-
-

Home
-

iSpeak
-

iListen


Inspiration
Be honest, when was the last time you read for fun? No, the book your English professor assigned you to read doesn't count. And no, the emails you read this morning don't count either. With powerful AI tools that can summarize whole books, people are reading less than ever, leading to poorer literacy skills. In fact, according to the NCES, 43 million Americans are considered to have low literacy skills. Poor literacy skills can make it harder to attain education and greatly increase the changes of unemployment, so we created iLiterate, a tool meant to improve your reading and listening skills.
What it does
iLiterate has two main features: iSpeak and iListen. iSpeak is a tool that uses the Google Gemini API to generate a sentence based on the users interests. Through speech recognition, the user will have to read the sentence out loud accurately. However, that's not all. The sentence will also have fill-in-the-blanks which users will have to fill in as they read the sentence out loud. This will not only improve their reading and speaking skills, but also their grammar skills.
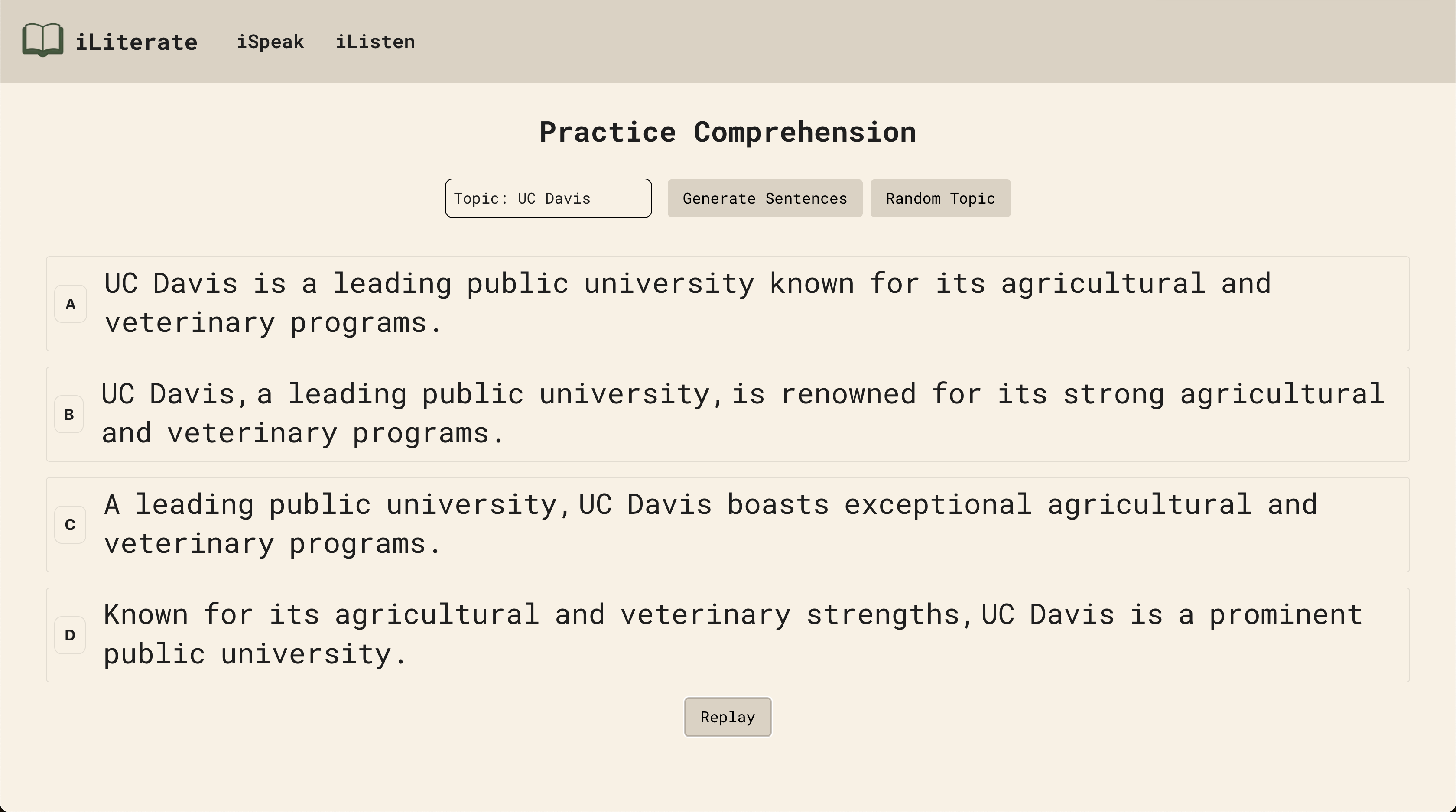
After implementing iSpeak, we realized, why stop there? Thus, iListen was born. Again, the Google Gemini API was used to generate four sentences based on the user's prompt. Using Google Cloud's Text-to-Speech API, one of these sentences is read out loud and the user must select the correct sentence that matches the audio, allowing them to improve their listening skills.
On top of these two features, iLiterate also features a learner's dictionary. When a user clicks on a word, the Google Gemini API will provides easily understandable definition for that word which is then stored in MongoDB. By storing the definitions in a database, we can minimize the API calls and reuse definitions, increasing the speed to get definitions of words. Google Cloud's Text-to-Speech API is also utilized to read the definitions out loud.
How we built it
We built this web app using Next.js on the frontend and Python and Flask on the backend. On the front end, through the use of Shadcn, a component library, we were able to easily implement clean and dynamic UI into our project. Tailwind CSS was also used to make styling the web app easy.
iSpeak was built using various APIs. First, the sentence that the user has to speak is generated using the Google Gemini API. The API returns a sentence with fill-in-the-blank options and the correct answers. As the user speaks, their words are stored in an array and compared with the sentence that the Gemini API returned. The Google Gemini API was set up in the Python and Flask backend which was then called on the frontend using axios.
iListen was built using the Google Cloud Text-to-Speech API which takes a prompt and returns a URL containing the audio file. First, sentences were generated using the Gemini API and then one of the sentences was randomly chosen to be spoken out loud using the Text-to-Speech API which the user must then select.
