-

Results 800 Training Points
-
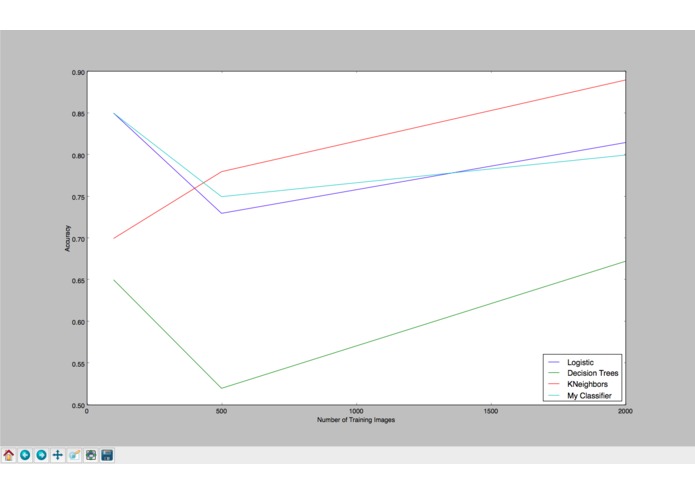
Comparison to other classifiers
-

ImageStacks 800 Training Points
-

Results 80 Training Points
-
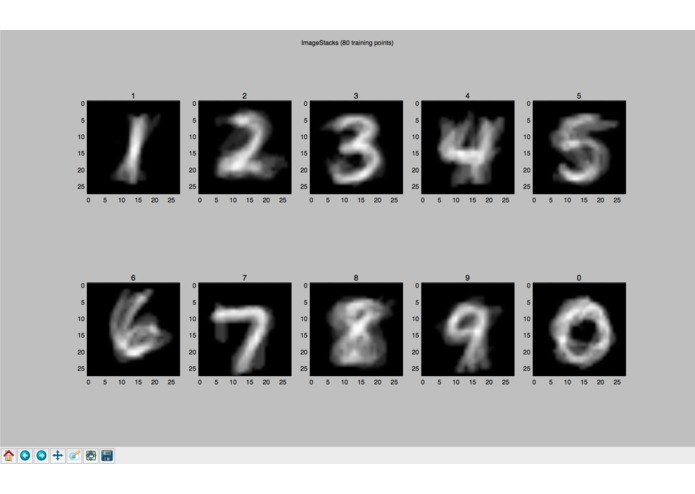
ImageStacks 80 Training Points





Inspiration
I loved the Google Tensorflow workshop. The example Yufeng went over with the Fashion MNIST dataset was incredible. When I went back to study up on tensorflow and neural nets, I realized that they are very computationally expensive and they require many samples. So I decided to play around with the MNIST digit dataset using simpler models such as LinearRegression and KNearestNeighbors. It was then that I had an epiphany (this might be an exaggeration, but it felt like one!).
Rather than taking an approach of using training data to compute parameters for a certain activation function or model, what if I turned the problem into a simple image matching problem. What if I can take an image of a digit, see how similar it is to a picture of all 10 digits, and label the image as the digit with the highest similarity? That is exactly what I did, except the set of 10 images corresponding to the 10 digits is made in an interesting way, covered in the what it does section.
What it does
The algorithm is quite simple: it classifies hand-written digits.
A more technical explanation of the algorithm is as follows: The idea the algorithm is built around is that two images that are of the same object will have similar pixels in similar areas. So if a matrix representing the a hand-written digit 1 is compared to another matrix representing a different hand-written digit 1, the differences would be minimal with respect to where the matrix has the darkest pixels and where most of the pixels are concentrated. The comparison would be different between a hand-written digit 1 to a hand-written digit 3. However, because we are dealing with hand-written digits, there is quite a lot of inconsistency between the hand-writing, so a comparison between one image of the digit 1 to another in a different hand-writing may result in a mismatch.
The approach I took is creating an image composed of layers of the same digit in different hand-writing, to create a shape that contains the general density of pixels in a matrix representing the digit. So if I compare the "ImageStack" matrix of the digit 1, it should mostly match the matrix of a hand-written digit 1 rather than the "ImageStack" of the digit 2. The algorithm creates "ImageStack"s for all 10 digits, and for each test image, compares the test against all of the digits. The test image is labeled as the digit whose "ImageStack" has the most similarity to the test image.
How I built it
I built it in various stages: beginning with the mathematical and logical foundation of the algorithm, then the translation of that into python code, and finally using special tools to display the results. I took the MNIST data from Kaggle, and used various python libraries to implement the algorithm. The first version of the algorithm is somewhere on a blackboard on the 3rd floor, but once I had established the flow of the algorithm, I began to program it. There were no API calls or servers to deploy, it simply used the NumPy and Pandas libraries to manipulate data and matrices, as well as using Matplotlib to display the results.
Challenges I ran into
A major challenge I ran into was creating the index of similarity between the matrices representing the shapes of the 10 digits and individual matrices representing test data. Initially, I had taken the difference of the matrices, then summing up the values of the resultant matrix - the lower the sum, the higher the similarity. However, I had ignored the fact that when taking the difference, I want a spatial difference, not numerical, so I had to take the element-wise square of the difference matrix before summing up the values.
Accomplishments that I'm proud of
I have barely touched the surface of what is possible within the world of Artificial Intelligence and Computer Vision. From what I had read, being able to use the algorithms within this field is not difficult - you simply have to import the library, set the parameters, and train it on the data. However, creating an algorithm was something I had thought would be in the distant future. I am very proud of the fact that I was able to create this classification algorithm, from idea to implementation, within 36 hours. However rudimentary it may be, the algorithm is competitive with the well-established algorithms. In low-sample results, i.e. the number of training data points is < 2000, my algorithm's performance exceeds that of Decision Trees and matches that of Logistic Regression.
What I learned
I learned more about matrices considering that I have not taken a course on linear algebra yet the algorithm is matrix based. I read more pdf's on linear algebra and classification algorithms than I did on python documentation, which is not something I had expected.
I also learned something a little less technical, about hackathons. I came with a preconceived notion that hackathons are these events where all you do is write code for 36 hours. But what I found was a community of developers and sponsors who are always willing to bounce off ideas. In fact, it was while talking to someone at Google that I realized the mistake I had made in the similarity index.
What's next for ImageStack Classification
The next steps are to understand whether this algorithm can be applied to different types of image data. The MNIST digit dataset was quite simple and structured as far as image data goes, so the algorithm will need to be tweaked to be applicable to more complex analysis problems. But I am excited for the potential of the algorithm. With the proper research, I believe that this algorithm can be scaled to a larger and more diverse set of problems!

Log in or sign up for Devpost to join the conversation.