-
-

Peer review with AI scientists in real time with Gemini Live API
-
Customize agents with Agent Development Kit
-
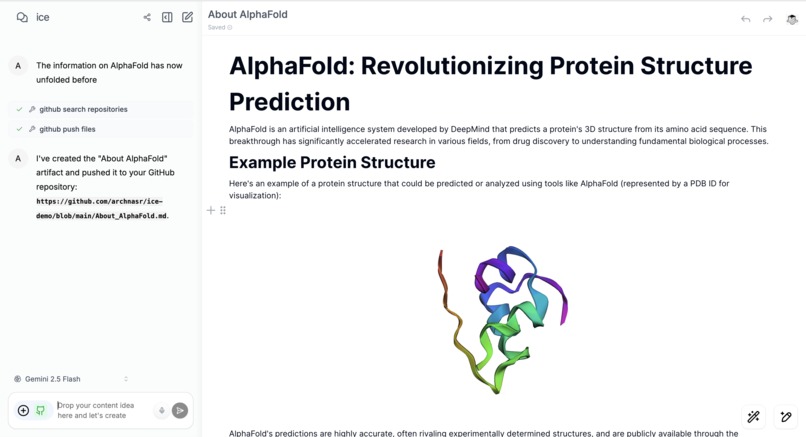
Reproduce results with Github
-
Build personal memory and global memory separately
-
Share Workspaces between humans and AI scientists on cloud
