-
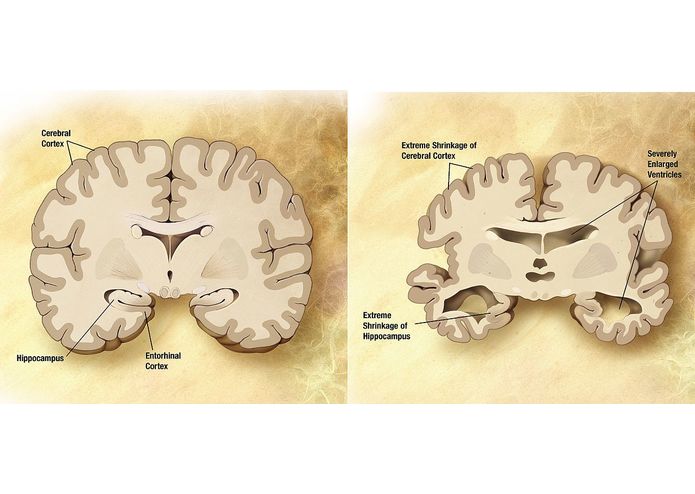
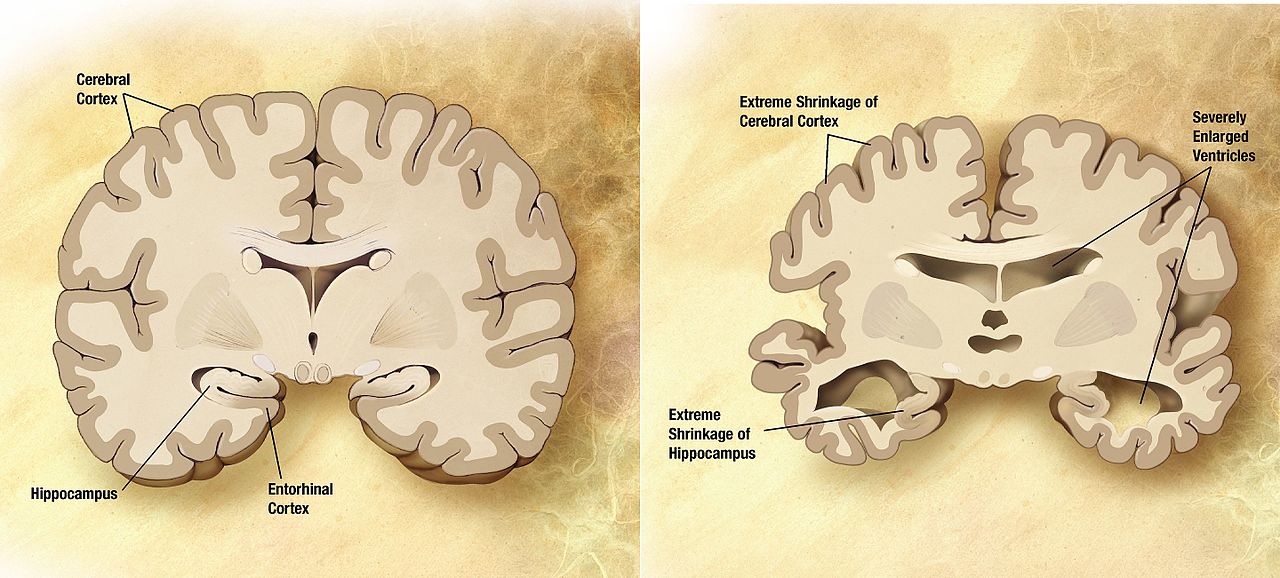
Figure 1: Alzheimer's disease (AD) is associated with brain shrinkage: left normal brain; right AD. (source: Wikimedia)
-
