-
-
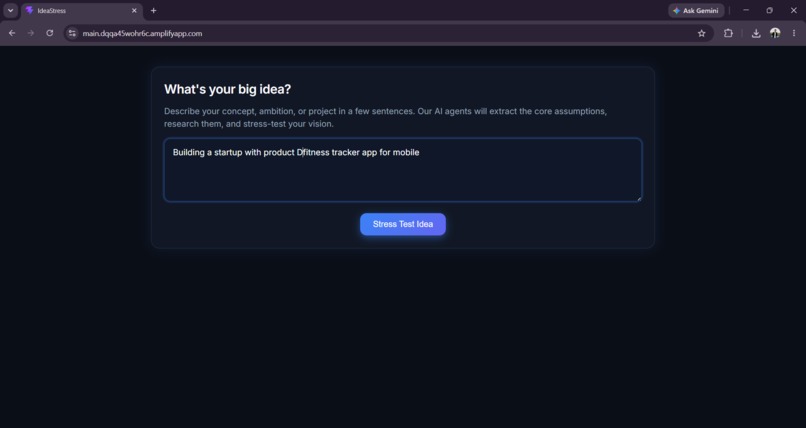
Home Page
-
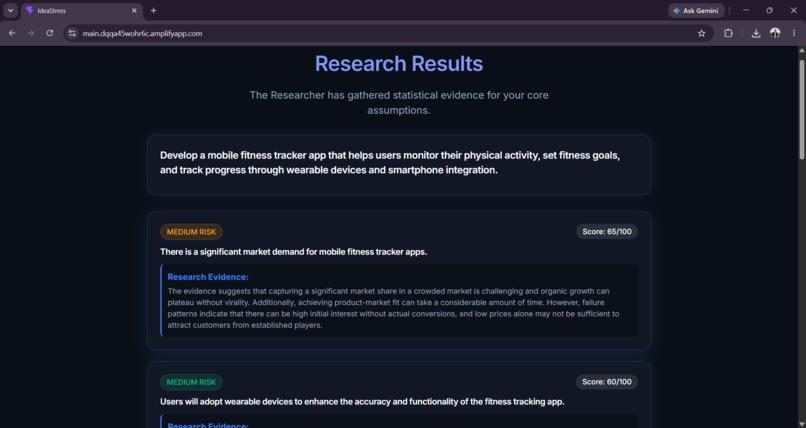
Research Results(Weaviate, Tavily RAG based)
-
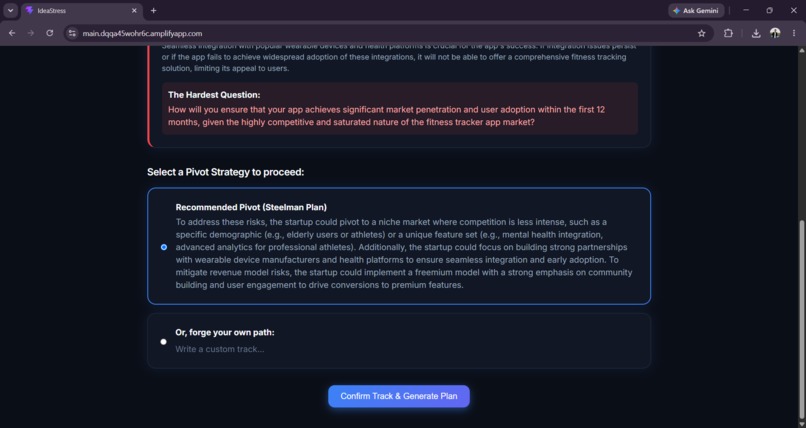
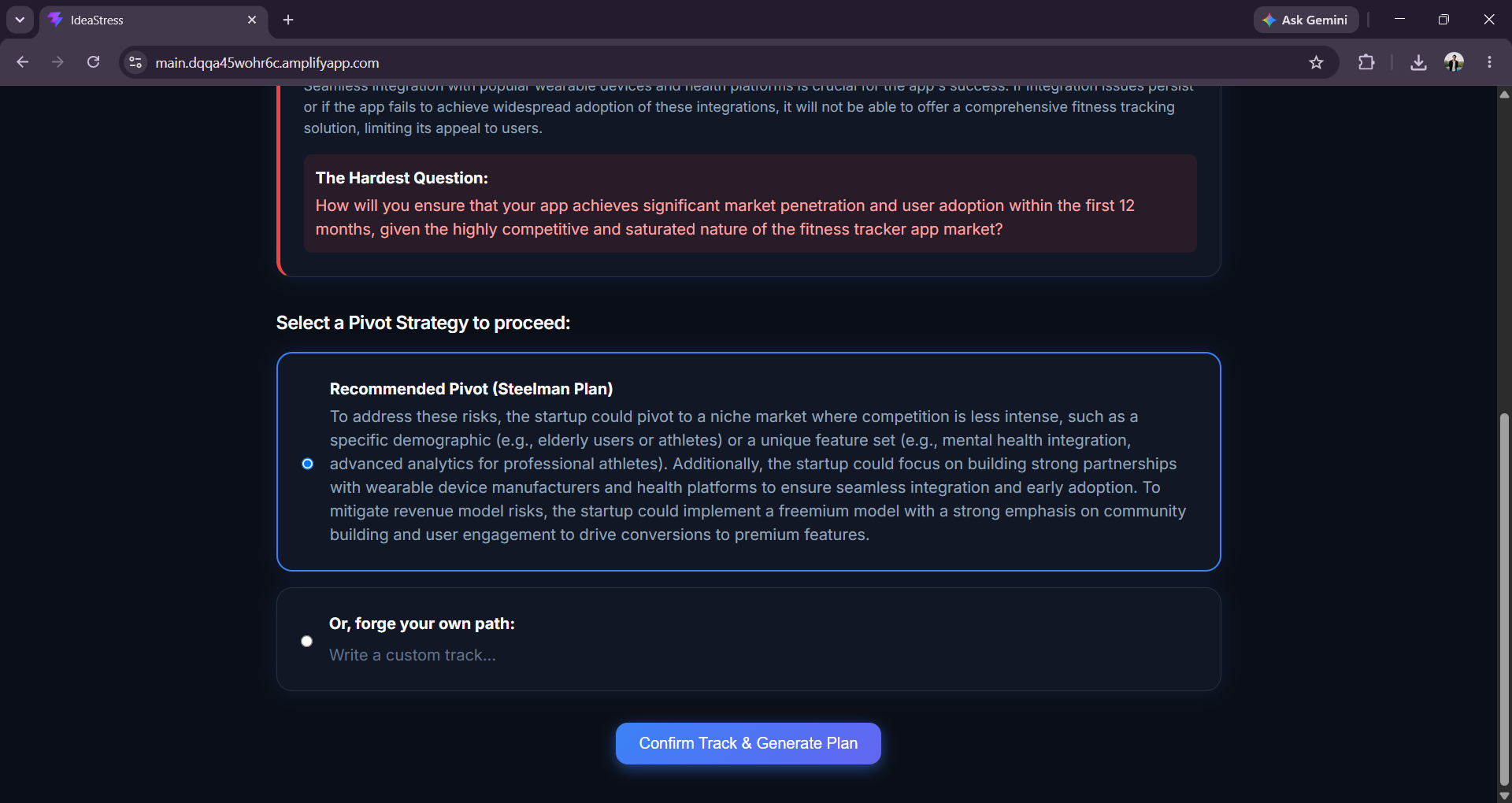