-
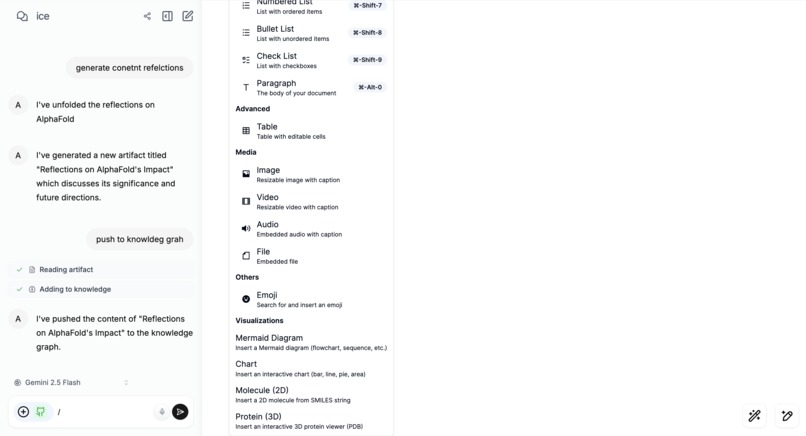
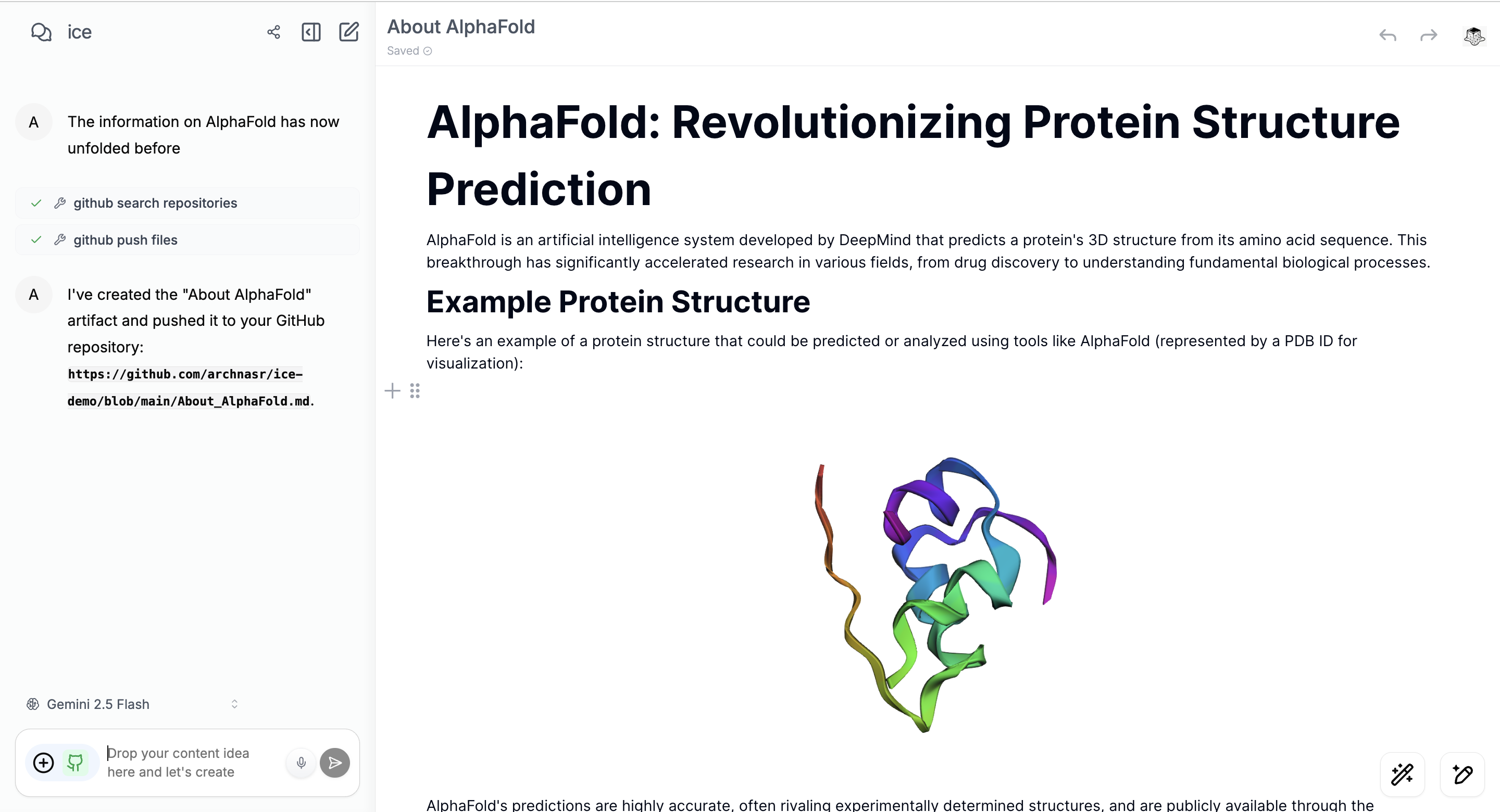
Add Mermaid Diagrams, Chart, 3D/2D and audio comments with gemini embeddings
-
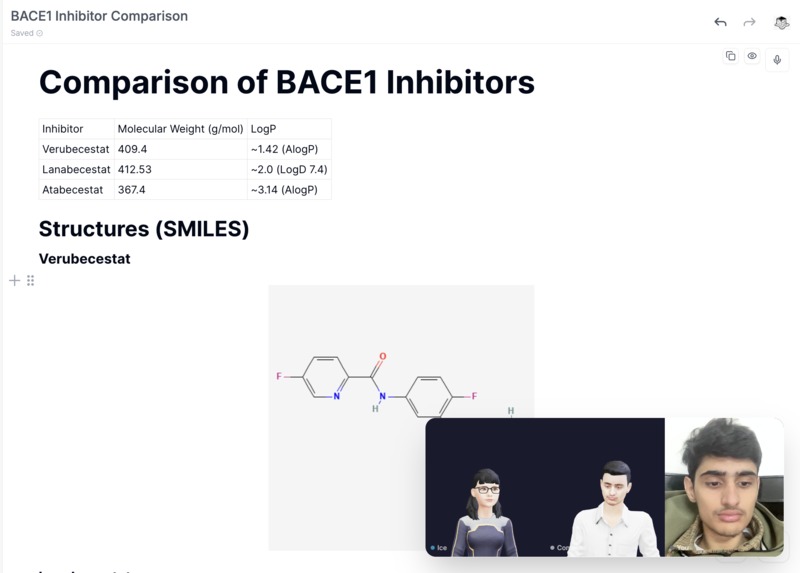
Design molecules with compute agent(it looks like me!)
