-
-
Supply-line trace
-
PDF generation
-
Main dashboard
-
ElevenLabs integration
-
Inspiration
Modern slavery and forced labor are massive, hidden problems — the ILO estimates 27.6 million people are in forced labor globally, much of it embedded in the supply chains behind everyday consumer goods. Yet the people best positioned to do something about it (NGO investigators, compliance officers at brands, journalists, advocacy groups) spend days doing the same first-pass research over and over: crawling Google News, cross-referencing the UFLPA Entity List and OFAC SDN, searching CourtListener, hunting through ILO NORMLEX, then trying to assemble it into a credible, cited brief.
We wanted to compress that initial investigation from a week to five minutes — without ever sacrificing the citation trail that makes the output usable in a complaint letter or compliance escalation.
What it does
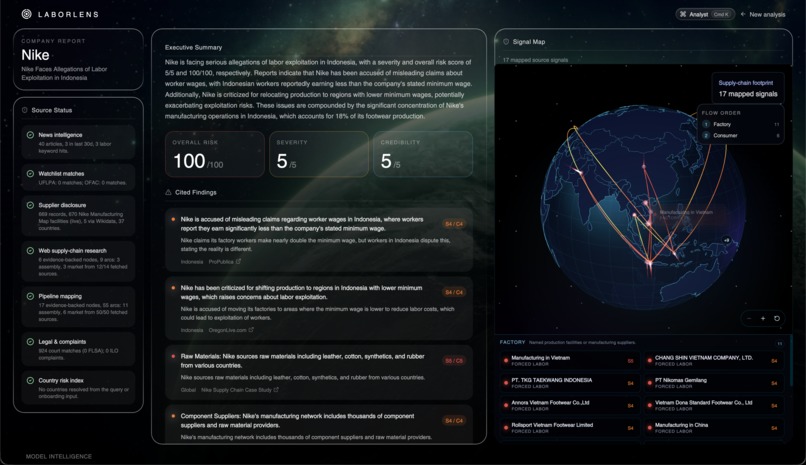
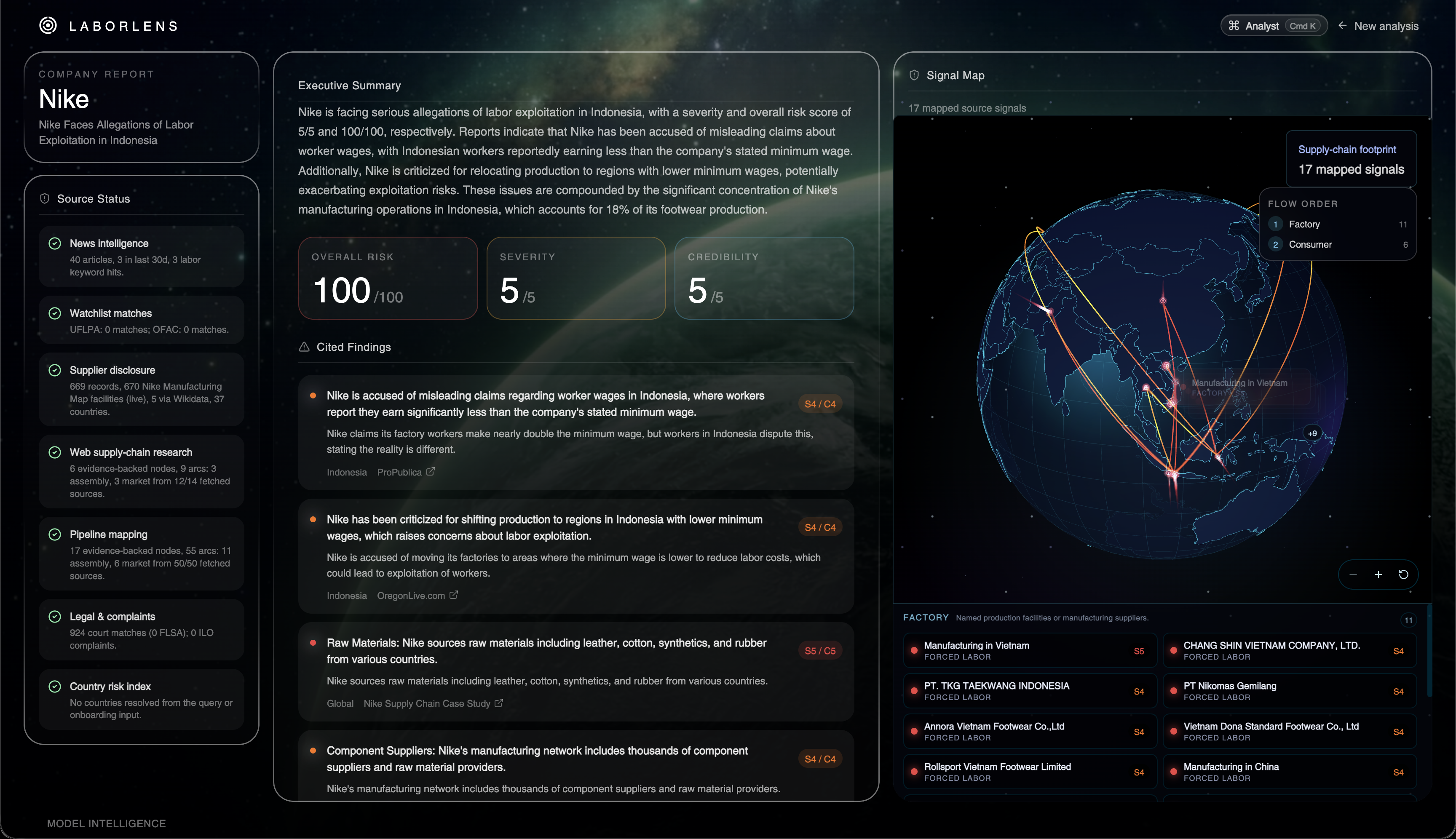
LaborLens collapses the first week of a labor-exploitation investigation into the first five minutes. You land on a single input — type a company (Nike, Shein, H&M) or a region (Xinjiang, Dhaka, Yangon) — hit Analyse, and seven specialist agents fan out in parallel across news, watchlists, supplier disclosures, web research, court filings, ILO complaints, and country-risk indices. While they work, a 3D globe spins on the launch screen and pins drop in real time as evidence is discovered, so you can see the investigation happen instead of staring at a spinner.
