Inspiration & Problem
We care deeply about building technology that solves real-world problems. In the past, we’ve grown an EdTech community of thousands of kids & parents across the world, and we’ve been fortunate to win top awards at several global hackathons (MIT, Harvard, Princeton, Google, Amazon + more). These experiences sharpened our ability to design for real users and build practical solutions that scale.
Now we’re focused on what we believe is the next leap for edutainment: a new kind of video medium that feels truly interactive. Traditional one-way video wasn’t designed for curious young minds–it can’t see what a learner draws, can’t hear their reasoning, or adapt to their thinking in the moment. We believe the future of edutainment is immersive and responsive, which is why we’re pushing the limits of what’s possible with Gemini 3’s multimodal intelligence, deep reasoning, and agentic capabilities.
What it does + How we built it
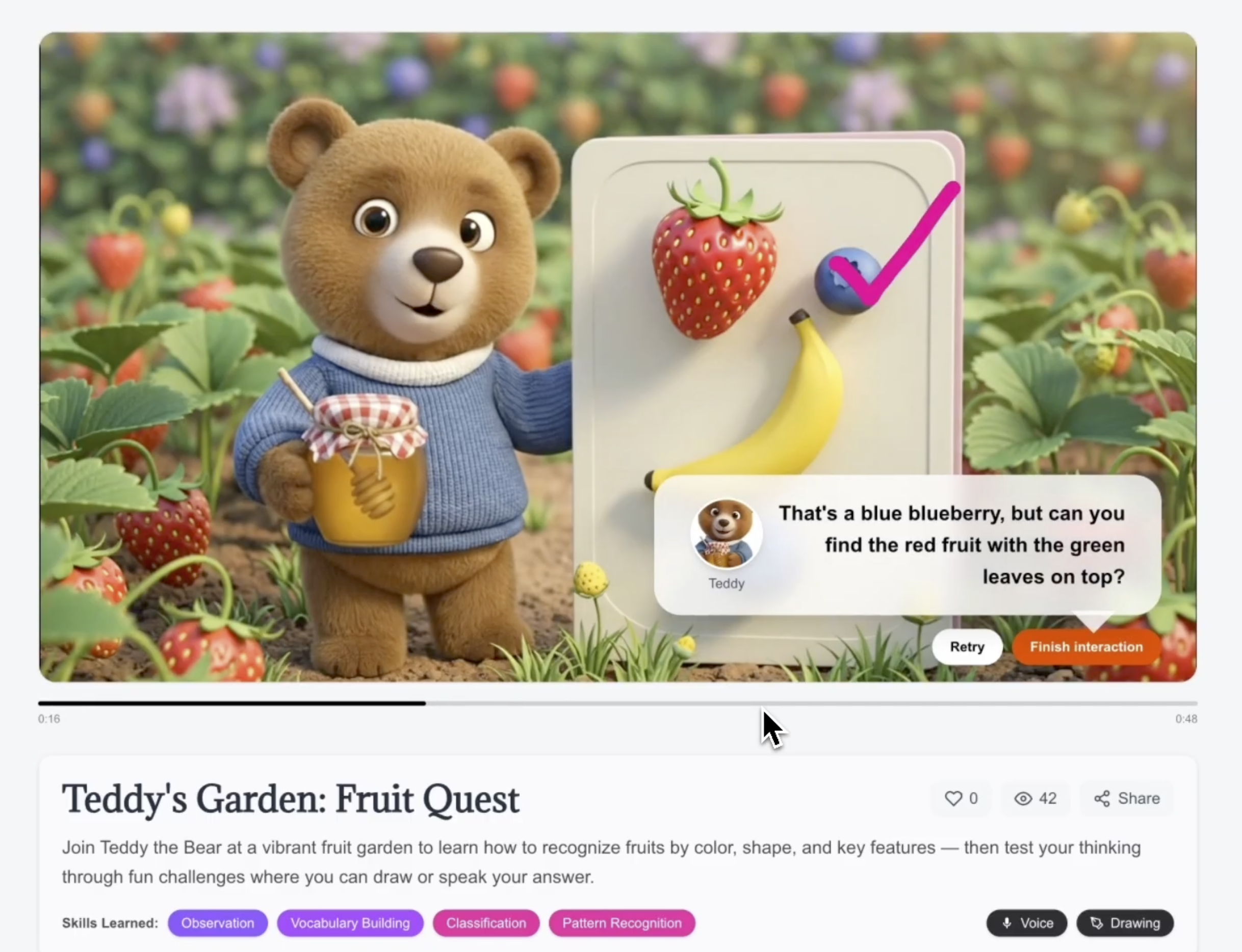
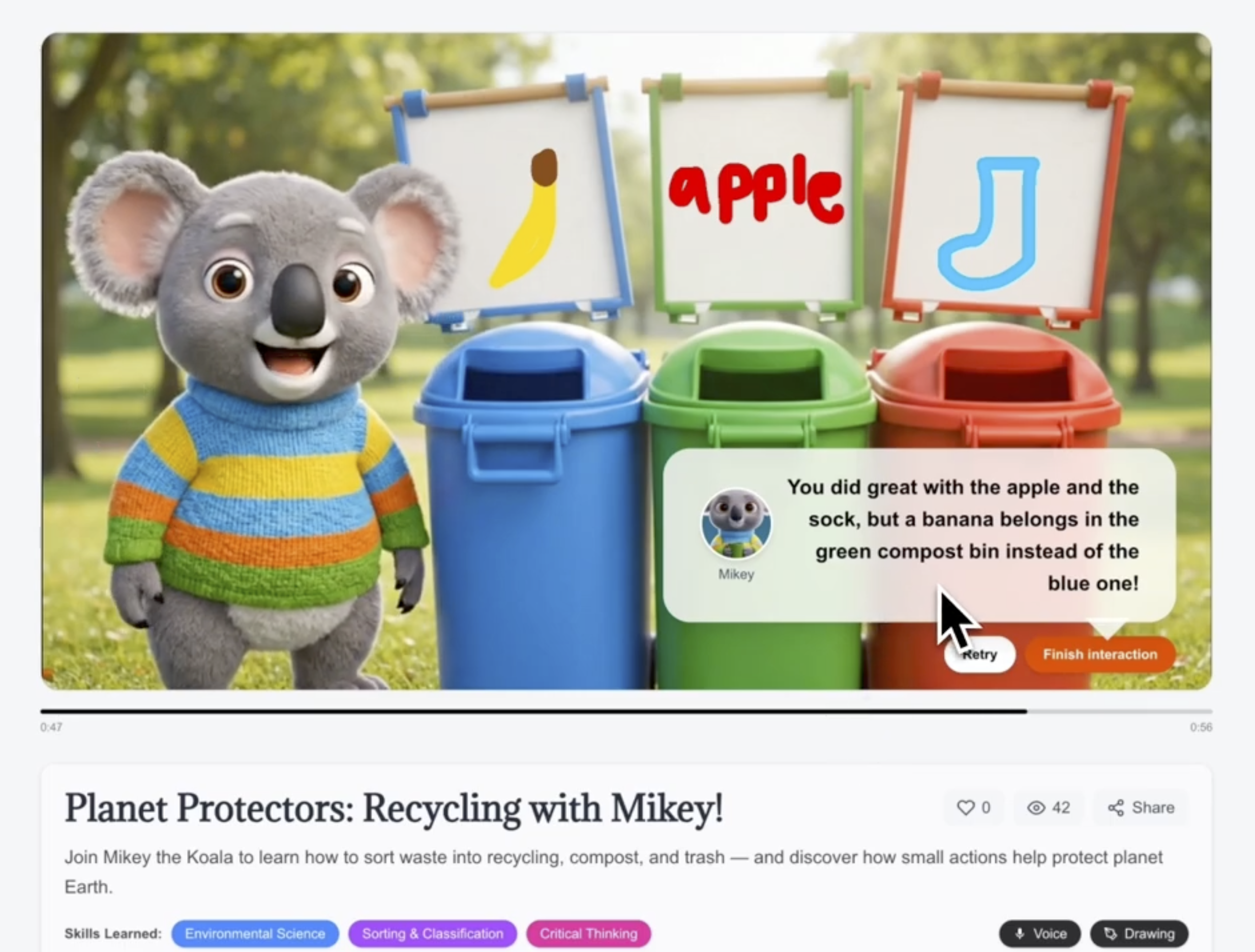
Imaginable is a creative engine capable of planning, generating, and orchestrating interactive, multimodal video experiences end-to-end – powered by Gemini 3, the Gemini Live API, Veo, and Nano Banana. How do we turn video into a two-way medium? At the core is our AI-Native Interaction Layer: a runtime system that embeds live multimodal agents directly into the video at key interaction checkpoints. Learners don’t just watch. At each checkpoint, they can interact in two accessible modes – drawing on the screen or speaking out loud. These interactions are inherently spatial: kids can circle shapes, sketch ideas, solve problems visually, and demonstrate their thinking within the narrative itself. The result is active behavioral learning– spelling, writing, drawing, explaining, and refining ideas in real time. We unlock personalization at scale with Gemini 3: kids can draw their own characters, parents can co-create episode themes, and each experience feels uniquely theirs–creating a new kind of edutainment where kids draw, speak, and think with their characters in real time through AI-native interaction checkpoints.