-
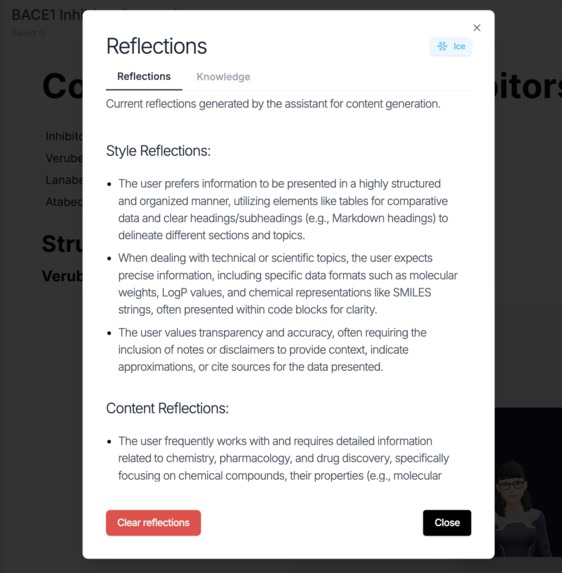
Reflection agent, debounces on ADK!

Inspiration
Static media has always favoured language. On paper, abstract concepts and dynamic phenomena are easier to describe than depict. As a result, culture has evolved expressive and powerful linguistic representations (for example, the behavior of mathematical expressions and variable values in a computer program), while non-linguistic abstract representations are little more than baby talk. Generative AI applications repeat the same pattern: markdown and coding artifacts remain as static dumps buried in long chats. Concepts poorly suited to language remain barely thinkable. What if we design a medium that externalizes as much thought as possible, a medium that is literally an extension of the mind.
We see ice as opening the door to a thinking medium built to fit the human, instead of deforming the human to fit the medium. One where academic culture can start to develop a dynamic multimodal literacy and collaborate with others harnessing AI in the loop.
What it does
ice provides a thinking medium for collaborative document and code creation between humans and AI scientists so that thought can be outside the head in a form that can be seen and manipulated. You open ice and you are in a video call with an AI scientist and a shared canvas where documents and code take shape as you think out loud.
Starting & Iterating with ice
We always start with something, either content already in files or ideas floating in our heads. For content that exists, ice lets you open a text or code editor and start collaborating on top of it. For ideas that don't exist yet, you baby talk, express rough thoughts over voice and camera, and watch the canvas give them form rather than waiting for AI to dump text at you.
But starting is not the hard part. Iterating is, especially alone. It's easy to get stuck in local maxima. ice helps you find your global maximum by letting you share sessions with others. They join the same video call, the AI scientist walks them through your work, and they fork their own version to keep going. Human collaboration evolves with AI in the loop.
How we built it
ice is built around three pillars: information, computation, and evolution.