When the swarm finishes, the same globe carries forward into a full dashboard:
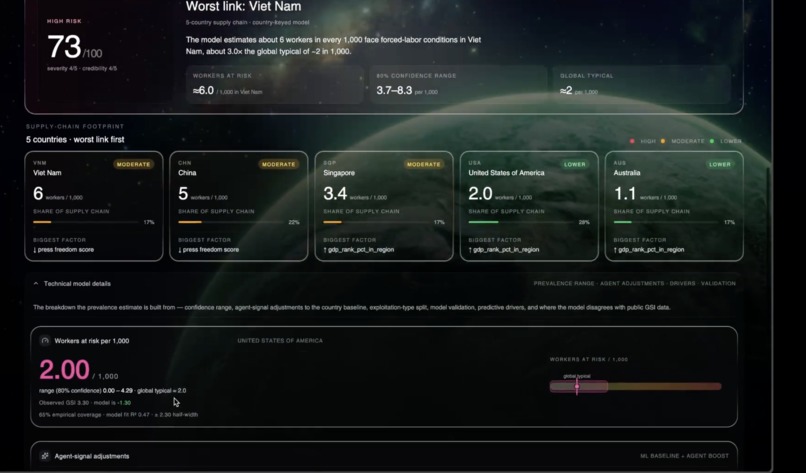
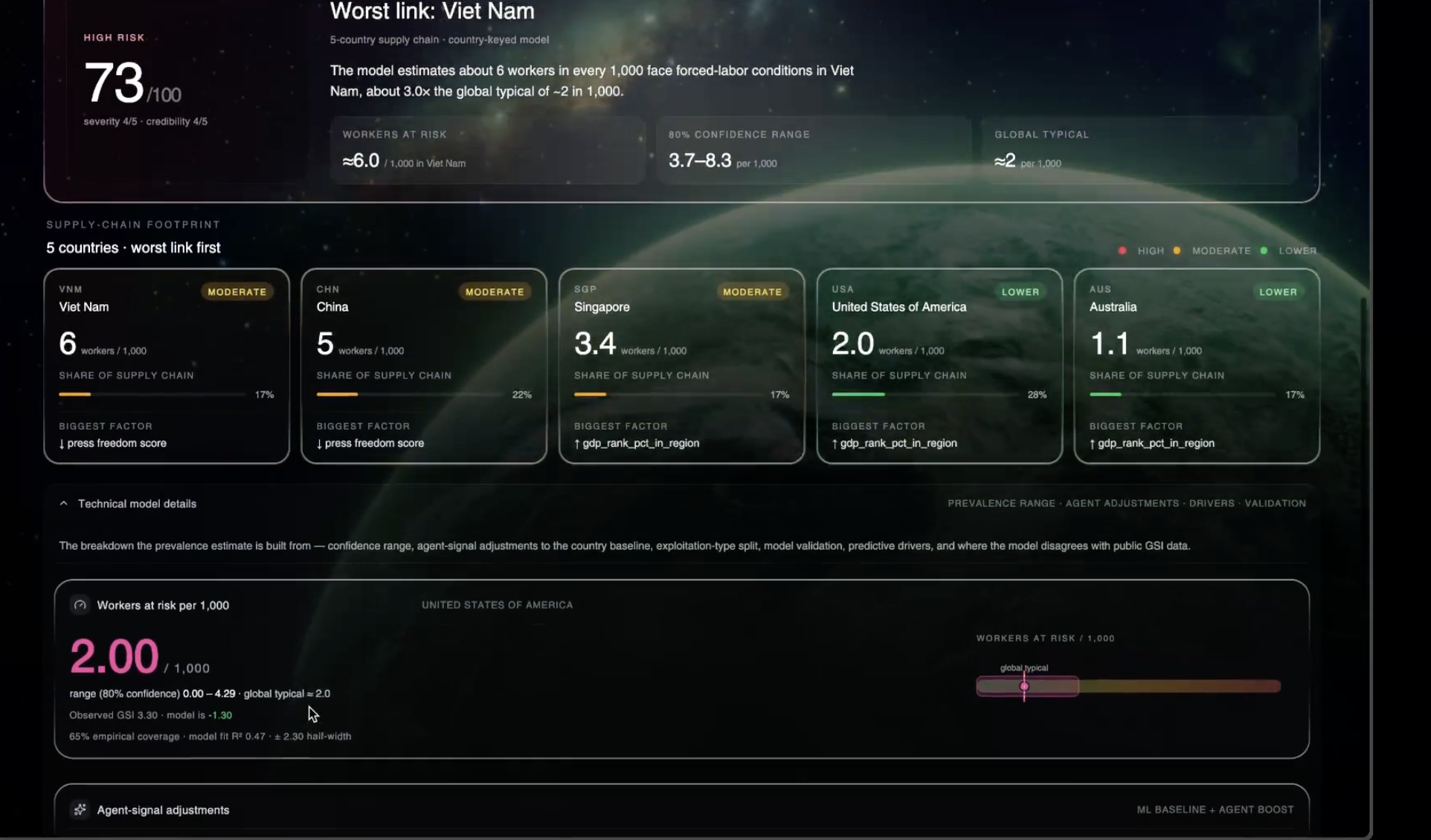
- Three headline scores — overall risk (0–100), severity (0–5), credibility (0–5) — each one ML-baselined against GSI × WDI × RSF data, then nudged up or down by corroborated