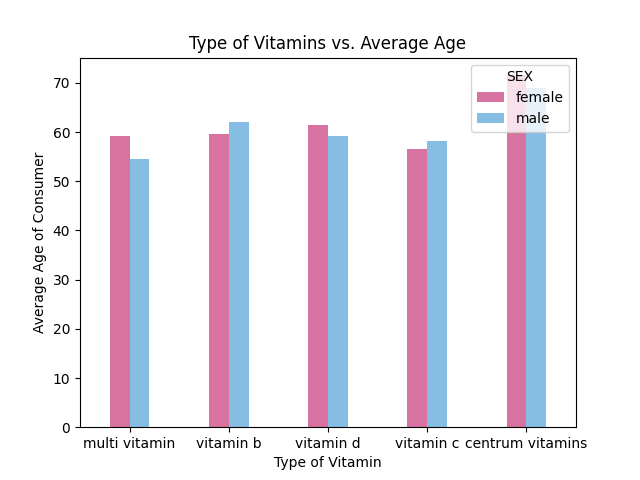
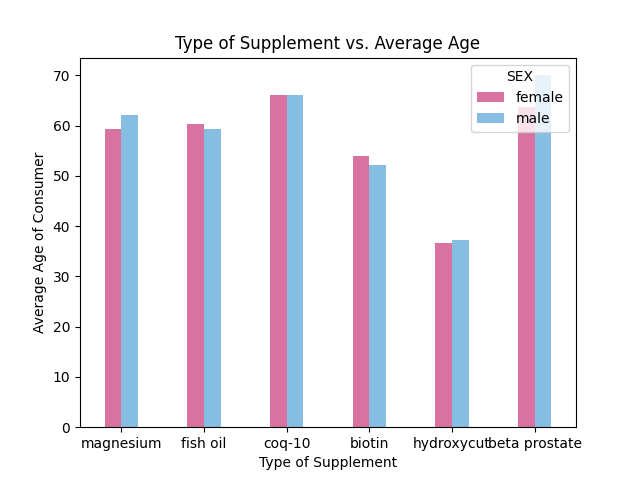
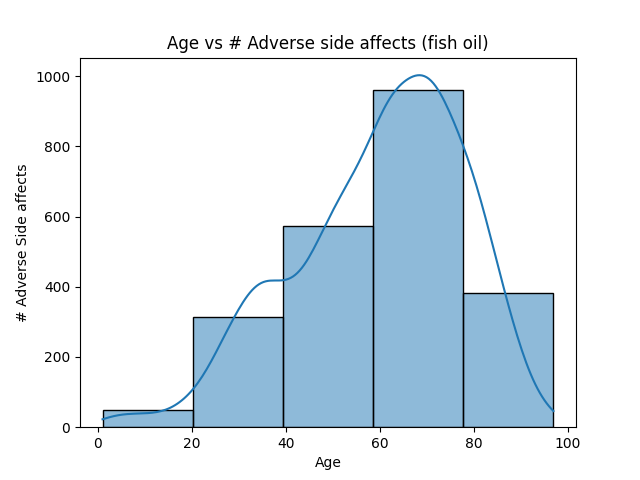
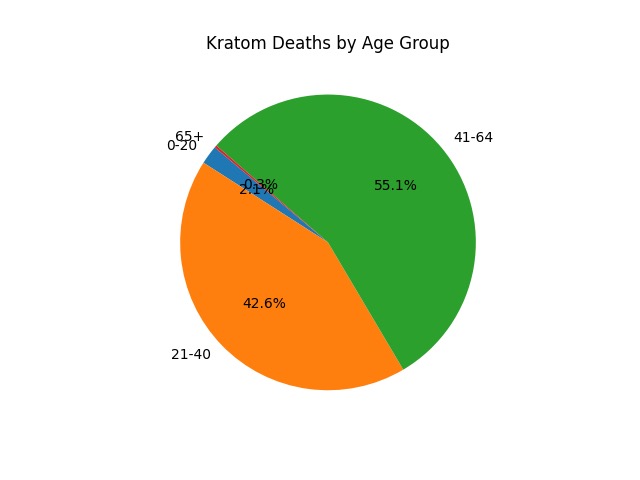
How we built it
We used Python and Python libraries such as Pandas, Csv, Matplotlib, and Seaborn to clean and visualize our data in a digestible manner. We also used HTML/CSS, and JS to build a web application to house our visualizations and supplementary data.
Challenges we ran into
Being inexperienced data scientists, we were not sure of how to approach cleaning and "wrangling" our data. It oftentimes felt like our small wins were overshadowed by the confounding issues and caveats nested inside the dataset.
Accomplishments that we're proud of
We were proud of how we cleaned our data. At first, we were unsure of how to work with a large dataset and found it difficult to determine for ourselves what it meant to "clean" a dataset. Eventually, through much trial and error, we were content with our final product.
What we learned
We learned a great deal about managing large datasets. In particular, we learned a lot and developed much practice in creating sub-data sets and transforming them to fit our visualization needs.

Log in or sign up for Devpost to join the conversation.