Strategy finalization(Suggested or custom)
-
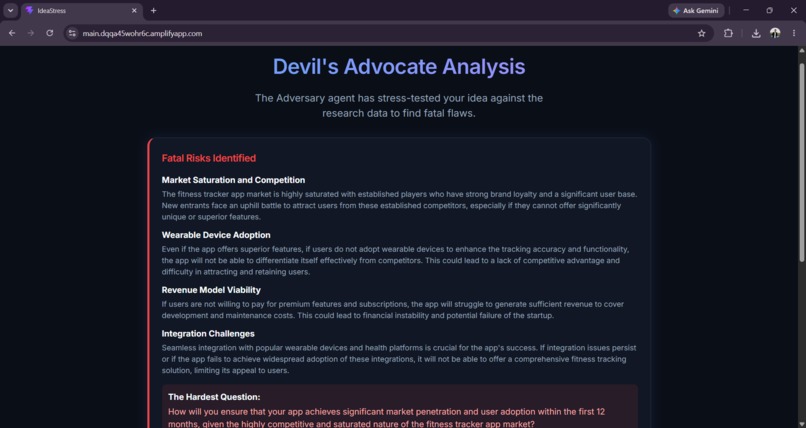
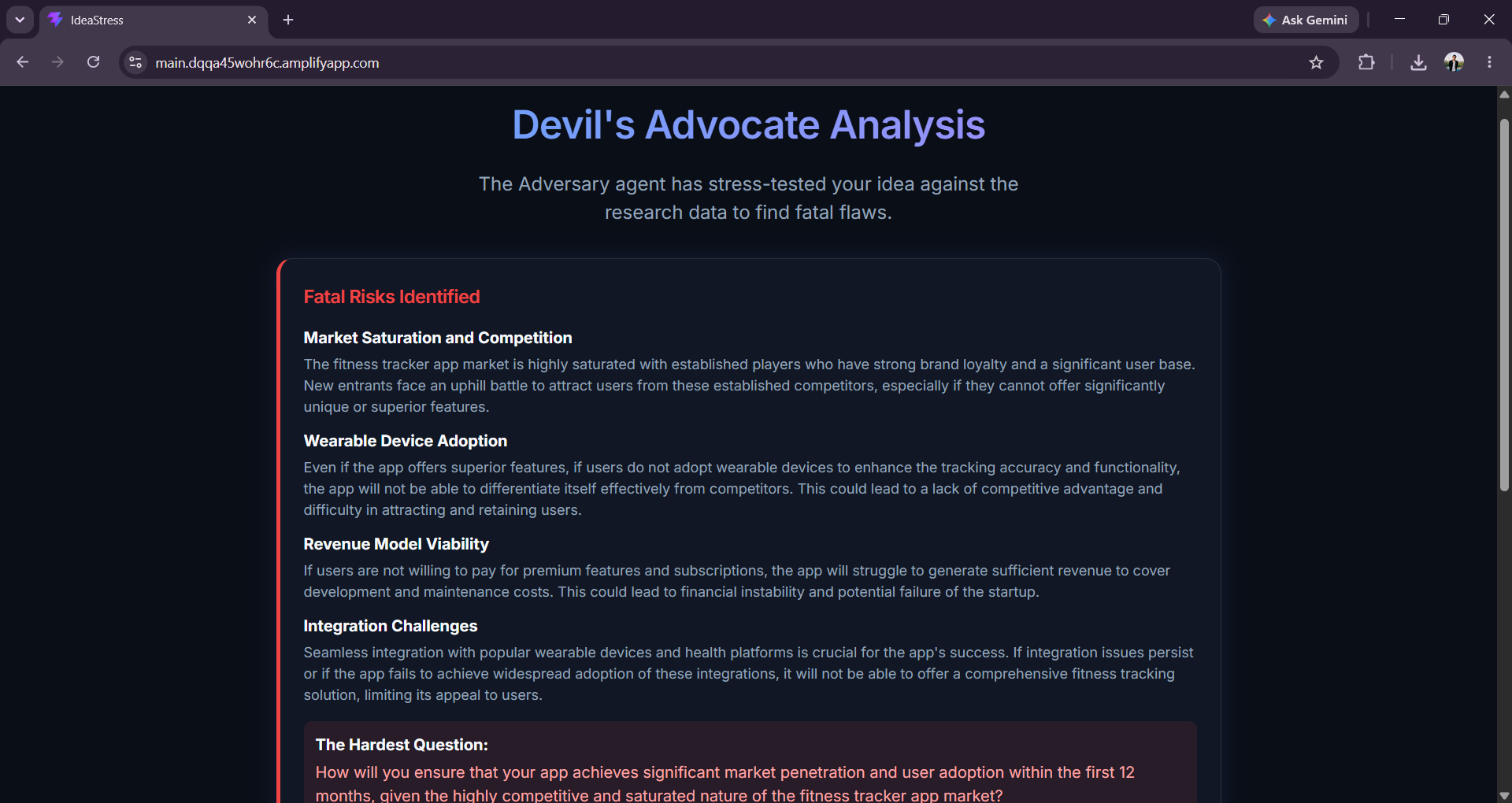
Advice(Criticism with proof)
-
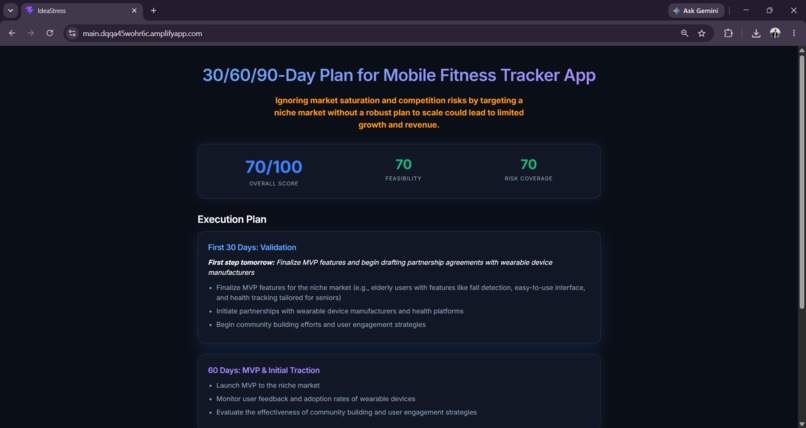
Final Output
-
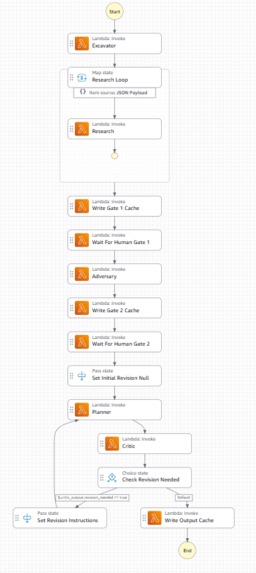
