-

Simple and clean interface for entering keywords
-
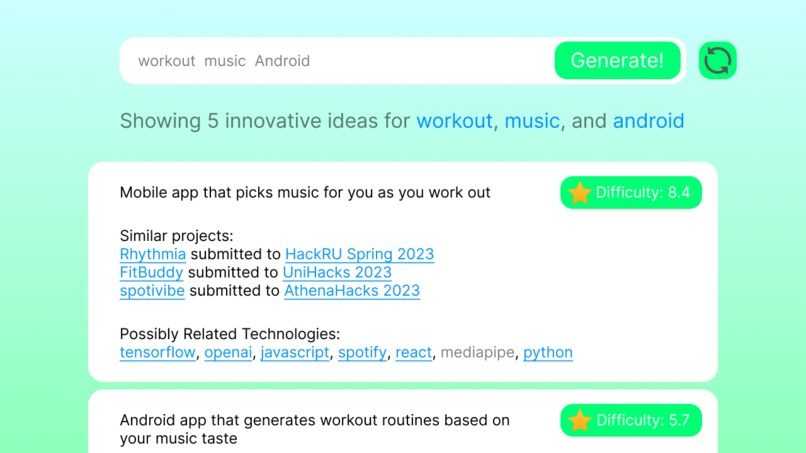
Generated project inspiration, along with similar projects on Devpost and directions for tech next steps


