-
-

Storytelling from Imagunet
-

Engage. Imagine. Learn. Motivate. Repeat. Customize our children interactions and save their progress.
-

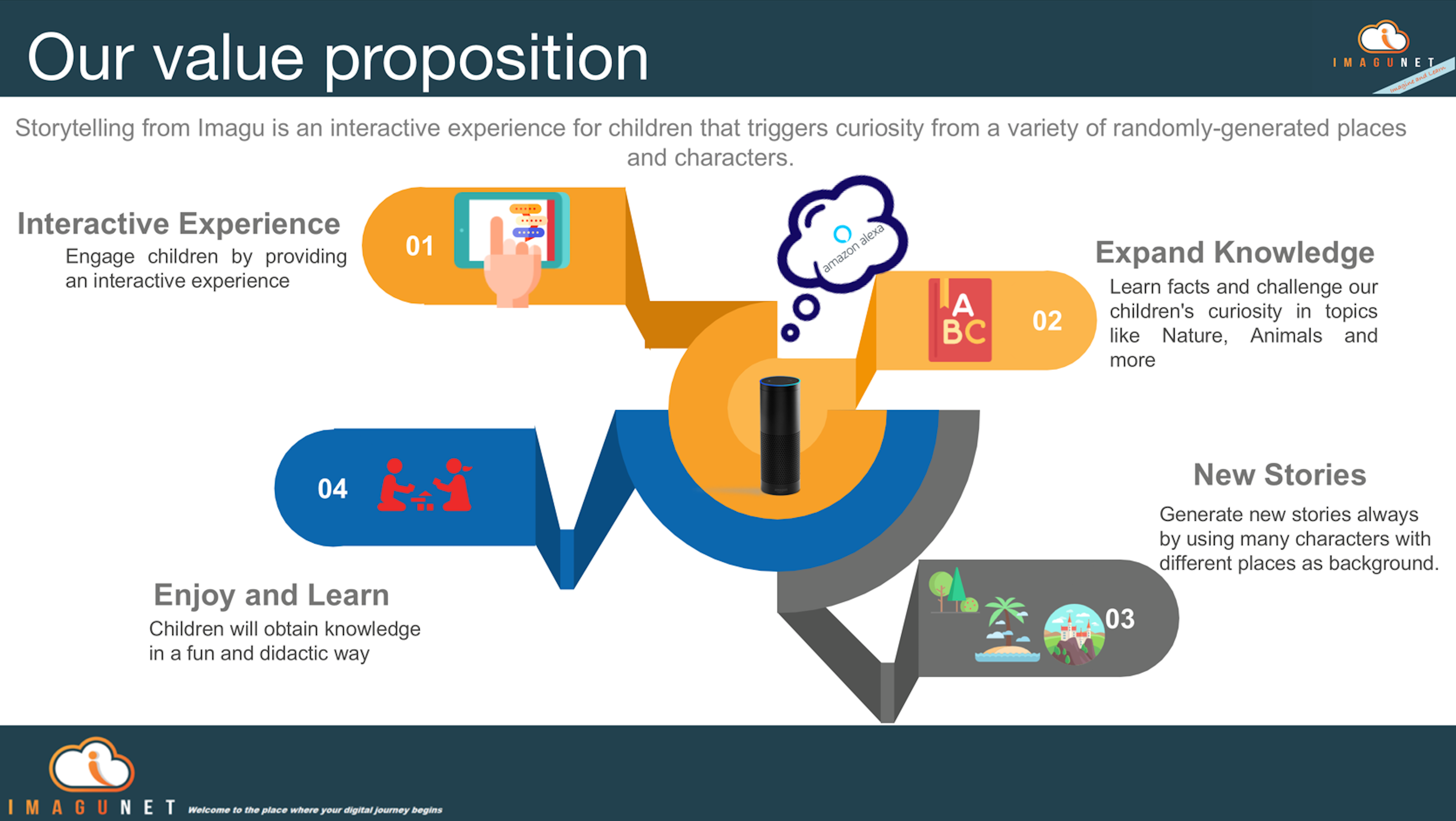
Value proposition. Interactive experience for kids with randomly generated scenarios and characters
-