agent signals (UFLPA hits, OFAC matches, court cases, ILO complaints, news volume), with hard floors so a watchlist hit can never be buried.
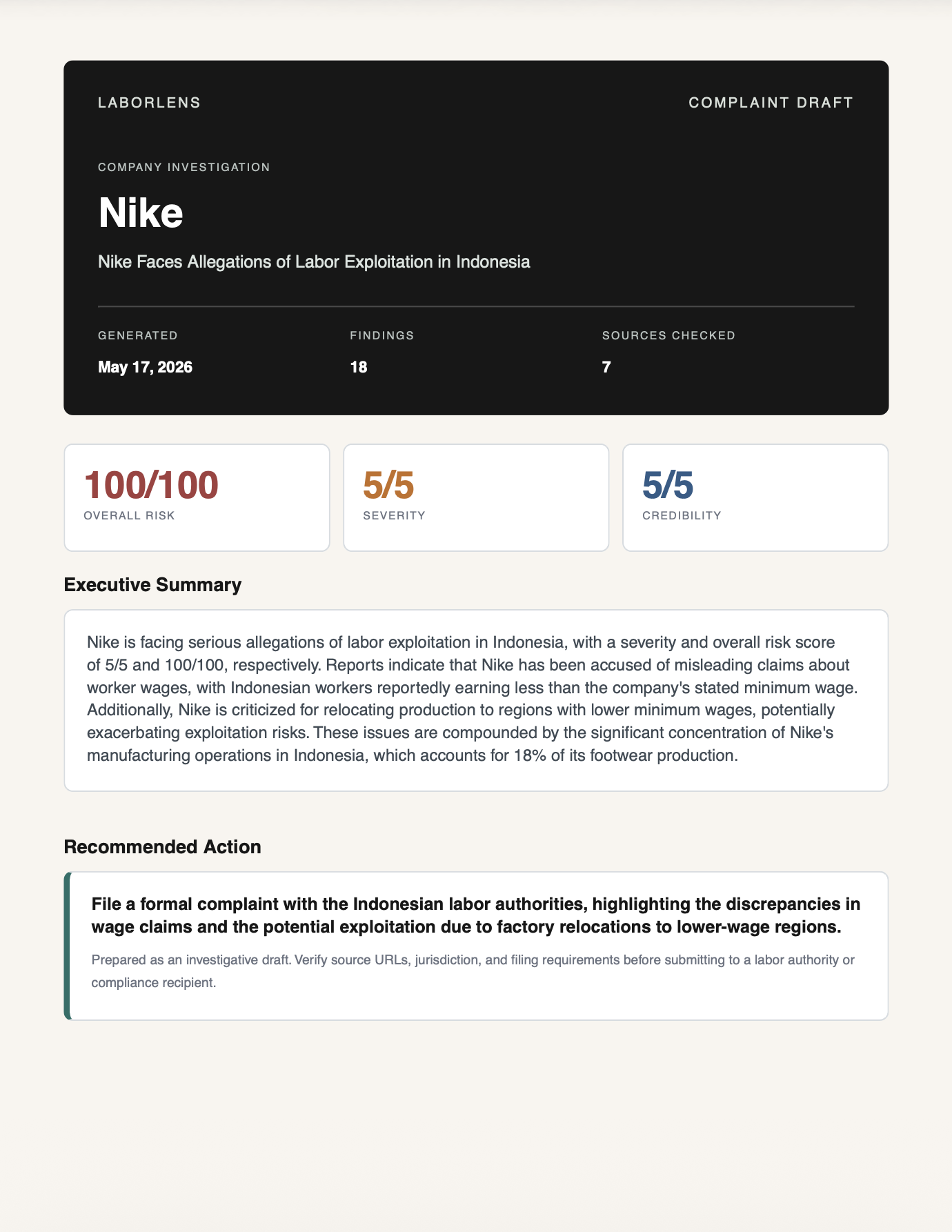
- An executive summary with a recommended next action (e.g. "File a formal complaint with Indonesian labor authorities highlighting wage-claim discrepancies").