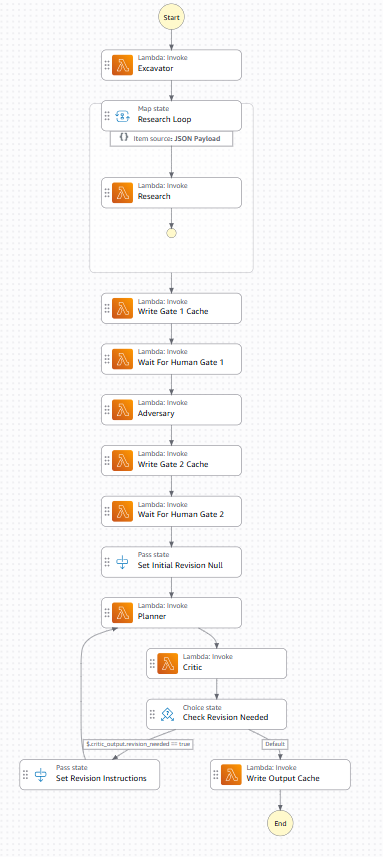
Complete Step Function Data Flow

Devpost: "About the Project" Story
Inspiration
Every one of us has watched a friend — or been the friend — who announces a plan with total confidence. "I'll ship the MVP in two weeks." "I'll learn ML in a month." "I'll undercut the competition by 20% and grab 10% of the market in year one." The plan sounds great in the room. Nobody pushes back, because nobody wants to be the person who kills the vibe.
