-
-
Landing Page
-
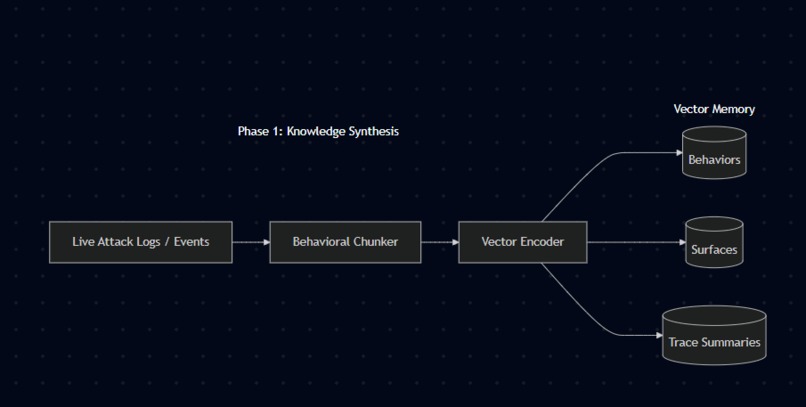
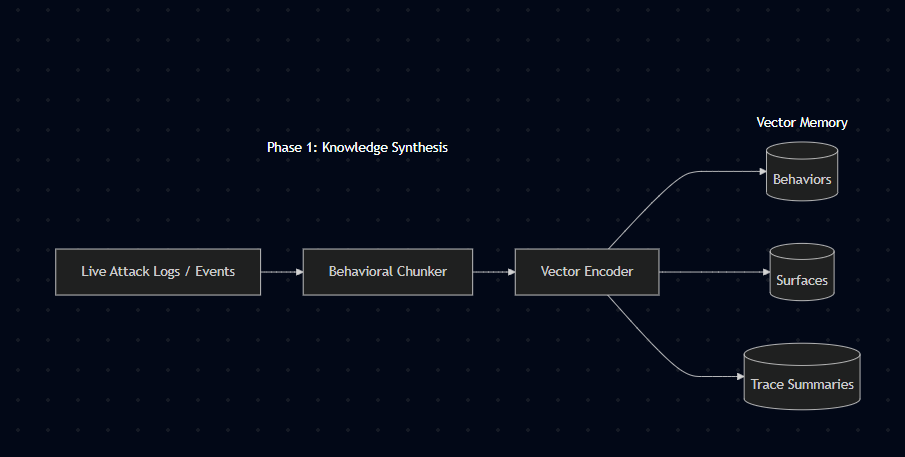
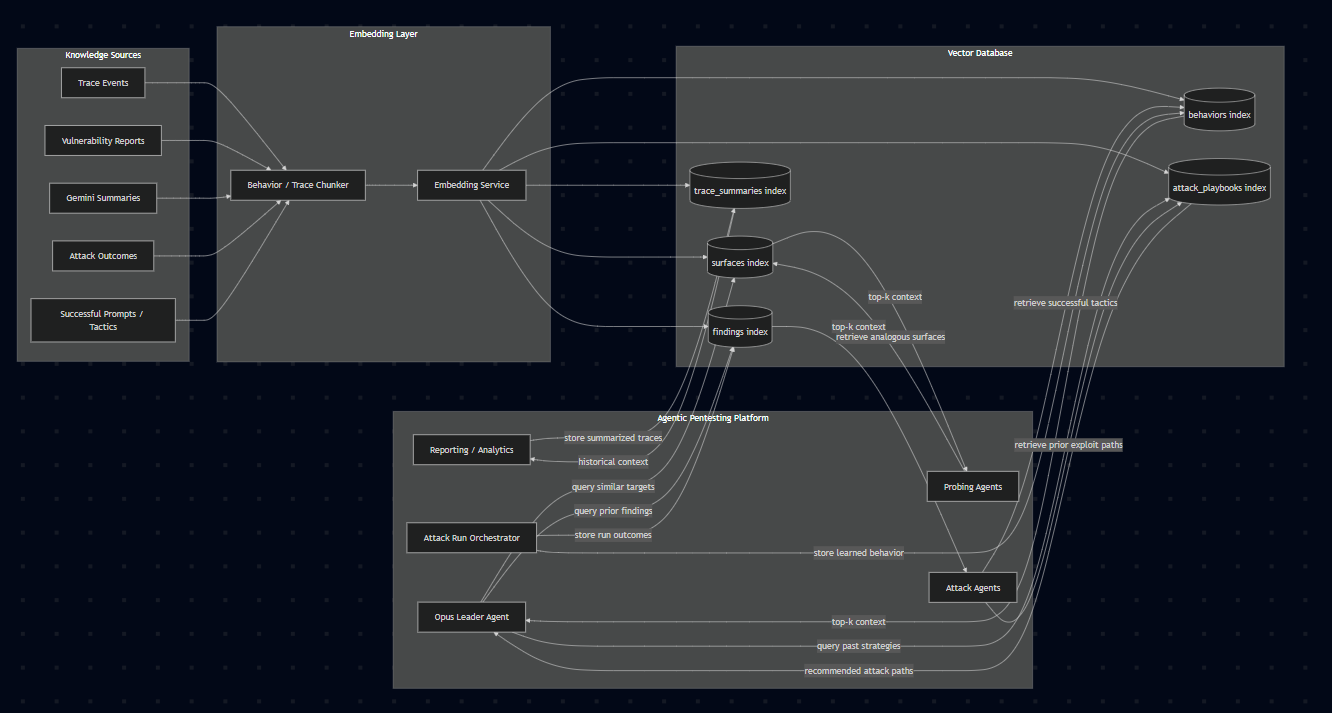
Knowledge Synthesis Architecture
-
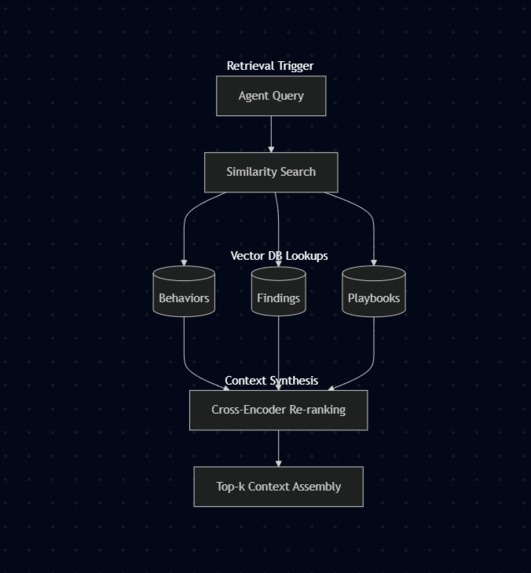
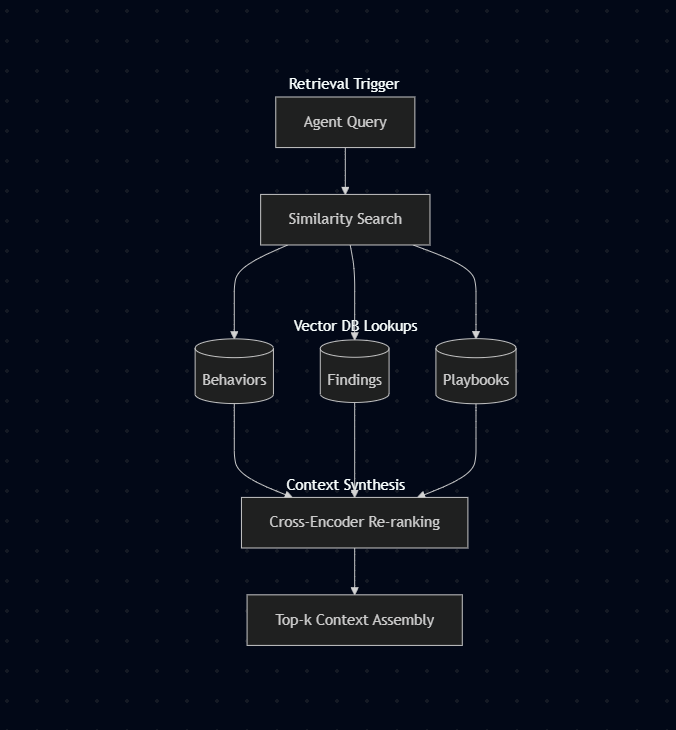
Revival Trigger Architecture
-
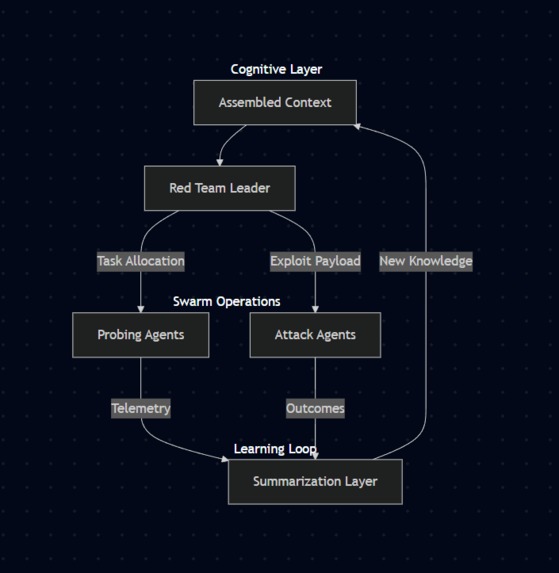
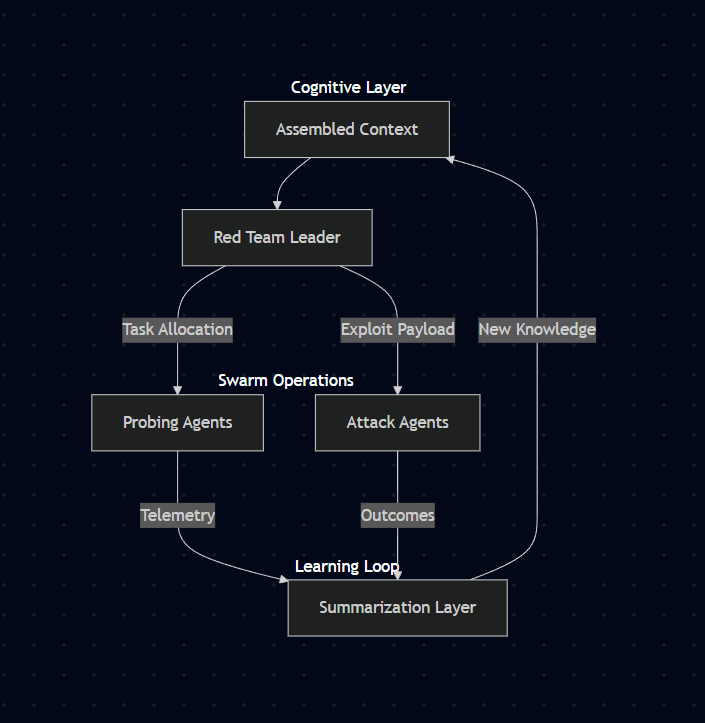
Cognitive Layer Architecture
-
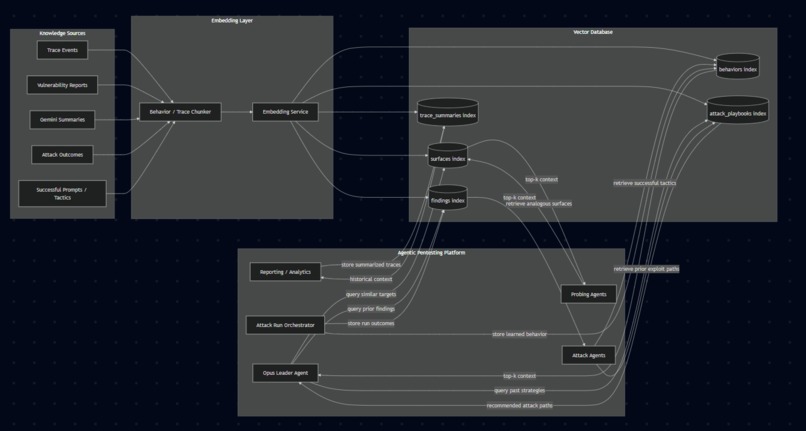
AI Knowledge & Agentic Workflow Architecture
Inspiration
Penetra was built because legacy pentests and scanners were too static. We wanted a system that acts like a real red team: probing, planning, and exploiting continuously, with actual proof of attack paths and repeatable outcomes. The idea was to remove the gap between automated vulnerability discovery and attacker-style exploitation.
What it does
Penetra executes a complete autonomous attack workflow:
- User clicks Start new attack
- System spins up an isolated sandbox for the target web app
- A Claude Opus leader agent ingests the target context and system prompt
NSonnet probing agents dynamically map exposed surfaces (search bars, embedded agents, prompt inputs, integrations, APIs)
NOTE: We actually have a process of finding out the amount of agents our platform should deploy! Our system deploys one attack agent for each chosen attack path, and attack paths are created from the surfaces discovered during probing.