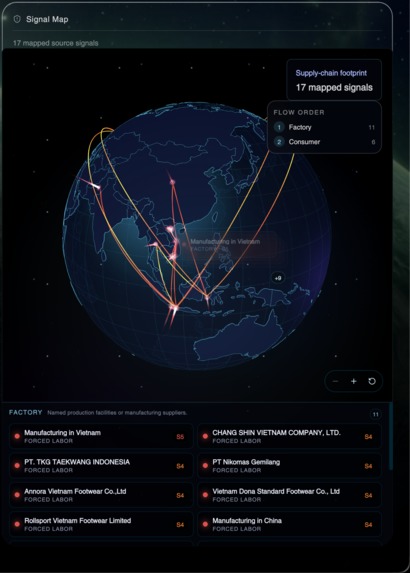
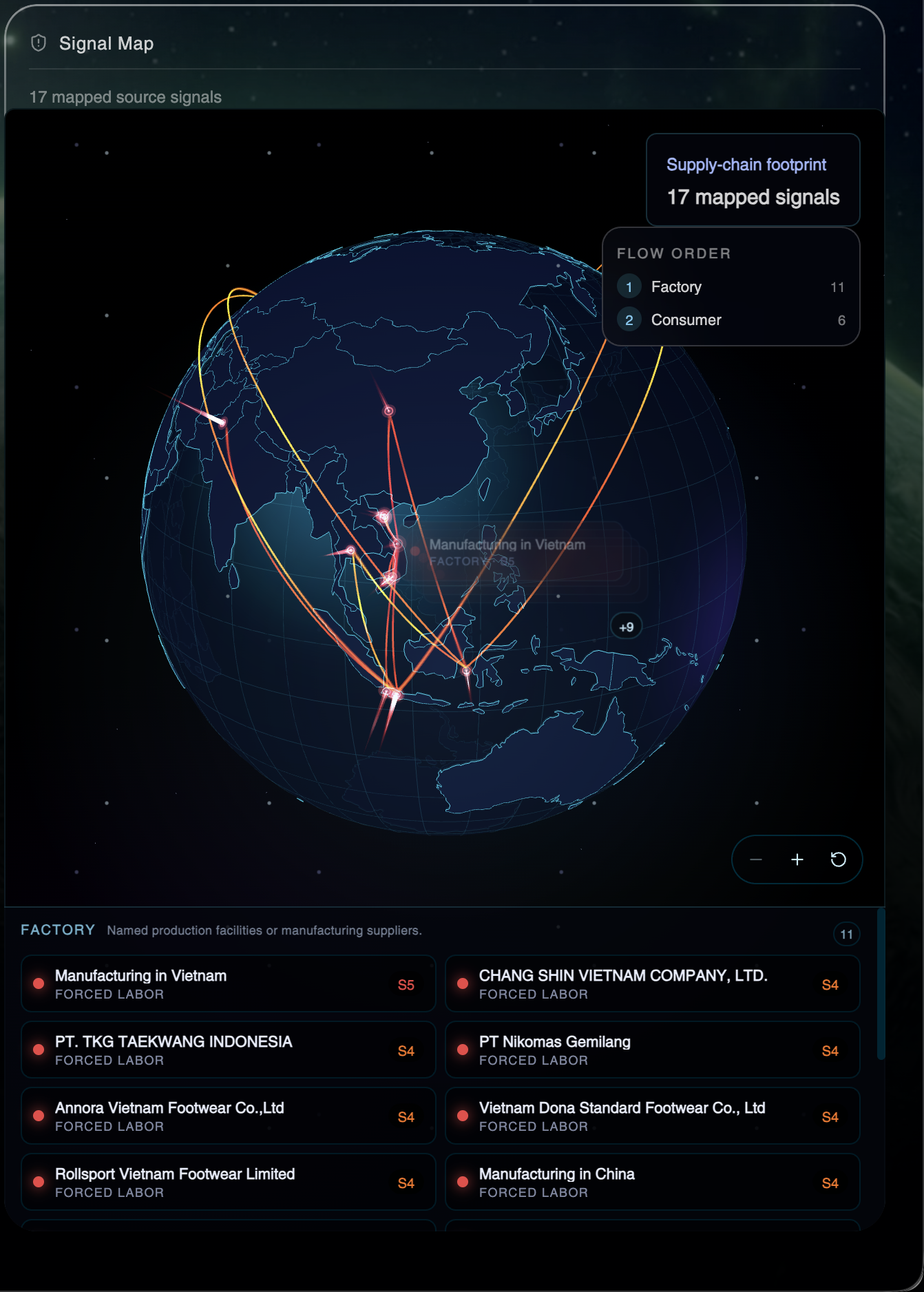
- A Signal Map — the interactive supply-chain globe with animated factory→consumer arcs, severity-colored pins, and a flow-ordered list of every named facility the agents surfaced (e.g. PT. TKG Taekwang Indonesia, Chang Shin Vietnam, Annora Vietnam Footwear), each tagged with its exploit type and severity.