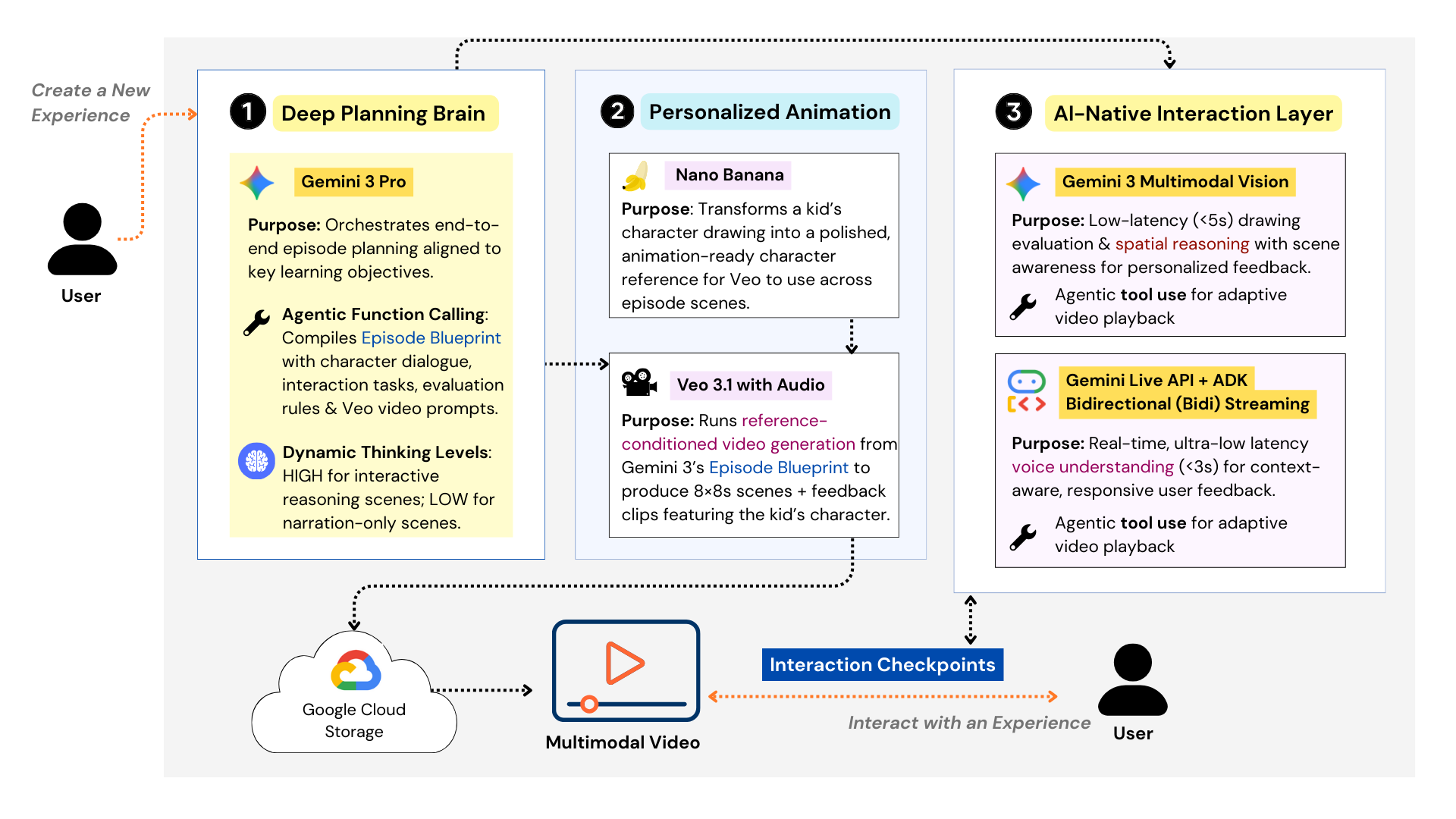
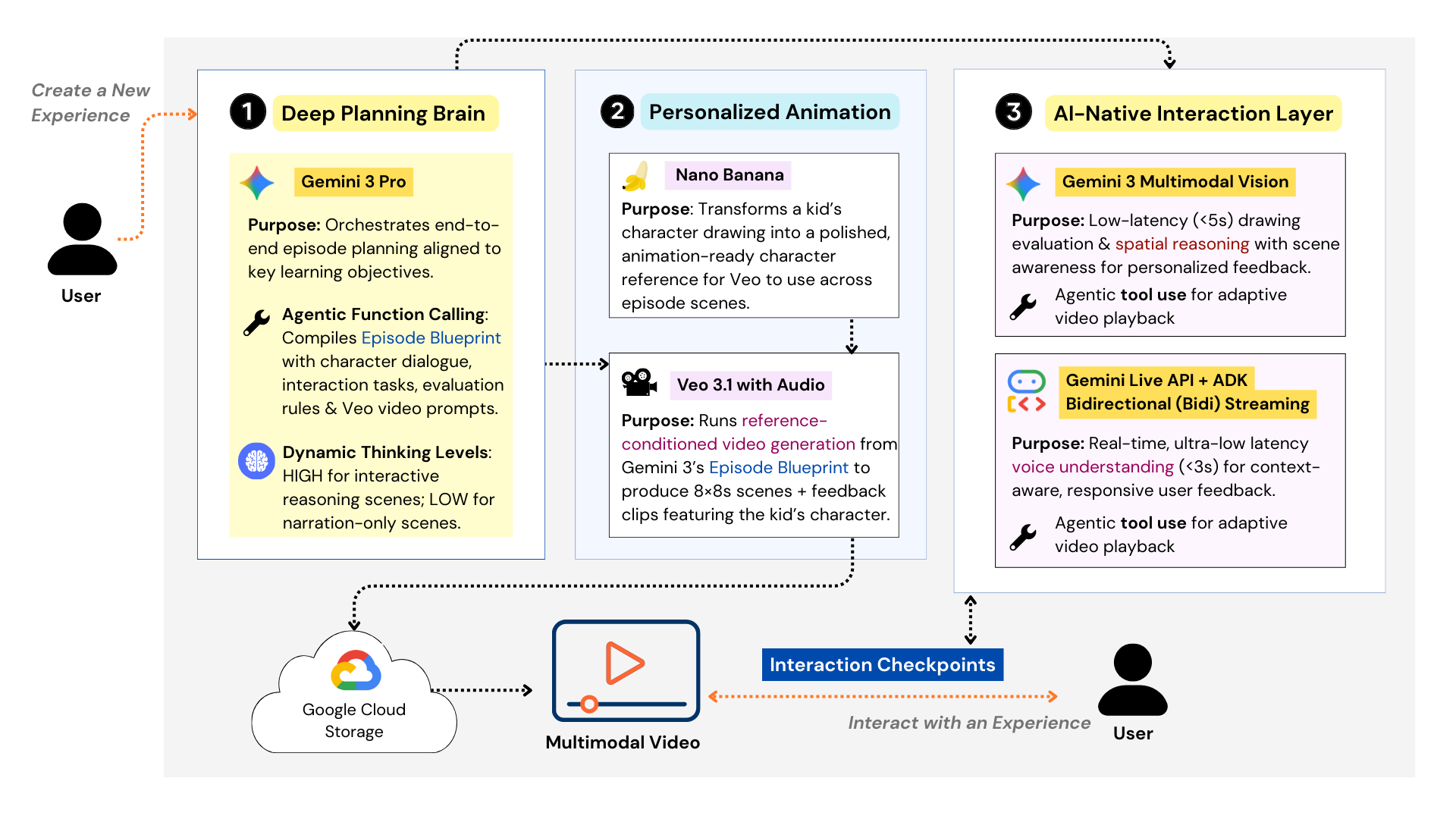
Figure 1. Key Components of Imaginable’s Generative Engine Architecture
Designing the Creative Engine around Gemini 3
The superpower behind this experience is how deeply we designed around Gemini 3’s three core strengths: Deep Thinking, Multimodal Reasoning, and Agentic Orchestration. Gemini 3 Pro serves as the creative brain of the engine. Using Deep Thinking, it generates a detailed Episode Blueprint that aligns learning objectives with story structure–scene-by-scene dialogue, Veo-ready prompts, and checkpoint tasks that prompt learners to actively engage their thinking (not passive consumption). We tuned this carefully with Gemini’s Dynamic Thinking Levels so the system can spend more compute on scenes where creativity and pedagogy matter most, and