We wanted to build "the friend" who does push back — not to be discouraging, but because the gap between an unexamined assumption and a failed project is exactly where most student and first-time-founder energy gets wasted. The Direction B prompt asked for a "Zero-to-One Builder," and we kept coming back to the same idea: the most valuable thing an AI system can do for someone with a vague idea is to generate a plan for them. It forces them to confront the assumptions hiding inside the idea they already have, before reality does it for them.
That became IdeaStress: an idea doesn't get to become a plan until it survives being questioned.
What it does
IdeaStress takes a free-text idea — a startup, a career pivot, a class project, anything — and runs it through a five-agent pipeline with two mandatory human checkpoints:
- Excavator reads the idea and surfaces 4–8 hidden assumptions the user never stated out loud — timeline assumptions, market-size assumptions, skill assumptions — each tagged with a type and an optimism level.
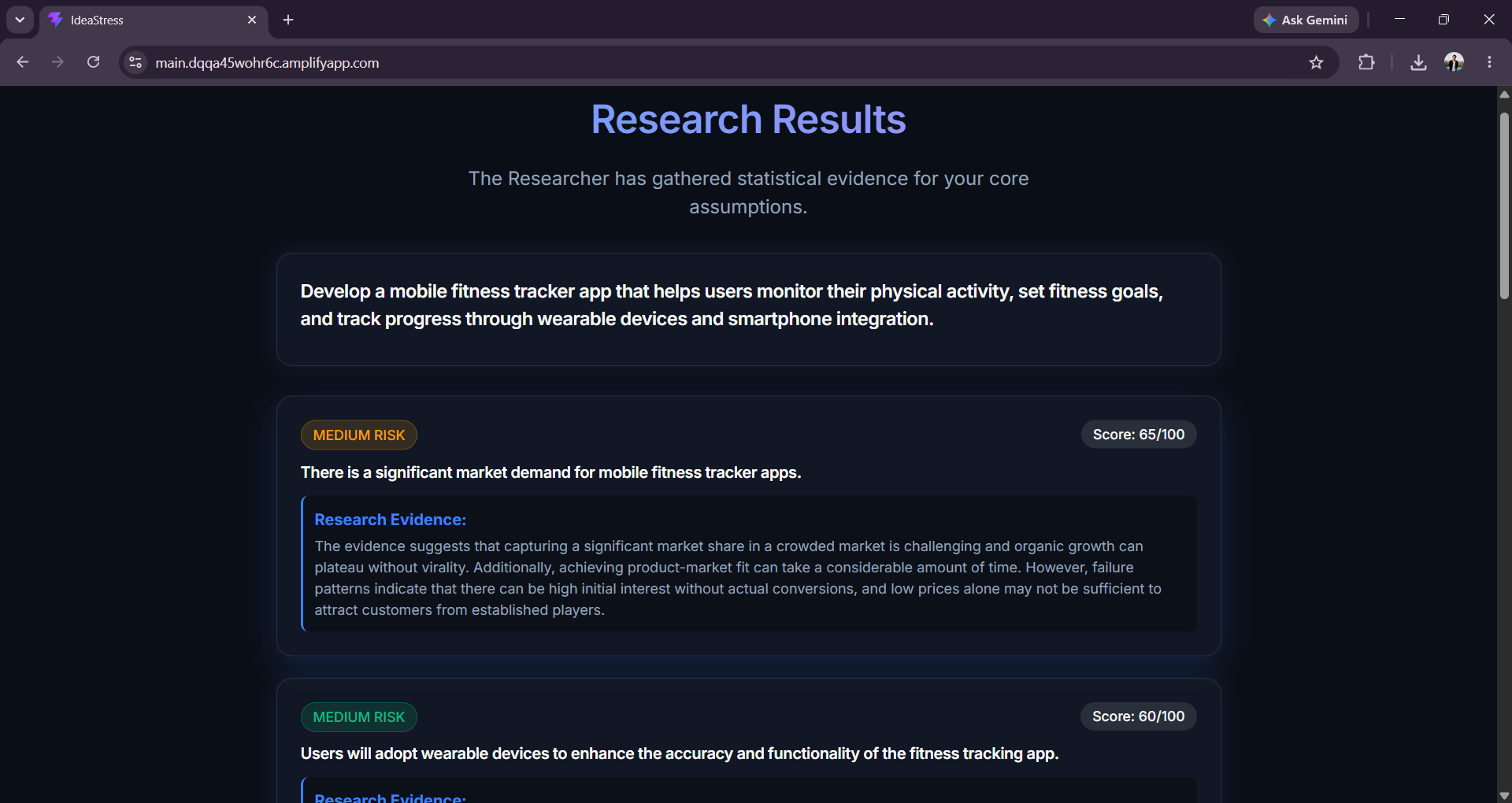
- Research, running in parallel across every assumption, checks each one against a Weaviate vector store seeded with startup/career/education failure data, falling back to a live Tavily web search when the vector match is weak, and writing good web results back into the corpus so it gets smarter over time.