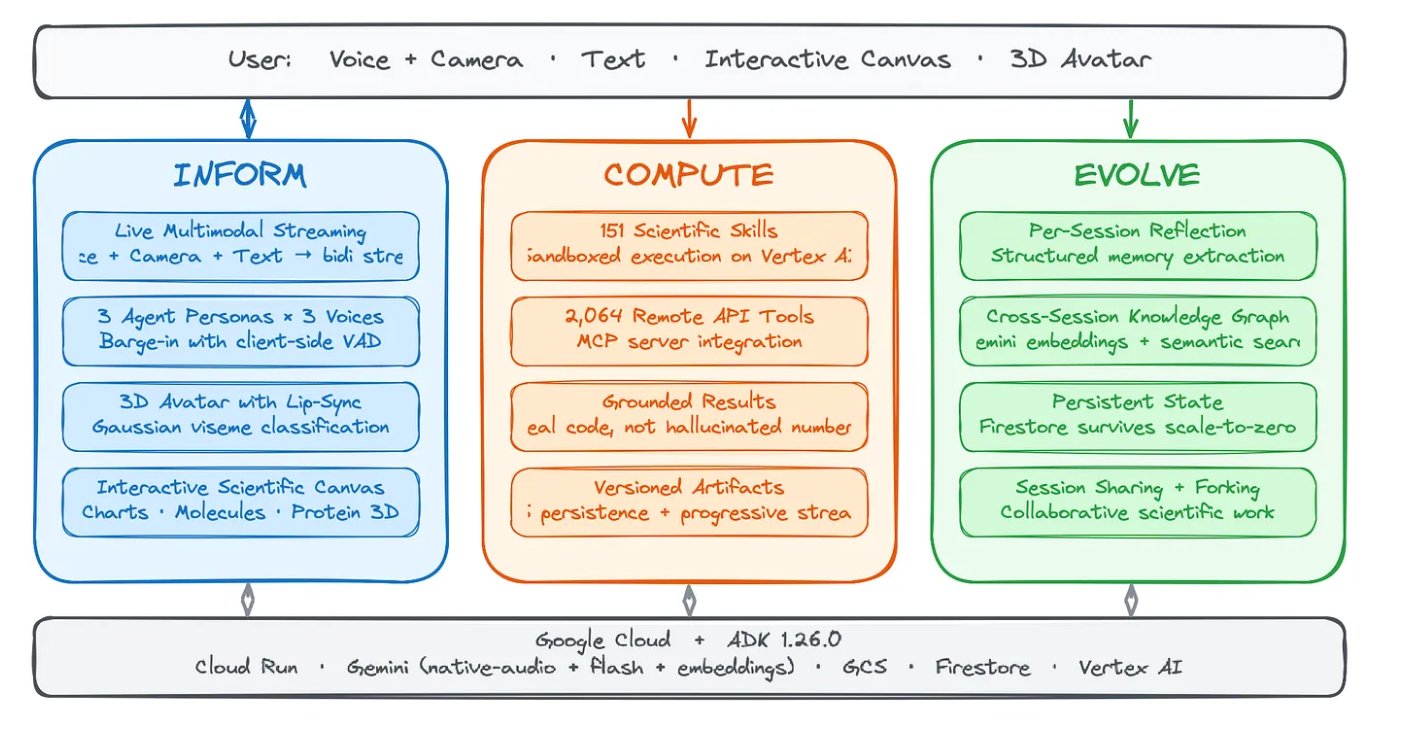
Inform. When you baby talk into ice, expressing half formed thoughts over voice and camera, all of that arrives on a single bidiGenerateContent stream through ADK's LiveRequestQueue with no turn boundaries. You can interrupt mid sentence and it reconsiders; we handle barge in client side, VAD clears the AudioWorklet buffer before the server even knows. A second camera watches the agent's own workspace at 1 fps, so if it made an error in an artifact, it catches it and corrects itself mid conversation. You can create your own assistant with a custom system prompt and context documents, or use the three built in agents that ship with ice: Root, Researcher (Kore), and Compute (Charon), each with a distinct native audio voice, handing off via ADK's TransferToAgentTool. When Charon enters to run a computation, it appears in the call like someone joining a meeting. I modeled Charon's avatar after myself, so it feels like a version of you doing the heavy lifting while you keep talking. Most AI canvases render markdown and code. ice renders 3D molecular structures (RDKit, 3Dmol.js), protein viewers, Mermaid diagrams, charts, and tables as native objects inside the document, and you can record voice annotations directly over them.
