-
-

Website Interface
-
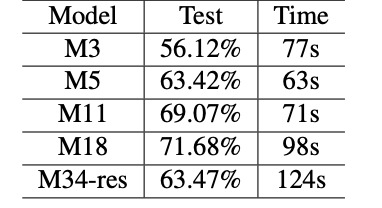
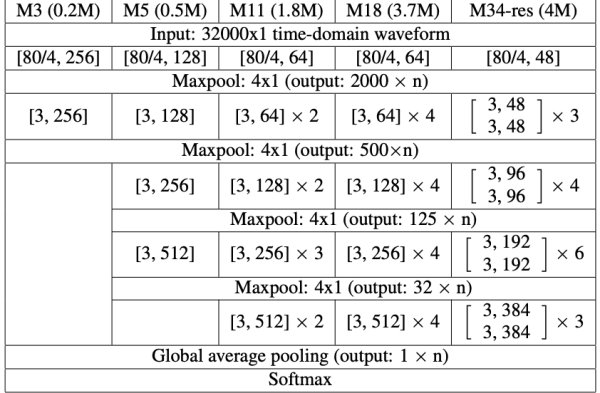
Model Architecture
-
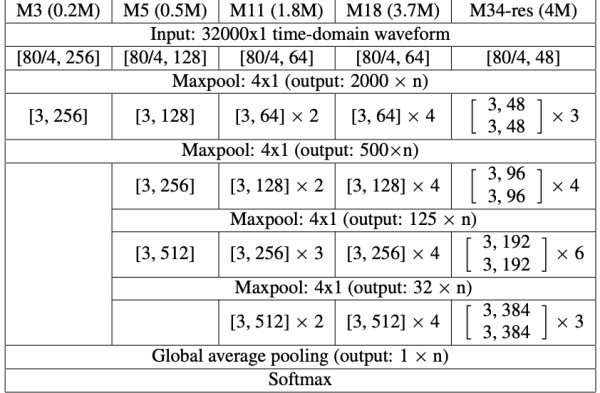
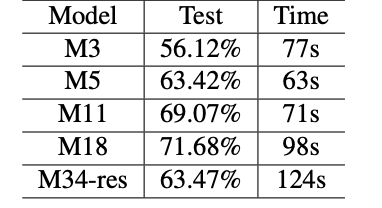
Various Model Training Times and Accuracy found in the Aformentioned Paper (link above)
-
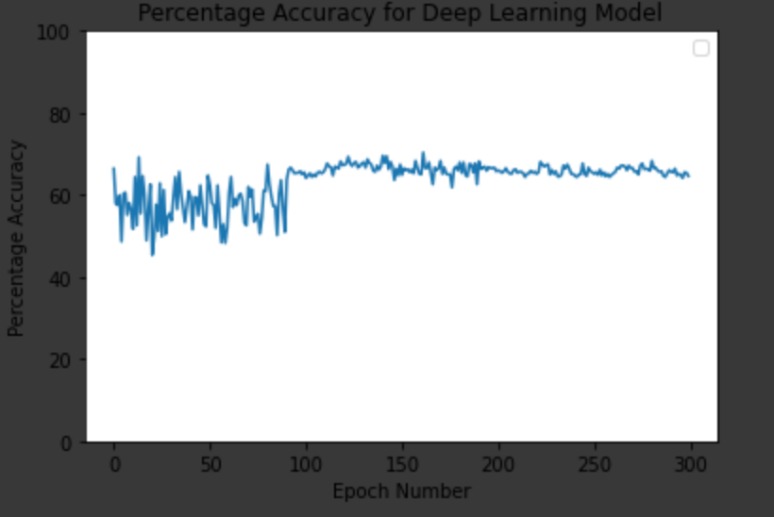
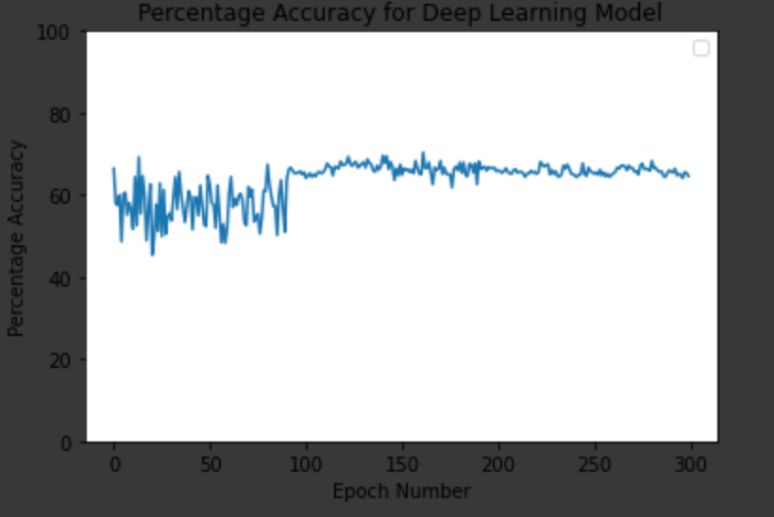
Our CNN's Accuracy over Training Epochs