stay efficient when designing non-interactive scenes. From there, Agentic Orchestration (via function calling) coordinates the full pipeline: validating the blueprint, routing to the right tools, and enforcing safety guardrails that filter or block any inappropriate content before generation.
At runtime, Gemini 3’s Multimodal Reasoning powers the AI-Native Interaction Layer itself. A Gemini 3 Multimodal Vision–enabled agent provides Spatial Understanding to interpret what a learner draws on-screen (shape, placement, relationships, intent) and respond with targeted feedback that stays grounded in the episode context. For voice, we didn’t just “use audio understanding”–we implemented the Gemini Live API with Google’s ADK Bidirectional Streaming to make voice interactions feel instantaneous and lifelike. We successfully engineered a design that reduced interaction latency from 25+ seconds down to roughly ~3 seconds for audio and ~5 seconds for visual spatial analysis, because immersion breaks the moment feedback feels delayed. Finally, the animation pipeline brings everything to life: Nano Banana turns a child’s drawing into a character reference, and Veo generates the full episode–while the interaction layer keeps the experience responsive, personalized, and truly two-way.
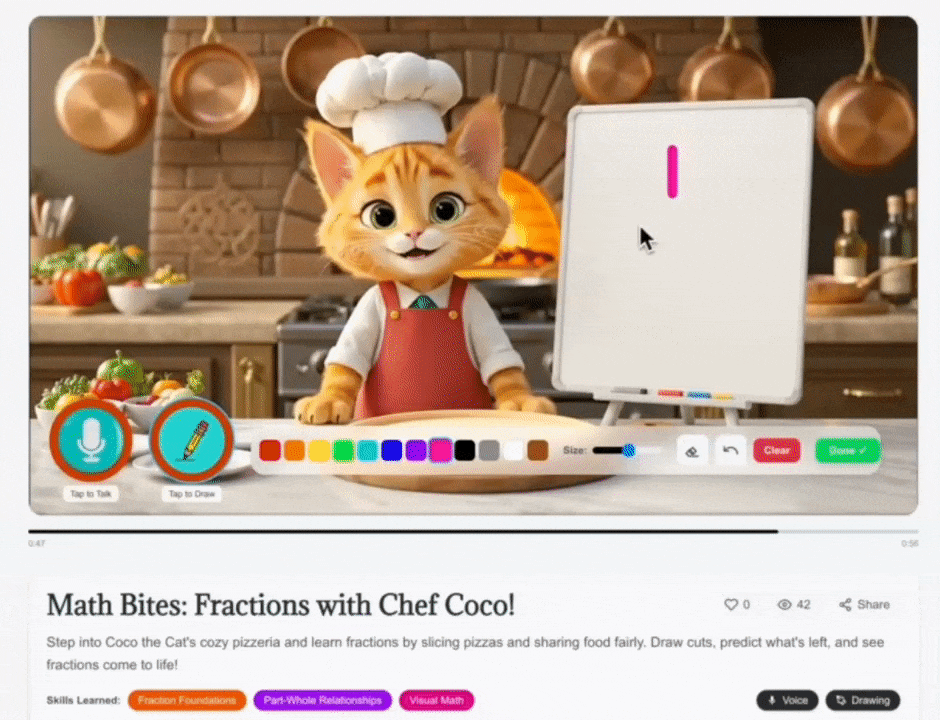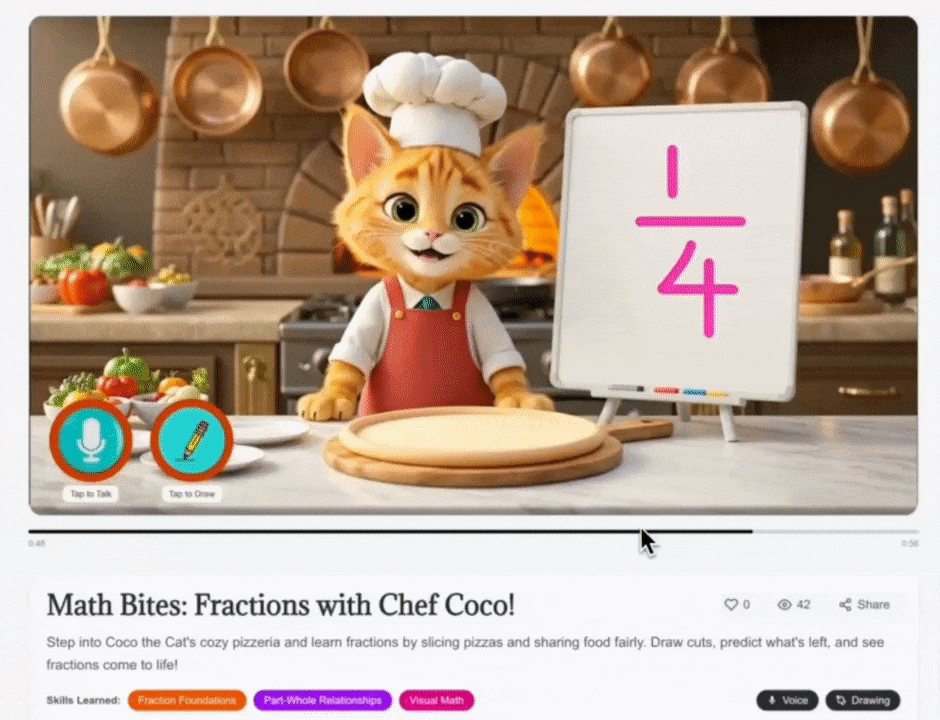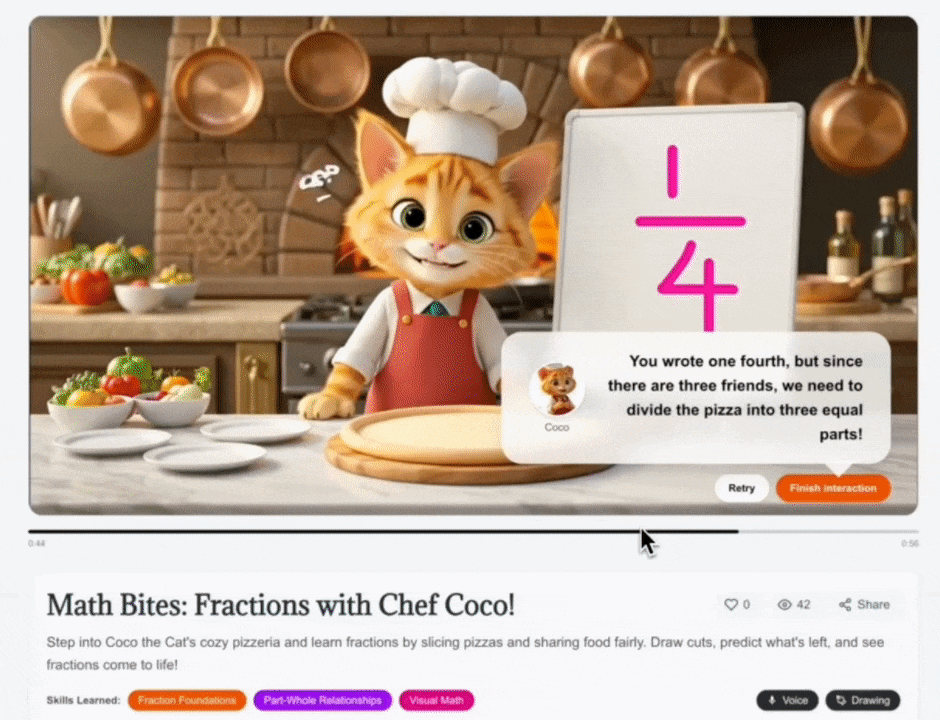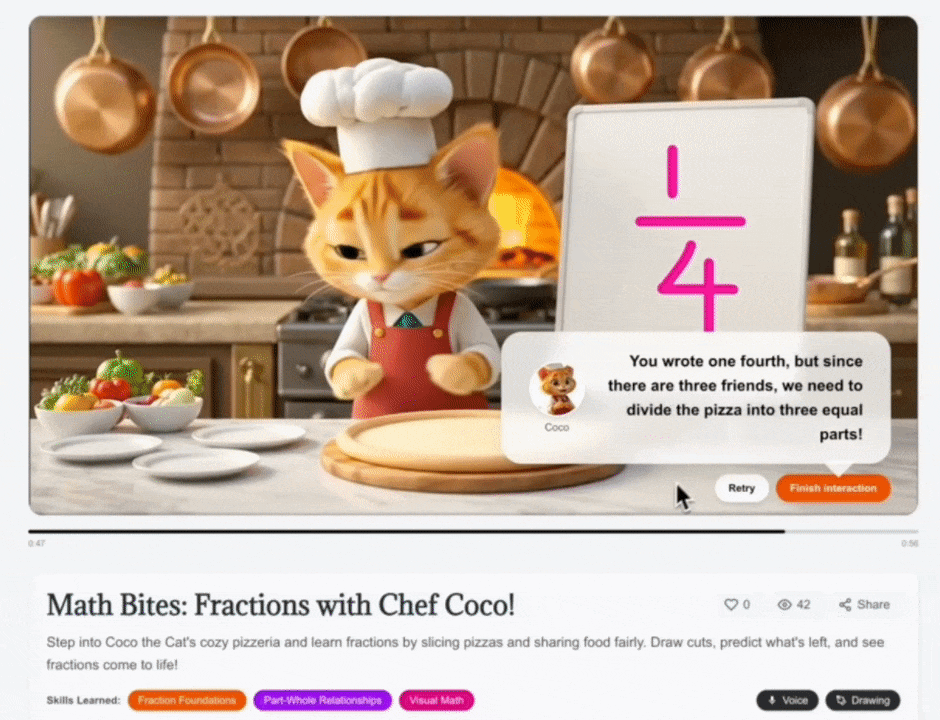
Figure 2. Real-Time Multimodal Reasoning at an Interactive Checkpoint
What we learned
Building Imaginable showed us that interactive video is a systems challenge, requiring orchestration of frontier AI models into a seamless real-time