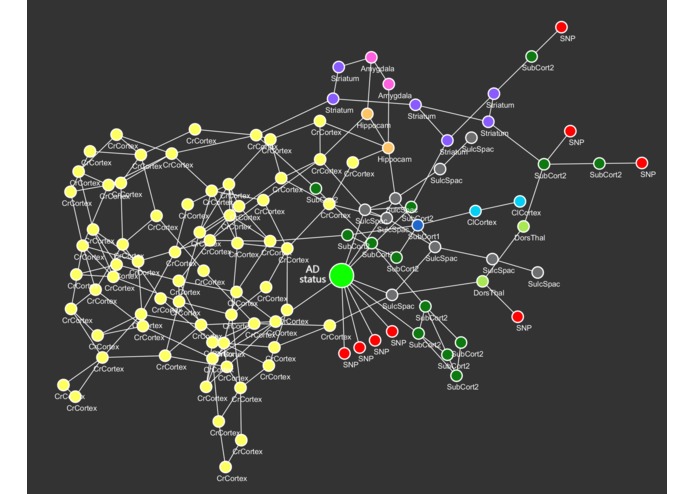
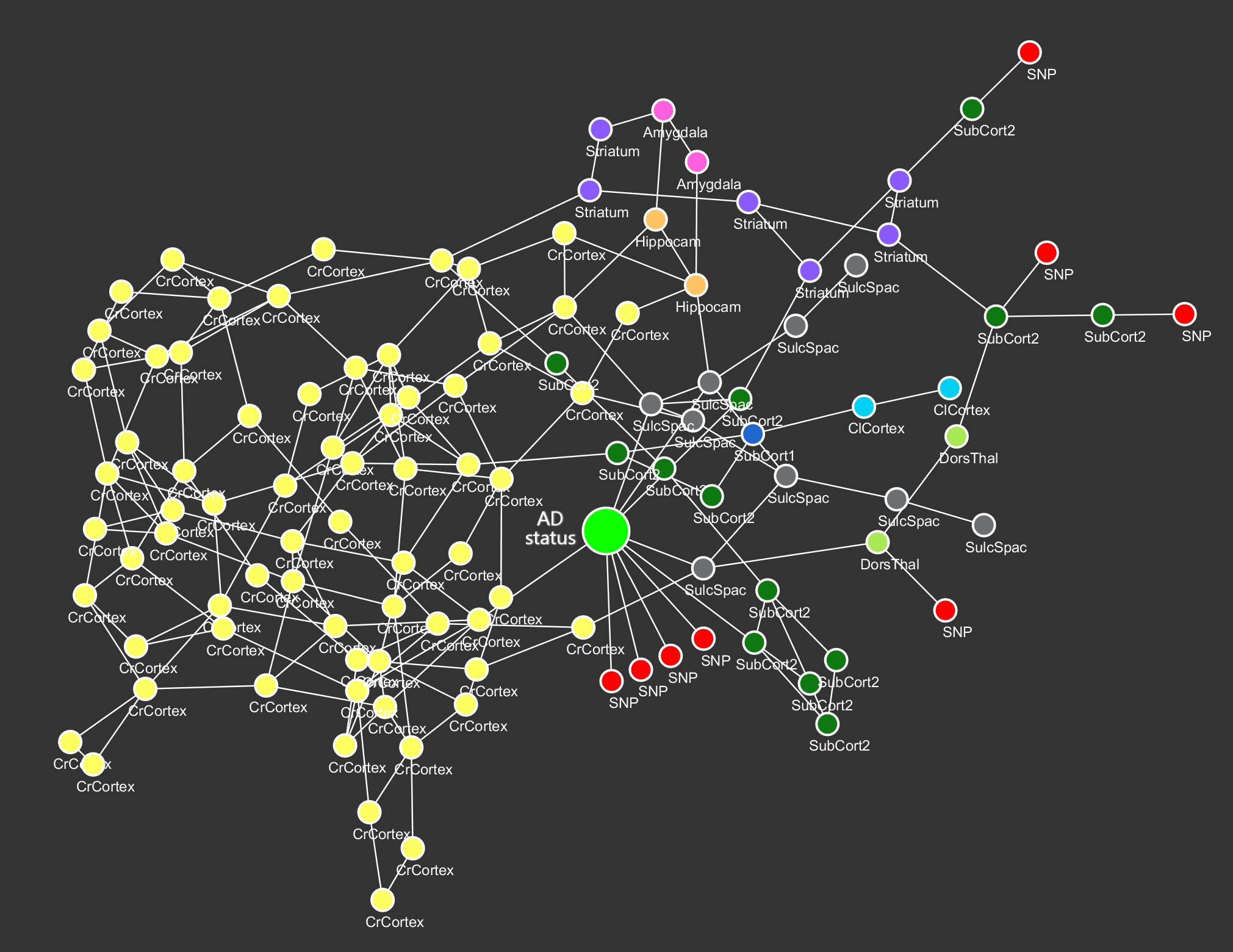
Figure 2: Graph for SNPs (red), brain area volumes (colored by region), and AD status (bright green). The underlying graph was directed.