Inspiration
Imagine a world without sound - no noise, no music, no sound. An entire sense of stimulus completely deleted. Even a simple walk through a busy street, one with speeding cars, barking dogs, and blaring street music, could be confusing and potentially dangerous.
This is exactly what the close family member of one of our teammates experiences on a daily basis. With very limited hearing, even the most mundane situations can become landmines.
Thus, it became our team’s goal to create an application that could be used for both ambient sound detection and speech detection in the midst of growing urban environments. With the ability to toggle between modes, the app could be used to both identify common signals and hazards through the ambient-sound-detection mode and facilitate communication through the speech-to-text conversion mode.
What it does
iHeard has two modules that the user can choose between: one that converts speech to text and one that can categorize ambient sounds.
If the user chooses to convert speech to text, they can record someone speaking for as long as necessary. The Google Cloud API then outputs text for the user to read on the right side of the page, allowing them to effectively “hear” the other person’s dialogue. The app supports 4 languages: English, Spanish, Mandarin Chinese, and Hindi and can automatically detect which language is being spoken, outputting text accordingly.
However, if the user would like to identify ambient sounds, they can record a 4-second sound byte, which - after being processed by a deep layered network (a convolutional neural network) - categorizes the sound-byte into one of ten categories, namely: air conditioner, children playing, dog bark, engine idling, gun shot, jackhammer, siren, or street music. Although not perfect, we believed these categories provide an approximate representation of the important sounds that a user might hear in an urban environment.
Note: The dataset (Urban Sounds Dataset) we trained our model only featured the aforementioned ten labels that were selected by the data creators from a taxonomy delineating sounds in the the urban acoustic environment
How we built it
Our project had two main portions: the frontend, which consisted of the website itself, and the backend, which consisted of the flask. We wrote the frontend in Javascript and used React to connect it to the backend. The backend included both the Google Cloud Console and the multi-layered convolutional neural network. In the Google Cloud Console, we used Python to integrate the Google Cloud Speech-to-Text API into our program so our app could transcribe actual audio input into text. For the deep learning network, we used an M11 deep network architecture as prescribed in this paper: https://arxiv.org/pdf/1610.00087.pdf and implemented the architecture in pytorch. This deep network features 11 different convolutional layers which together analyze and describe wav files. Although the authors credited their work as achieving an accuracy of 69.07%, we were only able to reach a final test accuracy of 65%. The exact model code is shown in the pictures. We believe this is due to the different set of hyperparameters we had to use in order to allow the authors’ ideas to extend to our specific needs. Additionally, since the wav files we received were of too great length to store in the GPU, we also had to implement our own sampling methods in order to reduce the input vector to a sizable length. Together, the sampling methods and the deep network allow us to effectively identify ambient sounds in the user’s surrounding environment.
Challenges we ran into
-Choosing model for convolutional neural network architecture: with very little data on raw sound processing methods, we struggled to find a suitable way to process sound. The sklearn library (which we were most familiar with) was unable to process the heavy arrays generated by the wav files. -Getting the voice recorder to work so that it can input actual user audio through the web application (asking for access to microphone, etc.) -Getting the API to recognize files with different sample rates, number of channels, and multi-languages -Setting up projects in Google Cloud Console to incorporate specific Google Cloud APIs
Accomplishments that we're proud of
Reflecting on the work we did with Google Cloud Storage and the Google Cloud Speech-toText API, we successfully implemented a program—which is compatible with at least four different languages—that inputs actual user audio input and outputs a relatively accurate output. Incorporating this code into the rest of the backend Flask of the program and connecting it to the React frontend to display speech-to-text translation on our app was another big milestone for our team. Finally, we were able to tie the entire project together once we integrated the machine learning element of the project in order to classify ambient sounds in a users background. After spending hours training and testing data using our machine learning neural network, incorporating this code into our actual application was the last major step towards our initial finished product. Additionally, while our model wasn’t perfect, we were able to have a 65% success rate in processing our test data as shown in the pictures.
What we learned
We learned how to incorporate Google Cloud APIs into our project and gained good experience creating a project using Google Cloud Console. We learned how to train and test a machine learning neural network on a dataset of sound samples after coding a model for the CNN architecture ourselves. We also developed our technical skills with Flask and React. Beyond technical skills, we learned to communicate and work virtually with team members in different time zones. We were able to responsibly delegate different roles within our team, completing our work in a more efficient manner.
What's next for iHeard
Ideally, we would aim to deploy the app on a wearable device like Google Glass or a Smartphone, but with limited technology resources, we decided to simply create a web application that displays the algorithms in play. Other updates we would most like to include in future versions of iHeard include:
- Integrating the two modules so that it can recognize speech and ambient sounds simultaneously
- Increasing the amount of labels that the machine learning model can recognize
- Expanding language recognition
- Making text more accurate and grammatically-correct using grammar-correcting APIs
- Adding translation features, using the google cloud translation api, for users who are visiting foreign locations and are unable to understand specified languages
Built With
- amazon-web-services
- convolutional-neural-network
- flask
- google-cloud
- google-cloud-speech-to-text-api
- google-colab
- javascript
- juptyer-notebook
- machine-learning
- python
- pytorch
- react





Log in or sign up for Devpost to join the conversation.