The dictionary was built using Google Gemini API and MongoDB Atlas. When a word is first clicked, it makes a call to the Gemini API which returns the definition. This definition is then stored in the MongoDB Atlas so that if the word is clicked again, we can get the definition from the database instead of making another API calls. This increases the speed to get the definition of a word. Again, the Text-to-Speech API was used to read out the definition of each word.
Challenges we ran into
One main challenge we ran into was prompting the Gemini API. We had to ensure that the Gemini API returned a consistent result each time which meant that we made the Gemini API return its results in JSON format. However, there were many edge cases that we had to consider where the prompt would break the response. We had to continuously fine tunes the prompts to ensure the a JSON format was always returned.
Another problem we ran into was the amount of API calls we were doing. Since we were using multiple APIs across the project, we were constantly calling APIs which was slow. So, we implemented MongoDB to store the word definitions to reduce the amount of API calls we had to make, increase the speed of the application.
Another challenge we ran into was ensuring that the application was friendly for users who struggle with reading. This is why we decided to implement definitions with text-to-speech to help readers who struggle.
Accomplishments that we're proud of
We're proud that we were successfully able to incorporate various technologies and APIs into our project. A lot of the technology that we used was unfamiliar to us at first and using them seemed daunting. However, we were able to get past our challenges and incorporate all the technology into a working product.
We are also proud that we were able to implement two features: iSpeak and iListen. At first, the plan was just to implement iSpeak. However, through teamwork, we were able to develop faster than we expected which allowed us to also make iListen.
What we learned
We learned how to use various technologies and APIs including Gemini API and MongoDB Atlas. We learned how to work simultaneously on a project as a team. This includes learning how to split up a project into components to make it easy to work individually while also learning how to handle merge conflicts and more.
What's next for iLiterate
In order to support incremental learning, we want to implement difficulty options so that as a user gets better, they can choose a harder difficulty. Implemented user profiles so that users can view past sentences that they read would also help them with reviewing. Lastly, we implemented iSpeak and iListen, but why stop there? There are many other features that we can add to help users improve their reading, writing, and listening skills. This includes features like iWrite which could test users ability to write.
Built With
- flask
- gemini
- javascript
- mongodb
- next.js
- python
- shadcn
- speechrecognition
- tailwind
- text-to-speech

Log in or sign up for Devpost to join the conversation.