for desktop), each with topic, factuality, bias/perspective signals, confidence, and source count. The expanded view carries the demo: main claim, verdict, evidence for / against / context, bias signals, and a full source list with links.
Backend (concept → implementation): A modular pipeline—fetch article → extract claim → classify topic → select trusted domains from a registry → fetch excerpts → compare and score → return strict JSON—exposed via Next.js API routes. Anthropic Claude handles structured extraction and comparison, with prompts that forbid citations not present in the numbered excerpt blocks.
Data (where applicable): Analyses and source rows in Supabase, with Redis caching for stable demos and repeat URLs—so judging does not depend on “random rerolls.”
Challenges we faced
- Evidence vs. speed: Primary sources are authoritative but noisy (PDFs, long policy pages). We had to balance readable excerpts with faithful context.
- Hallucination pressure: The hardest part is not generating text—it is enforcing “only from these excerpts” under tight JSON. We leaned on numbered source blocks, schema validation, and UI that surfaces exact URLs used.
- Sensitive topic UX: We avoided accusatory visuals and framed bias as framing, not moral failure—while still being honest about misleading or unsupported claims.
What we learned
- Grounding is a product feature, not only an engineering safeguard. When users can click through, trust goes up.
- Good immigration tooling needs to hold two things at once: respect for lived stakes and discipline about what the data actually says.
- Demo clarity beats raw capability: a short pipeline (fetch → claim → sources → verdict) beats a black box, especially for judges and new users.
Looking ahead
Richer topic-aware source registries (e.g., asylum vs. labor vs. benefits), better handling of paywalled pages, optional multilingual summaries, and saved articles if we add auth.
A note on how we think about confidence
We use a confidence score γ between 0 and 100 (inclusive). It should rise when several on-topic excerpts support the verdict, and stay low when evidence is thin—regardless of how confident the model’s wording sounds.
Built With
- anthropic
- anthropic-claude-api
- api
- claude
- css
- framer
- framer-motion
- javascript
- lucide
- lucide-react
- motion
- next.js
- postgresql
- railway
- react
- redis
- supabase
- tailwind
- tailwind-css
- typescript
- upstash
- upstash-redis
- vercel
- vercel-(or-your-host)

Log in or sign up for Devpost to join the conversation.