-
-
Header
-
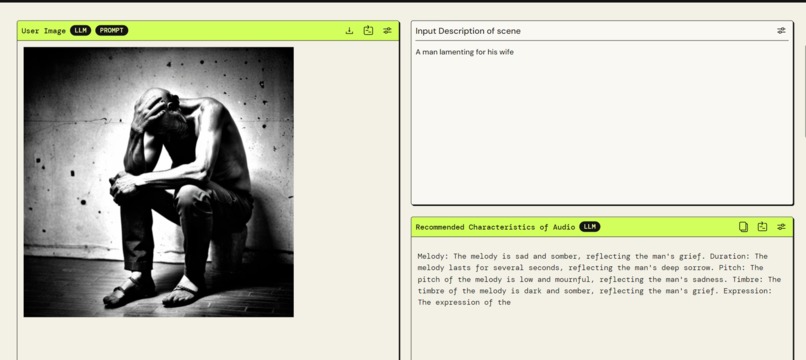
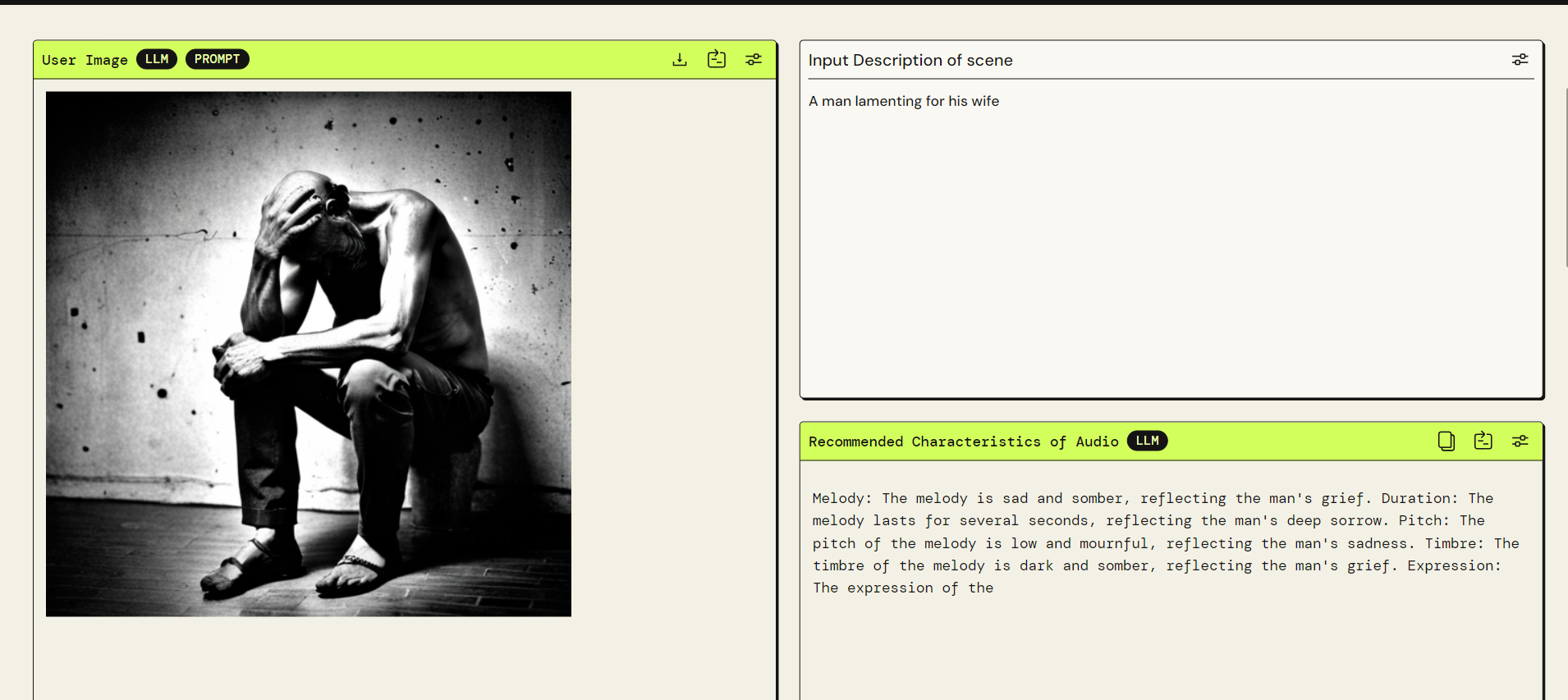
Sample
Inspiration
I am a Music lover and music composer also and contribute to that 'Natak' society in my college. So every time i get confused that which audio tuning is best according to the situation. so that's why i thought to create a ml model that will recommend me audio tunes and related audio based on situation.
What it does
This recommendation system will predict which is best music genre based on situation ship. we have to explain the situation and scenario to our model using text prompt and our model will easily suggest best music tune and audio and best singers in that genre so that you can get best idea and for betting tuning of lyrics with background music. Model will predict what are the instruments required to produce such tuning. and who are the popular singers in that genre.
How we built it
I have used No code for building this project. thanks to Amazon's 'party Rock' tool that provide best platform to develop ml model and toll that support our requirement. Even a person will with zero code knowledge like me can create a innovative generative AI models based on text prompt and learn various insight easily.
Challenges we ran into
Some of the challenges that i faced while creating this project are as follows:
- In party Rock tool user can give input only through text only.
- Model can output only text only there should be more output types like audio and video.
Accomplishments that we're proud of
We are proud to announce that we have successfully created a Situation based recommendation model based on input situation prompt of the user. Thank you to Amazon's 'party Rock' for providing amazing tools to make non-code user to visualize their ideas within minutes.
What we learned
I have learned new things while doing with this project. I have leaned some technology how ML model works and what are limitation and achievements of generative ai models. i have explored various tools and get to know more about technology stuffs.
What's next for Situation-Based-Audio-Recommender
We can enable the user to give image and audio as prompt and our model will be able to respond in form of other output channel.
Built With
- machine-learning
- no-code
- partyrock









Log in or sign up for Devpost to join the conversation.