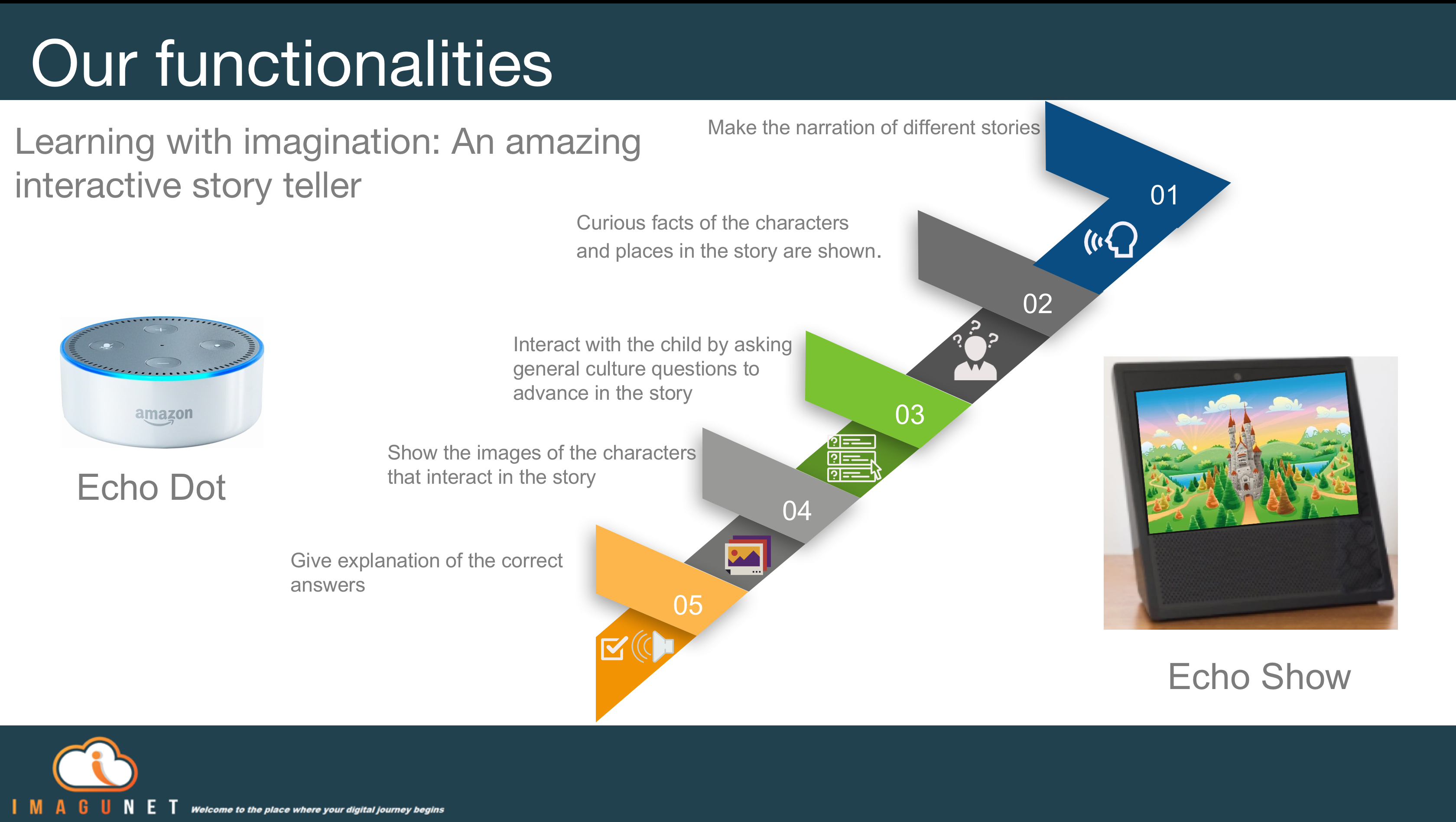
Functionalities and features
-

Solution architecture. Using Lambda, S3 and DynamoDB to create randomly generated stories with customized characters
-

Fun




Inspiration
Voice recognition has such potential, our kid´s education is a fantastic ground to put so much information at their disposal by using voice and natural language as catalyst.
Using the capabilities for a human-like dialog and all the features for voice shaping in Alexa, we are convinced that a compelling storytelling learning application can be made available for kids.
What it does
Trigger curiosity into a broad scope of general-knowledge topics by engaging into funny facts and not-so-known discoveries that changed the way a kid perceives his/her world.
Each story is randomly generated and both characters as facts are being customized to each choice made.
The application customizes the experience by saving his/her progress to each scenario. Such saved progress is available for further interactions making it more compelling and simple to return over and over again while exploring all scenarios available.
How we built it
The core application runs on a Lambda function built on Python 3.6 which captures all events configured in our Interaction model and defines:
- When to read from our configuration files repository in S3.
- When to store or retrieve session status from our DynamoDB table.
- When to trigger new selections or close the session definitely.
The configuration file repository is critical since it stores all data being created by any content creator while providing full customization:
- Characters with specific voice features like pitch and rate as well as bound them to specific areas.
- Facts specific for each character
- Questions available for all characters on any scenario.
- Natural language enables like bounding phrases and introduction paragraphs.
- Scenarios and places available within those scenarios; for complex and more engaging interactions.
Our DynamoDB table is responsible for storing session information like current scenario, character and questions being shared. Everything is bonded by a sessionID (created from timestamps) stored at application launch.
Finally, all images used were obtained thanks to the amazing Unsplash and its artist community including: Annie Spratt, John Cobb, Andrea Reiman, Matt Sclarandis, Brigitta Schneiter, Mohammad Metri, Pedro Lastra, Ryan Grewell and many others.
Challenges we ran into
Making sure that we understood directives correctly was critical due to the conversational nature of the application and the demand for Render-Templates on our Echo Show development. Making sure that our selection of S3 and DynamoDB storage could scale to meet demand was tough, since we focused on preserving our innovative randomly generated interactions on complex configuration files. English is not our native language so triggering the right Skill in echosim.io was quite funny and time-consuming at times.
Accomplishments that we're proud of
Being able to have the basic interaction model in a few days while orchestrating the functional aspects in parallel. Creating a framework that enables parents and other content creators to add stories, characters, facts and questions without modifying our core Lambda function.
What we learned
How to operate under an Alexa Skill kit workflow Improving our skills in Lambda functions basics like interacting with DynamoDB and S3 files in a more refined way.
What's next for ImaguVoice: Learn with imagination
We would love to continue to improve our solution in all fronts, but our short-term priorities are:
- Including customized illustrations in our Echo show capabilities instead of using full photos from our friends in Unsplash
- Enable Render and Dialog directives to work better within our current operation framework in Lambda.
- Providing a content creation app for parents to include new scenarios, places, characters and questions. Making sure that its content is permanently revised to keep our application children-safe.





Log in or sign up for Devpost to join the conversation.