- Cited findings — every claim links back to the source document it came from, so the brief is usable in a complaint letter the moment it's generated.
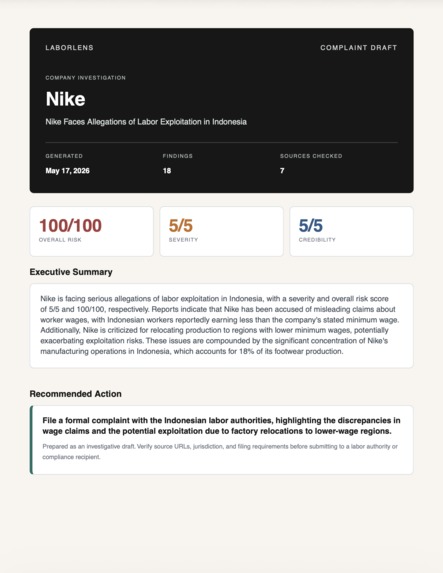
- A one-click complaint draft PDF — pre-filled with the company name, headline allegations, the three scores, sources-checked count, and a recommended filing action, ready to verify and send to the relevant labor authority or compliance recipient.
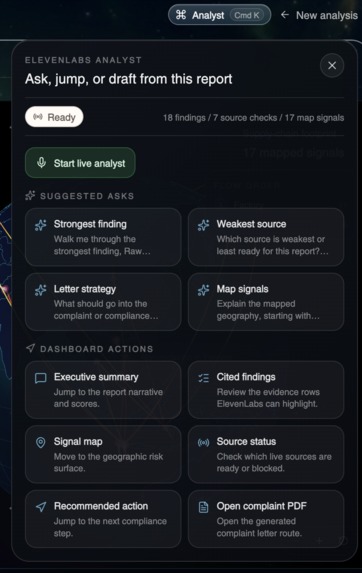
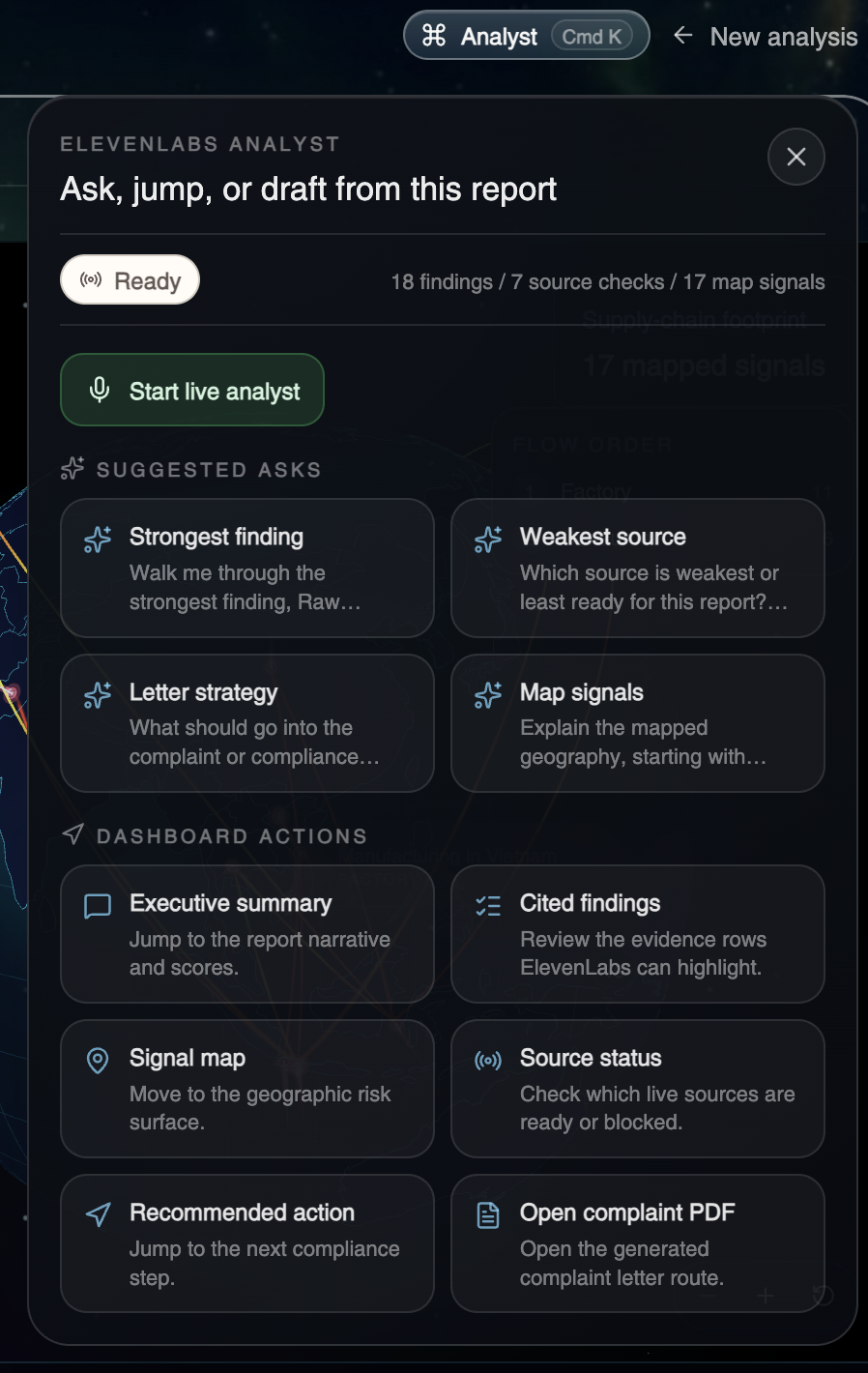
- A live voice analyst (Cmd+K) — an ElevenLabs Conversational AI session that has the entire report in its context. Ask "walk me through the strongest finding," "which source is weakest," or "what should go into the complaint letter," and the agent answers hands-free while also driving the dashboard for you — highlighting evidence rows, focusing map pins, jumping between sections, and opening the complaint PDF — through native client-side tool calls.
