


Inspiration
Artificial intelligence is often used to generate ideas or superficially validate them, but rarely to critically evaluate them. In reality, most ideas fail not because they are inherently bad, but because hidden assumptions go unchallenged, incentives are misaligned, or risks are overlooked too late. This inspired us to build IdeaForensic — a system that doesn’t flatter ideas, but instead interrogates them through structured reasoning, perspective mismatch analysis, and causality-first evaluation.
Rather than relying on outputs that feel like encouragement or vague pros/cons and , we wanted a tool that uses deep, systematic reasoning — similar to how investigative analysts or product strategy teams assess value and risk. This ethos aligns directly with the Action Era vision: moving beyond static chat and into coordinated, multi-step autonomous thought that mirrors human expert analysis.
What it does
IdeaForensic is an AI-powered forensic reasoning agent. It takes an idea as input and returns a detailed evaluation featuring:
Idea Breakdown: Clarifies the real user, problem claims, and what the system actually does.
Reality & Differentiation Check: Distinguishes marketing novelty from real functional uniqueness.
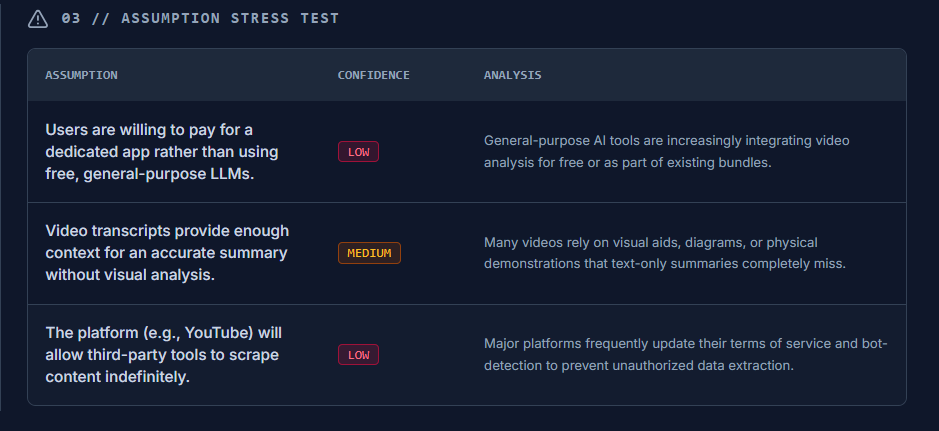
Assumption Stress Testing: Identifies and weighs hidden assumptions with evidence strength (High/Medium/Low).
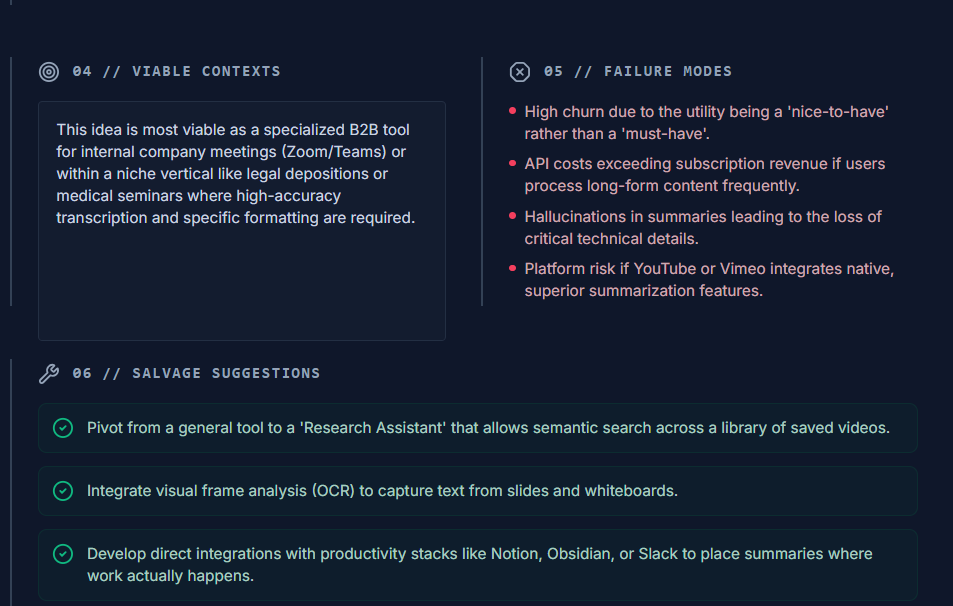
Failure Modes & Behavioral Analysis: Shows where and why an idea might struggle in the real world.