😔 Problem
Ideation is hard!
It's super hard to come up with creative ideas for hackathons. It is not uncommon for strong teams to not place well simply because they couldn't ideate something novel.
Furthermore, even after decent ideas come up, teams have to spend precious time deciding which ideas are feasible. Hackathon projects often rely on external APIs (its practically impossible to code functionality from scratch during a hackathon), making project ideas' technical feasibility highly dependent on availability of related APIs.
🤔 Why No Solution Exists
Yes, there are hackathon idea generators. First result on Google is Wolfram Cloud. I tried it out:
- First idea: "Make a quiz from overhead satellites". Yes, I am definitely going to make a quiz from overhead satellites within 24 hours!
- Second idea: "Find matches between planes overhead". Hmm I'm not even sure what this is supposed to mean.
- Third idea: "Show the relationships between parts of rhyming words". Ok, this can be interesting... but I'm not sure where to start.
Second result on Google is helpineedideas (I love the name btw). I tried it out too:
- I entered "education" and it said: "A mobile app that helps connect students with relevant resources and opportunities in their local community, including course selection info, job listings, and meeting places. The app would also allow students to communicate and collaborate with classmates and peers, setting up opportunities for social and professional growth." This site uses OpenAI & its ideas are pretty good - this sounds like a cool side project. However, there's good reason we haven't seen much like this idea in past hackathons: it's simply not feasible in 24 or 48 hours.
So, why is there no good solution so far? No site has access to past hackathon data (Devpost doesn't have an API), so these ideas are being spun out of thin air.
💡 Solution Overview
When searching for inspiration, one thing a lot of hackers do is look at past winners of Devpost hackathons. In this process, any public Devpost submission and any public GitHub repo is fair game for inspiration.
Upon digging through past Devpost hackathons, I realized there is a lot of data that can be mined by looking at Devpost submissions. This leads me to my proposed solution: Use big data from past Devpost hackathons to help generate new ideas.
This comes in 2 parts:
- The app needs to generate creative ideas
- The app needs to provide information about technical feasibility
Currently, this idea generator is something that only Devpost can build, since only Devpost has access to vast amounts of past hackathon data. Next, I will explain a possible way to build this app if I could utilize the data on Devpost. The most effective way to approach this problem would be to utilize neural networks, but as I'm not familiar with what resources are available, I'll provide a budget solution without neural networks, which I envision could still be decently effective.
🌺 Solution Part 1: Generate Idea
Inputs: project writeup texts and any prizes won by the project can be used to build the model, while keywords from the user are used at runtime to generate ideas
Step 1 (building model): Vectorize words used in hackathon contexts. Pre-trained word vectors such as the GloVe common crawl with 1.9M vocab words could be used, but common semantics are imaginably different from hackathon semantics (for example, "python" in common English refers to an animal, but in hackathons it more often refer to a programming language). Hence, it is probably better to use vast numbers of Devpost hackathon writeups (the project story field in the submission) to train custom vectors with GloVe.
Step 2 (building model): Use clustering algorithms to associate words that are commonly used together. Clustering algorithms could be used to classify groups of words that are commonly used together. I'm not sure what word vectors based on hackathon semantics look like, but I imagine that since concepts in CS follow more of a hierarchical structure (ex. "vue" and "react" are under "javascript") than common English (ex. a word like "orange" means both a color and a fruit), hierarchical clustering could work. It also wouldn't hurt to try out other classic clustering methods such as k-means or mean-shift clustering. Additionally, note that the idea part of a project is still common English, so there is a web-like aspect to the data; hence, for every cluster, a short-range BFS can be performed outside cluster boundaries to include nearby words which are close to the cluster.
Step 3 (runtime): Use user keywords to find semantically similar words. When the user types in 3 keywords, create a set union of all clusters that include at least one of those keywords. Next, keep only the top, say, 250 words that are closest in cosine similarity to any one of the keywords. This will create a dictionary that can be used in step 4. Note that the words in this dictionary will all be words that are often associated with the user's keywords in a hackathon project context.
Step 4 (runtime): Combine words in dictionary to generate random ideas. GPT isn't needed in a budget solution. An algorithm using a context-free grammar such as Backus-Naur form, which operates on the dictionary of words generated in step 3, is very easy to implement and likely quite effective. Backus-Naur form gives grammatically correct sentences, but in all honesty, I'm not sure how well it fares with idea phrasing - this may be the weakest link in this chain. Note that there are existing open-source libraries such as CoreNLP which can classify parts of speech.
Step 5 (runtime): Sort results. There should be a metric to sort the results generated in this manner. For example, maybe the ideas using the most common words should come first? Or the ideas for which there are related prize-winning hackathon projects should be ordered first?
💻 Solution Part 2: Calculate Technical Feasibility
Inputs: various parameters such as hackathon length and GitHub code can be used to build the model, while projects associated with the generated keywords from part 1 are used at runtime to chart out technical feasibility
Step 1 (building model): Assign difficulty ratings to select existing projects. Technologically knowledgeable people need to go through a number of successful hackathon projects (~1000-2000?) and give each one a difficulty rating from 1 to 10. This selection of projects should cover a wide range of technology stacks.
Step 2 (building model): Normalize dimensions of every project. Several numerical factors should first be identified per project. Some that I can think of are the length of the hackathon in hours, the lines of code in GitHub (scaled by a constant for each programming language - ex. 100 lines of JSX is much easier to write than 100 lines of Java), the number of people who collaborated on the project, etc. Next, these factors should be normalized so that the range of every factor corresponds to the significance of the factor.
Step 3 (building model): Create easy way to query for projects associated with a given phrase. A map of common keywords to the 3-4 projects that mention them the most can be used. In this way, after an idea is generated in part 1, the keywords in the idea can be used to get a list of all projects that are similar to the idea. Let this list of projects be referred to as "idea-related projects".
Step 4 (runtime): Use KNN to calculate a difficulty for idea-related projects. A difficulty rating can be assigned to all the idea-related projects via a K-nearest neighbors search against the projects indexed in steps 1 and 2 (ex. the factors for the 4 nearest projects can be averaged). Next, a difficulty can be assigned to the idea via a weighted average of the difficulties of idea-related projects. I want an average where higher difficulties are weighted heavier, since the difficulty of a project is often set by the hardest 1-2 elements in the technology stack. I envision the usage of an average where the highest difficulty holds 50% total weight, the second highest holds 25% total weight, third highest holds 12.5% total weight, and so forth.
Step 5 (runtime): Scrape major technologies used in idea-related projects. Take the set union of all technologies in the "Built with" section for idea-related projects, and that can serve as the list of related tech for the generated idea. This list may be messy (ex. in example screenshot #2, the related tech section contains both "python" and "javascript", which innately don't go together); however, it is a great launch point for hackers considering how to actually implement the idea and whether it is feasible.
🏔️ Foreseeable Challenges
- Data normalization: When calculating project difficulties, is difficult to judge the weight of factors relative to each other. In fact, it's hard deciding which factors to include. This parameter fine-tuning will probably have to be done through trial and error.
- Semi-regular updates: As the tech landscape and hackathon landscape changes over time, the models need to be periodically updated (once every few months?) to reflect the latest changes. For example, a lot more projects lately have been using OpenAI.
⚡ Impact
The potential impact of an app like this is huge. Getting idea inspiration would be made ridiculously more easy, and the hurdle of confirming whether an idea is technically feasible would be practically eliminated. By focusing more on actual project building rather than ideating, hackers can also submit higher-quality projects.
Additionally, with this system, if a few hackathon projects are immensely successful with some new technology or idea, this technology/idea could quickly propagate around the hacker community, which spurs innovation at a much more rapid pace.
📢 Closing Disclaimer
I said a lot about what could possibly be done to facilitate the ideation process for hackers. I believe that the 2 main aspects of the system (generating creative ideas and generating technically feasible ideas) are definitely possible to implement, and I mapped out a possible way to first approach the problem.
However, data analysis often requires repeated trial and error with various techniques and parameters on the data; it is impossible to map out exactly what should be done without access to Devpost data. Hence, what I said may be close to reality, but there's also a chance that my method is a far cry and requires lots of modifications and tuning.
Hope that the general direction of my idea is inspirational though! I would love to see some effective idea generator coming in the near future 😎
Built With
- brain
- figma
- machine-learning



Log in or sign up for Devpost to join the conversation.