The intended users are NGO investigators, brand compliance officers, procurement and ESG teams, advocacy groups, journalists, and academics — anyone whose job currently starts with the same week of Google News and CourtListener slog.
How we built it
LaborLens is a full-stack TypeScript + Python system: a Next.js 16.2.6 (App Router) + React 19.2.4 frontend, a LangGraph agent orchestrator running server-side, a Python ML pipeline (scikit-learn) called via subprocess bridge, and Supabase/Postgres for persistence. The full stack:
Frontend & 3D visualization. Next.js 16 App Router with Tailwind v4, motion v12 (Framer Motion successor) for transitions, Three.js v0.184 + @react-three/fiber v9.6 + @react-three/drei v10.7 for the interactive globe (WorldGlobe component) that powers both the loading/launch screen at /swarm/[id] and the report dashboard at /dashboard. Using one globe across both surfaces means the user's mental model doesn't reset when the report arrives — the same planet that was spinning while agents searched now lights up with the evidence they found. The globe renders Natural Earth 110m country polygons (GeoJSON in public/data/) with pan/zoom controls, animated supply-chain arcs (great-circle interpolation), risk pins colored by severity bucket, and a WebGL→Canvas fallback so the experience still works on GPU-less machines. PDFs are generated client-side with @react-pdf/renderer v4.5. All API I/O is validated with Zod v4.4 schemas. The landing page itself is intentionally minimal — one input, one toggle between company and region — because the whole point is to compress the time-to-first-evidence, not gate it behind an intake form.
Agent orchestration — LangGraph. The heart is a 12-node directed graph defined in src/agents/orchestrator.ts:
START → ingest → news, watchlist, web_research, legal, risk_index
↓ news → supplier
[watchlist, supplier, web_research, legal, risk_index] → enrich_countries
↓
pipeline → synthesize → persist → END
Seven specialist agents, each a tool-wrapping LangGraph node:
| Agent | Source | Method |
|---|---|---|
news |
Google News RSS (+ optional GDELT) | RSS fetch → Cheerio parse → bounded cache |
watchlist |
DHS UFLPA Entity List + OFAC SDN | HTML/CSV scrape with embedded fallback rows |
supplier |
Wikidata SPARQL + curated registry | SPARQL corporate-footprint query |
web_research |
No-key public web search | Bounded fetch + Cheerio extraction |
legal |
CourtListener REST API + ILO NORMLEX snapshot | Token-optional API |
risk_index |
Global Slavery Index 2023 (Walk Free) | Local JSON lookup |
pipeline |
Composes evidence-backed supply chain graph | LLM-assisted, schema-bounded |
Every agent uses OpenAI structured output — ChatOpenAI.withStructuredOutput(schema, { mode: "json_schema" }) — bound to Zod schemas (findingsEnvelopeSchema, narrativeSchema, supplyChainGraphSchema) so extraction is deterministic and parseable. We use gpt-4o-mini at temperature=0.1 for extraction and gpt-4o at temperature=0.2 for synthesis.
Real-time UI streaming. /api/reports/stream is a Server-Sent Events endpoint that pushes per-agent state transitions (pending → running → ready/snapshot/blocked), map-point discoveries, and incremental synthesis scores. The launch-screen globe subscribes to it — discovered map points drop onto the planet in real time as agents find them, and a scan label tracks the most recently focused location. When the synthesize node persists, the page auto-redirects to /dashboard?id=… and the same globe carries the assembled report.
ML synthesis bridge. The synthesize node calls src/agents/ml/predict-bridge.ts, which shells out to ml/pipelines/predict.py via stdin/stdout JSON. The Python pipeline contains:
- Geographic model — A bagged ensemble (GradientBoostingRegressor + Ridge, n_estimators averaged) trained on 153 countries from GSI 2023 (Walk Free) × WDI 2021 (World Bank) × RSF 2021 Press Freedom Index.