In mathematical terms:
N_attack = number of selected attack opportunities
S* = the set of surfaces the leader decides are worth attacking
V(s) = the set of attack vectors chosen for surface s
Then: $$ N_{\text{attack}} = \sum_{s \in S^*} \left| V(s) \right| $$
- The leader uses Metasploit and other real security tooling as a toolbox
- A swarm of attack agents targets vectors like prompt injection, SSRF, auth bypass, and data exfiltration across any surface it can find
- Every action is wrapped in Laminar observe and streamed to a live React/Next.js dashboard
- Gemini generates live natural-language summaries for each trace stream
- Post-attack, the system produces a report with verified vulnerabilities, risk scores, summaries, and step-by-step reproduction instructions
How we built it
Penetra is structured as a layered offensive engine:
- Python backend for agent orchestration, sandbox lifecycle, and trace aggregation
- Claude Opus as the leader brain and Sonnet as probing/attack workers
- Metasploit and cybersecurity packages integrated into the agent decision graph
- Laminar observe wrapping every trace event for high-fidelity telemetry
- MongoDB-driven reinforcement learning layer that leverages vector-embedded agent tracing to autonomously tune agent policies based on historical attack data
- Supabase for user authentication and session management
- React/Next.js frontend with websocket-based live graph rendering and clickable trace sidebars
- Gemini API for generating live natural-language summaries of agent trace logs
We also model attack scoring and agent selection with explicit formulas:
1) $$ \text{Risk}(s_i) = \alpha\,\text{Exploitability}(s_i) + \beta\,\text{Impact}(s_i) + \gamma\,\text{Exposure}(s_i) $$
This is a weighted linear risk scoring model. It computes the base risk score of an attack surface by combining how easy it is to exploit, how damaging it would be, and how exposed it is. It’s used to prioritize which discovered surfaces the system should care about most.
2) $$ U(a_j, s_i) = \lambda\,\text{SuccessProb}(a_j, s_i) + \mu\,\text{Impact}(s_i) - \nu\,\text{DetectionCost}(a_j, s_i) $$
This is the utility score for assigning agent a_j to surface s_i. It’s used to decide which agent/vector pairing is most worthwhile by balancing likelihood of success and impact against the cost of being detected
3) $$ v = \mathrm{enc}!\left(s_t, a_t, r_t, s_{t+1}\right) $$
This is a state-action-reward-next-state transition encoding (AKA a SASA tuple encoding). It encodes a full attack transition: current state, chosen action, reward, and next state. It’s used to store attack experiences in the vector database so future agents can retrieve similar successful patterns.
4) $$ r_t = w_{\text{success}} \cdot \mathbf{1}{\text{exploit}} + w{\text{stealth}} \cdot (1 - \text{detection}) + w_{\text{value}} \cdot \text{dataValue} $$
This is the reward function. It defines the reward the agent gets from an action based on whether exploitation succeeded, how stealthy it was, and how valuable the resulting data/access was. It’s used to score agent actions during learning and strategy adaptation.
5) $$ Q(s_t, a_t) \leftarrow Q(s_t, a_t) + \eta \Bigl( r_t + \gamma \max_{a'} Q(s_{t+1}, a') - Q(s_t, a_t) \Bigr) $$
This is the Q-learning update rule for improving the system’s estimate of how good an action is in a given state. It’s used to help the platform learn better attack decisions over time from past runs.
6) $$ R = 100 \cdot \frac{\text{Risk}(s_i)}{\max_j \text{Risk}(s_j)} $$
This is used as max-scaled normalization. It normalizes a surface’s raw risk score onto a 0-100 scale relative to the riskiest surface in the run. It’s used to present clean, comparable risk scores in the dashboard and final report.
Challenges we ran into
- Coordinating asynchronous leader and swarm state without losing trace fidelity
- Converting arbitrary web surface data into structured attack targets
- Integrating Metasploit into an AI-managed workflow while keeping sandbox isolation intact
- Maintaining low-latency UI updates during bursty agent activity
- Making reports reproducible rather than noisy
- Ensuring sandbox safety and automatic cleanup after every run
Accomplishments that we're proud of
- Built a genuine agentic red team engine, not just another scanner
- Delivered dynamic surface discovery and attack planning
- Integrated real offensive tooling into AI-driven exploitation
- Created live attack graph visualization with trace inspection
- Produced proof-backed vulnerability reports with replication guidance
- Implemented explicit reinforcement learning over the vector database already, so the system learns from its own attack outcomes
What we learned
- Autonomous offense is about orchestration, not just models
- Attack surface mapping must be dynamic and context-aware
- Observable instrumentation is essential for trust
- Reproducible attack proof is more valuable than raw issue count
- Self-learning works best when experience is encoded as vectors and replayed to improve policy decisions
What’s next for Penetra
- Add GitHub Actions integration for commit-triggered live attack scenarios
- Add post-fix verification to validate remediation automatically
- Improve report collaboration, export formats, and analyst workflows











Log in or sign up for Devpost to join the conversation.