Inspiration
Alzheimer's disease is the main cause of dementia in elderly people, and it has a strong genetic component. The disease is characterised by short-term memory loss and a shrinkage of several brain areas (see Figure 1). Despite extensive research into this neurodegenerative disease, the biological causes remain elusive. We set out to find the relationships between known genetic causes, shrinkage of brain areas, and disease status.
What it does
Figure 2 shows the relationships between genetic variants (SNPs), the sizes in several brain areas, and disease status. The original (directed) graph shows that SNPs can cause disease progression in two distinct ways: either directly (via molecular mechanisms not incorporated in the model) or through shrinkage of several brain areas. Brain area nodes with the same color belong to the same (larger) brain area, and these show many causal links between them. This reflects the strong correlation in the change of anatomically similar brain areas. The analyses were run on two random splits of the data. In both sets of patients we saw the same strong connections between anatomically similar brain areas, but most of the SNP effects were not reproducible.
How I built it
We made use of the public data of the Alzheimer's Neuroimaging Initiative (ADNI), which contains imaging genetics data of 746 individuals: 176 AD patients, 211 healthy controls (CN), and 359 individuals with an intermediate phenotype (LMCI). We selected 35 known (from external data) AD-causing SNPs, and 105 brain area volumes to build a causal model. The final model was made using the Tetrad software. We encoded the SNPs and brain area volumes as continuous values, and the disease state (CN, LMCI, AD) as a nominal variable. To find the causal relationships between these variables, we ran a Fast Causal Inference (FCI) with the Tetrad default settings. We considered the SNPs to be exogenous (tier 1), and the disease state (tier 3) to be an effect of SNPs or brain volumes (tier 2).
Challenges I ran into
The Tetrad software provides algorithms for mixed data types. However, the data import functionality is automatic: it decides based on the number of (user-provided) levels whether a variable is continuous or discrete. Both the SNP variables (0, 1, 2) and the disease state (CN, LMCI, AD) have three levels, but we wanted to consider the SNPs as continuous variables (corresponding to an additive genetic model). To avoid automatic conversion to discrete variables, we added a very weak Gaussian noise to the SNP values. The layout and visualisation options of the Tetrad software are somewhat limited (it has no node-color settings for instance). Therefore we made use of the Cytoscape plug-in. Unfortunately this plug-in does not handle green edges correctly, since these are simple removed. As a work-around we converted the FCI PAG to an undirected graph in Tetrad before importing it into Cytoscape. In this way we maintained all edges, at the cost of losing directionality in the visualisation.
Accomplishments that I'm proud of
We are planning a study on a larger (and non-public) dataset. To prepare for this, we also ran the ADNI analyses (with GFCI) on the OpenMind cluster at MIT. As a result we can now apply the valuable causal discovery algorithms on our new data without much extra effort.
What I learned
Causal discovery algorithms can be applied on reasonably large datasets and offer a good opportunity for hypothesis generation. However, we have to take care in the interpretation of the results, since they may not be very stable. We learned to work with the Tetrad software, which helps in formalising ideas and structuring the analyses in a graphical way, and with Causal Command, which has advantages in reproducibility and speed.
What's next for Imaging genetics for Alzheimer's disease
We will apply the causal search algorithms on a new dataset, with a larger number of genetic variants and multiple disease-related outcome variables. In contrast to the ADNI dataset, we have little idea of what to expect, so we are excited to give it a try.
Built With
- causal-command
- cytoscape
- r
- tetrad


Log in or sign up for Devpost to join the conversation.