- Exploit-type breakdown —
forced_labor,sexual_exploitation,children,illegal_profitsproportions are taken from the ILO Global Estimates 2022 (global priors, explicitly labeled as such in the output rather than pretending to be per-country learned). - Cluster model — KMeans (k=3 chosen by silhouette = 0.282) over demographic + economic features for the "similar countries" UI grouping.
If the bridge fails for any reason, the synthesize node degrades to a deterministic localScoring() heuristic so the report still ships.
Scoring math. The final severity and credibility scores blend the ML baseline with agent-derived signals using log-dampened weights: severity_raw = 0.60 · sign(|UFLPA_hits|) + 0.30 · sign(|OFAC_hits|) + 0.35 · log₁₀(1 + court_cases) + (court_cases ≥ 3 ? 0.20 : 0) + 0.15 · log₁₀(1 + min(news_articles, 100)) + 0.20 · log₁₀(1 + ILO_complaints)
credibility_raw = 0.40 · log₁₀(1 + court_cases + ILO_complaints + min(news, 50))
Then we apply a corroboration cap: a single weak signal can only nudge the ML baseline by ±1; ≥2 independent signal classes (e.g. UFLPA + courts + news) lifts the cap to ±2. We also enforce hard watchlist floors — a UFLPA hit forces severity ≥ 4 and overall_risk ≥ 75; an OFAC hit forces severity ≥ 3. These guardrails are why the system doesn't drift into either over-claiming or under-claiming when the evidence picture is lopsided.
Persistence. Supabase/Postgres with cascading tables — reports → findings → citations, plus map_points, map_arcs, source_status, report_ml_prediction, feature_bundles. Migrations live in supabase/migrations/. The report dashboard reads either from Supabase or from a demo fixture controlled by DEMO_MODE.
Testing. Playwright E2E suite (tests/exploited.spec.ts) covering web research query generation, supply-chain graph composer fan-in/fan-out invariants, landing-page demo failover, fixture loading, PDF generation, and ElevenLabs analyst UI controls including the 403/503 signed-URL failure paths.
ElevenLabs Integration
We chose ElevenLabs' Conversational AI (the real-time WebSocket agent), not just TTS, because the value isn't reading the report aloud — it's letting an investigator interrogate the report hands-free while their eyes stay on the globe and citations.
The architecture (three files):
src/components/elevenlabs-report-agent.tsx— React panel, mounted on the dashboard, gated by Cmd+Ksrc/app/api/voice/signed-url/route.ts— server-side proxy that exchanges ourELEVENLABS_API_KEY(HTTP Basic) for a short-lived signed WebSocket URL againsthttps://api.elevenlabs.io/v1/convai/conversation/get-signed-url?agent_id=...src/lib/runtime-config.ts— env validation (ELEVENLABS_API_KEY,ELEVENLABS_AGENT_ID)
Dynamic variables are passed at signed-URL creation time — report_id, query, title, mode (demo / supabase / swarm) — so the same ElevenLabs agent can serve any report in our system without per-report agent provisioning.
Contextual update on connect. As soon as the WebSocket is live, we call conversation.sendContextualUpdate(context) with the full report payload — every finding (with stable IDs), every map point (with pointId, lat/long, exploit_type, severity), source statuses, and the three risk scores. The agent's system prompt is configured to reference these IDs when calling client tools.
Client tools — this is the part we're most proud of. We register four native browser-side tools that the ElevenLabs agent can call mid-conversation. This means the ElevenLabs Conversational AI agent that has full context of every finding can highlight specific evidence rows, focus map points, jump between dashboard sections, and open the generated complaint letter.
highlightFinding(findingId: string) // scroll + flash a cited evidence row
focusMapPoint(pointId: string) // recenter the globe + open the pin
scrollToDashboardSection(section: 'summary'|'map'|'sources'|'findings'|'action')
openComplaintLetter() // open /api/reports/[id]/complaint.pdf
Challenges we ran into:
The globe. Rendering 110m-resolution Natural Earth polygons in Three.js is the easy part; making the arcs feel like supply chains was the fight. Great-circle interpolation alone looks flat — we needed altitude-curved Bézier paths, severity-graded color ramps that read at a glance, fade-in animations synced to agent discovery events, and a clustering rule (+9 badge) so a globe with 17 signals didn't turn into spaghetti. Then we had to ship a WebGL→Canvas fallback so the experience still works on GPU-less laptops, and make the same globe component drive both the live launch screen and the static report dashboard without re-mounting.
Training the ML model on data that actually generalizes. Stitching GSI 2023 (Walk Free), WDI 2021 (World Bank), and RSF 2021 (Press Freedom Index) into a 153-country feature bundle took longer than the modeling itself. We tried a single regressor first; it overfit to whichever index dominated. The bagged ensemble (GradientBoosting + Ridge) was the smallest change that gave us stable predictions across continents. We also had to make peace with using ILO Global Estimates 2022 as a global prior for exploit-type breakdown — and labeling it as such in the output — instead of pretending the model had learned per-country proportions it never could from 153 rows.