- Human Gate 1 — the pipeline stops. The user reads the evidence-backed assumption cards, with confidence scores and risk badges, before anything else happens.
- Adversary takes only the assumptions the user confirmed and builds the strongest possible case against the plan — specific risks, severities, and the single hardest question the user hasn't answered.
- Human Gate 2 — the pipeline stops again. The user reads the attack and chooses their own track: full speed ahead, find a user first, or rethink the core. The AI never recommends one.
- Planner builds a track-specific 30/60/90-day plan with a literal "do this tomorrow morning" first step, risk flags per phase, and backup plans with explicit triggers.
- Critic grades the plan on four dimensions and automatically sends it back for one revision if the score is too low — so a weak plan never reaches the user as the final answer.
The result is a plan that's been argued with, before the user ever sees it.
How we built it
The backend is a five-Lambda agent pipeline orchestrated by AWS Step Functions, with waitForTaskToken states pausing execution at both human gates until the frontend calls /resume. Each agent — excavator, research, adversary, planner, critic — is its own Python 3.12 Lambda, callable and redeployable independently, which mattered a lot when we were iterating under time pressure.
For evidence grounding, we used Weaviate Cloud as a RAG layer. The Research agent queries a pre-seeded corpus of startup/career/education facts and known failure patterns via near_text, and only reaches for a live Tavily search when the cosine similarity comes back below a configurable confidence threshold — keeping latency and API usage down while still self-improving the corpus with every fallback.
The frontend is a React + Vite single-page app that polls a /status endpoint every couple of seconds to detect when each pipeline stage is ready, then renders the appropriate screen — Input, Gate 1, Gate 2, or the final Output dashboard — with zero account creation, zero login, and a UUID session_id as the only thing scoping a user's data.
Challenges we ran into
The "one free collection" surprise. Our design doc specified three separate Weaviate collections — RealWorldFact, UserAssumption, FailurePattern — with three different vectorized fields. Partway through the build we discovered the Weaviate Cloud sandbox tier only allows a single collection. Rather than burn hours fighting the tier limit, we collapsed everything into one IdeaStressData collection with a record_type discriminator field and skip_vectorization flags on every property except text_content. It's a less elegant schema than what we designed, but it shipped, and it's still fully queryable by type via Filter.by_property("record_type").
The model swap, mid-build. Our architecture doc commits hard to Claude Sonnet 4.6 and Claude Haiku 4.5 via Bedrock for every agent. In the actual Lambda code, every agent calls amazon.nova-lite-v1:0 through bedrock.converse() instead. Bedrock model access approvals and quota in our region didn't land in time, so we pivoted to Nova Lite to keep the pipeline working end-to-end rather than blocking the whole demo on an access request. It's the single biggest gap between what we designed and what we shipped, and it's the first thing we'd change with more runway.