Structured Perspective Mismatch: Compares founder expectations with user behavior, market forces, and incentive alignment.
Balanced Verdict: Labels the idea as naïve, viable, or promising-but-fragile — with practical reasoning.
Improvement Guidance: Offers one concrete, realistic change that would meaningfully increase survival probability when appropriate.
Unlike traditional “idea evaluators,” IdeaForensic isn’t a chatbot or a prompt wrapper. It performs a single autonomous reasoning pass with clear stages, internal verification, and an output format designed for clarity and repeatability.
How we built it
We built IdeaForensic using Google AI Studio with the Gemini 3 Pro model because it supports:
Long-context reasoning: maintaining entire idea states across multiple analytical sections.
Structured multi-step workflows: enabling the system to follow a defined analytical pipeline without losing coherence.
Internal counter-argument generation: allowing the model to critique and then defend ideas within the same execution.
In AI Studio Build, we defined a core prompt that enforces a multi-stage reasoning framework. Each stage corresponds to a disciplined analytical step rather than open-ended text generation. We tuned the reasoning level and control parameters to emphasize accuracy, causality, and evidence signals. We also iterated prompt architecture to reduce superficial or overly optimistic language, pushing Gemini to simulate realistic belief degradation and expose structural weak points.
Challenges we ran into
Building an “honest evaluator” rather than a cheerleader forced us to confront a few key challenges:
Balancing critique vs. useful guidance: Initial versions defaulted to overly negative assessments. We refined the prompt to ensure that when an idea is viable, the system focuses more on how it works rather than only why it doesn’t.
Avoiding vagueness: Early outputs sometimes relied on generic language like “might be risky.” We addressed this by requiring explicit assumption grading and forcing causal explanation for every claim.
Gemini behavior drift: In experimentation, multistage responses would sometimes collapse into repetitive sections or repeat reasoning. We solved this by structuring the reasoning steps in a fixed order and using clear section headers in the prompt.
Aligning with hackathon constraints: We had to ensure the system demonstrated autonomous reasoning, internal verification, and was not a simple UI around a single prompt. This influenced our design decisions and forced us to elevate the substance of the output over the superficial polish of interaction.
Accomplishments that we're proud of
A structured reasoning pipeline that feels like an expert review: Outputs are consistent, logical, and evidence-driven, mimicking human critical analysis.
Clear differentiation from generic AI tools: IdeaForensic isn’t a chatbot — it’s a reasoning engine with defined stages, not open conversation.
Gemini-native depth: By leveraging Gemini 3 Pro’s long-context capacity and reasoning levels, we created output that sustains coherent evaluation across multiple sections in one autonomous pass.
Balanced verdicts: The model gives honest assessments — it supports ideas that are reasonably strong and constructively critiques ones that are weak. It also provides actionable pivot suggestions rather than generic platitudes.
Seamless reproducibility: Anyone with the AI Studio link or GitHub repo can rerun the same evaluation with a new idea and expect the same analytical structure.
What we learned
AI is most powerful when it reasons, not just responds. Static chat responses rarely expose risk or hidden assumptions — an autonomous analysis pipeline does.
Structured prompts plus clear output formats matter. Small changes in how you enforce sections and constraints drastically improves output quality.
Gemini 3’s long-context reasoning is what makes this possible. Without long-context memory and cascading internal critique, the entire forensic approach would collapse into surface-level comments.
Judges care about clarity and repeatability. Reproducible structure and predictable sections are easier to evaluate than open narratives.
What's next for IdeaForensic
We already have a working core system inside AI Studio, but we see several enhancements for the future:
External UI Wrapper: A minimal frontend that presents results in a visually digestible way (e.g., collapsible forensic sections, confidence scoring bars).
Batch Analysis: Allow users to evaluate a set of ideas and compare their risk profiles side-by-side.
Data-Driven Signals: Integrate optional data sources (e.g., market indicators, domain datasets) to augment reasoning with empirical data where available.
Persistent Memory: Add user idea history and long-term improvement tracking so teams can iterate collaboratively.
Interactive Walkthroughs: Post-analysis exploration where users can query why a particular assumption was downgraded or what evidence would shift the verdict.


Log in or sign up for Devpost to join the conversation.