Not being a GPT wrapper. The single biggest engineering principle was: every score has to be defensible, every claim has to cite, every agent has to read from a real source. That meant building 7 distinct scrapers and API integrations (UFLPA, OFAC, Wikidata SPARQL, CourtListener, ILO NORMLEX, Google News RSS, GSI), wiring every LLM call through Zod-schema structured output so extraction is deterministic, and designing the corroboration-cap math so the LLM cannot hallucinate a severity score past what the evidence supports. The "no GPT wrapper" rule is what makes the brief usable in a complaint letter; it's also what made the build genuinely hard.
Coordination, honestly. With a small team under a hackathon clock, the most expensive mistakes weren't technical — they were the hours we lost before we'd agreed on what the frontend should even look like.
Accomplishments that we're proud of
The globe. Not just because it looks good — because it's the same component on the launch screen and the dashboard. The planet that's spinning while agents search is the planet that lights up with the evidence they find. The user's mental model never resets. We've seen demos where people leaned in the moment the first pin dropped, and that's the whole pitch in one frame.
That we're actually compressing investigation time. A first-pass labor-rights brief that would have taken an NGO researcher a week — crawling Google News, cross-referencing UFLPA and OFAC, hunting through CourtListener and ILO NORMLEX, assembling cited bullets — comes out of LaborLens in roughly five minutes, with every claim linked back to its source. That's not a UX flourish; it's a tool that could meaningfully shift how much investigative capacity an under-resourced NGO has on a given week.
The breadth. There is no curated whitelist of companies LaborLens can analyse. Type any company, in any sector, and the agent swarm goes to work. We're not surfacing a hand-picked database — we're running a real investigation, on demand, on whatever you point at it.
Shedding light on something that hides on purpose. Forced labor exists in supply chains because it's expensive to find. Anything that lowers the cost of finding it — even a hackathon project — is on the right side of the problem.
What we learned
Almost every major consumer brand has documented labor violations somewhere in its supply chain. Not "questionable practices" — actual cited cases, UFLPA-listed suppliers, court filings, ILO complaints. Once you build the tooling to surface them in five minutes, you stop being surprised and start being grim.
Every node on the globe is its own investigation. A single pin — PT. TKG Taekwang Indonesia, say — can have years of reporting, multiple court cases, named workers, named cities, specific wage-theft mechanics. LaborLens makes those nodes legible at a glance, but the real investigation begins where our report ends. That reframed how we thought about the product: we're not the destination, we're the on-ramp.
Lock the design and roles down on hour one. The team-coordination cost of disagreeing about the frontend on hour twelve is worse than any technical mistake we made. Next hackathon: design system, role assignments, and a written "what is the user looking at when this is done" — before anyone opens a code editor.
Structured output beat every other LLM-wrangling trick we tried. Zod schemas + withStructuredOutput({ mode: "json_schema" }) got us deterministic, parseable findings on the first call, every time. Prompt engineering for JSON shapes is dead — there's no reason to do it anymore.
The corroboration cap is the most important math in the system. A single weak signal can nudge the ML baseline by ±1; two independent signal classes raise the cap to ±2; UFLPA and OFAC hits set hard floors. Without it, the system either over-claims (one news article → severity 5) or under-claims (the ML thinks Norway is fine, ignores the watchlist match). The guardrails are the product.
What's next for LaborLens
A platform, not a report generator. The report is step one. What we want to build next is the rest of the workflow that currently lives in spreadsheets and email threads:
- Investigation case files — save reports, annotate findings, attach correspondence, track which nodes have been escalated.
- Send-a-letter integration — turn the complaint PDF into a real outbound: addressed to the right labor authority by jurisdiction, with delivery receipts, and follow-up scheduling. The "Recommended Action" tile becomes a button, not a suggestion.
- A workspace for compliance teams and NGOs — shared cases, role-based access, audit trails, so an investigation can move from one analyst to another without losing the citation chain.
- Watch lists for companies and regions — re-run a report automatically when a new UFLPA addition, OFAC designation, court filing, or major news event matches a saved query. Page the investigator before the news cycle does.
- Per-node deep-dives — every factory pin gets its own investigation surface: workers named in court records, wage-theft patterns, parent-company links, related facilities. Each node already is its own investigation; we just need to give it its own page.
- Sector and supplier graph exploration — surface shared suppliers across brands ("which other apparel companies also source from this facility?"), so a single discovery propagates outward into the rest of the industry.
- API + browser extension — a journalist or procurement analyst should be able to hover over a supplier name on any retailer page and see the LaborLens summary inline.
- Partnerships — pilot with Walk Free, ILO, or a brand's compliance team to harden the data pipeline against real-world evidentiary standards.
Built With
- css
- elevenlabs
- eslint
- google-news-rss
- langchain
- langgraph
- lucide
- motion
- next.js
- node.js
- numpy
- openai
- pandas
- postcss
- postgresql
- python
- react
- react-pdf
- react-three-fiber
- scikit-learn
- sql
- supabase
- tailwindcss
- three.js
- typescript
- webgl
- websockets
- zod

Log in or sign up for Devpost to join the conversation.