Async human gates on serverless infrastructure. waitForTaskToken is built for exactly this pattern, but two separate Lambdas — the one writing the gate-ready cache and the one the frontend polls — can't share an in-memory dictionary across cold starts. We went through two designs: first an in-process _GATE_CACHE dict (fine until the container recycled), then a combined gate-status Lambda with an action dispatcher (WRITE_CACHE / NOTIFY_WAITING / GET), ultimately backed by Weaviate itself as a tiny persistent key-value store so the cache survives cold starts. It's an unconventional use of a vector database, but it solved a real distributed-state problem without standing up DynamoDB under hackathon time pressure.
Keeping the human actually in the loop. It would have been easy to let the AI silently pick the "best" execution track or auto-approve assumptions to make the demo flow faster. We deliberately built Gate 2 so the proceed button stays disabled until the user makes an active selection, and the Adversary's output is shown with zero "recommended" styling — the steelman counterplan is presented as one option among others, not a default.
Accomplishments that we're proud of
- A fully working five-agent pipeline with two real, blocking human checkpoints — not cosmetic ones — running on serverless infrastructure end to end.
- A self-improving evidence corpus: every low-confidence Research query that falls back to live web search writes its findings back into Weaviate, so the system gets better at answering the next person's version of the same assumption.
- Solving the async-state-across-Lambdas problem under real infrastructure constraints, twice, without giving up and just polling a database every 500ms.
- A Critic agent that doesn't just score the plan — it enforces its own revision loop, so "good enough" plans get sent back automatically instead of being good enough.
- Shipping a deployed, demo-able product (AWS Amplify + API Gateway + Step Functions, live and working) within the hackathon window, with all four team members' pieces integrated.
What we learned
We learned that the gap between a system architecture document and the deployed system is where the real engineering happens — our Weaviate collection count and our Bedrock model IDs both changed mid-build in response to real infrastructure limits, and the team's ability to adapt the implementation without losing the intent (RAG-grounded, adversarially-tested, human-gated) was the difference between a stalled project and a working one.
We also learned that "responsible AI" is easiest to be compromised under time pressure, and easiest to defend when it's architectured as a hard constraint rather than a feature flag. Building Gate 1 and Gate 2 as genuine Step Functions pauses — not just a loading spinner with a delay — meant there was no code path where the AI could quietly skip past the human. That structural decision, made early, is what kept the human-in-the-loop promise true under deadline pressure later.
What's next for IdeaStress
- Expanding the Ground-Truth RAG Corpus: Right now, our Research agent falls back to live Tavily web searches when the vector match is weak. Next, we plan to build an automated ingestion pipeline to scrape and vectorize Paul Graham's essays, Y Combinator Startup School transcripts, CB Insights autopsy reports, and BLS occupational data. This will create a massive, highly curated "autopsy corpus" so the AI's feasibility scores are grounded in hard data rather than generic web results.
- Multi-Modal Evidence Input: Currently, users submit a 2-3 sentence summary of their idea. We plan to upgrade the Excavator agent to accept PDF business plans, slide decks, or financial spreadsheets. By utilizing Amazon Nova's multi-modal capabilities, the system could extract hidden assumptions buried deep within a user's financial projections or market sizing charts.
- Long-Term Accountability AI (EventBridge Cron): IdeaStress shouldn't stop at generating the plan. We want to implement an AWS EventBridge scheduler that "wakes up" the AI once a week. It would email the user to check on their 30-day milestone progress. If the user missed their targets, the
Planneragent would dynamically recalculate and adjust the 60/90-day execution steps based on their actual, real-world velocity. - One-Click Export to Execution Tools: To completely bridge the gap between "planning" and "doing," we want to integrate the final output with standard productivity APIs. With a single click, a user could export their risk-mitigated 30/60/90-day plan directly into a Notion workspace, Jira board, or Trello, instantly turning the AI's reasoning into trackable tickets.
Built With
- amazon-bedrock
- amazon-nova-lite
- aws-amplify
- aws-api-gateway
- aws-lambda
- aws-step-functions
- javascript
- python
- react
- tavily
- vite
- weaviate-cloud-(wcd)



Log in or sign up for Devpost to join the conversation.