pipeline. We’re grateful to have leveraged $3,000 in Google Cloud credits to build Imaginable from the ground up and integrate state-of-the-art generation models like Veo 3.1 and Nano Banana alongside Gemini 3. A key challenge has been maintaining consistent character voices across scenes, and while we’re continuing to refine this, we’re excited by the potential for future APIs for Veo that could let developers guide voices using reference samples to strengthen continuity!
What's next for Imaginable
We believe the opportunity here is much bigger than a single prototype. The broader entertainment and edutainment industry is massive, and now that AI is truly multimodal, we can create immersive experiences that feel personal, interactive, and measurable. The same foundation that powers learning interactions can also expand into adjacent formats, including gaming and interactive entertainment, where real-time reasoning, voice, and spatial input can make experiences feel genuinely responsive.
Next, we’re focused on refining Imaginable from a prototype into a product that can reach real users widely. As we push toward real-world impact, we’re actively interested in additional cloud credit support to keep iterating on high-quality generation and low-latency interaction at scale. We’re truly excited to keep building with Gemini and the broader Google ecosystem to bring this new medium to more learners, and to explore how far fun, interactive experiences can go when they become truly two-way!
Built With
- adk-bidi-streaming
- gemini-3-flash
- gemini-3-pro
- gemini-live-api
- google-cloud
- nano-banana
- veo-3.1







Log in or sign up for Devpost to join the conversation.