Compute. You keep talking while the computation runs.
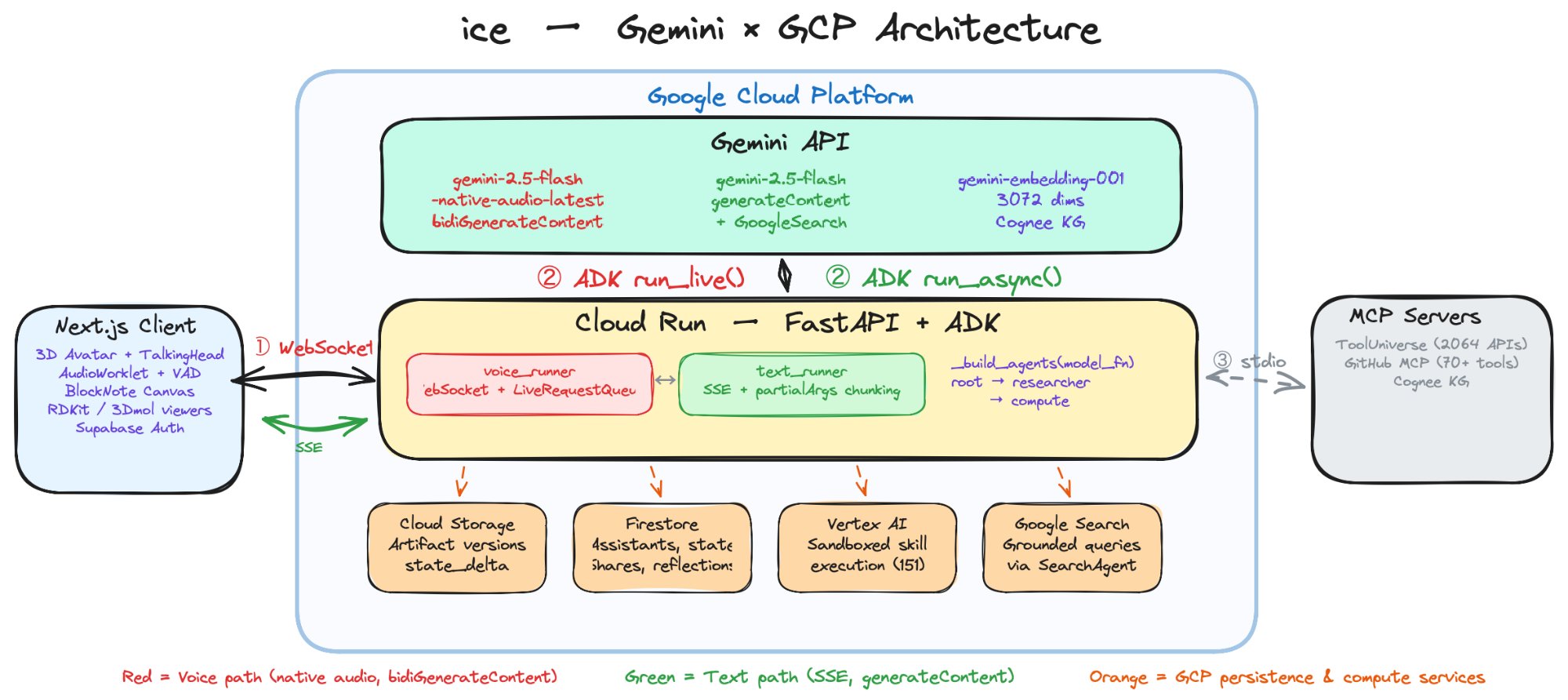
Ask for the logP of aspirin and a molecular properties table fills the canvas mid conversation. ADK orchestrates all of this on Google Cloud: skill calls go through ADK's SkillToolset to Charon, which executes 151 scientific skills (RDKit, BioPython, SciPy, PDB, AlphaFold) plus 14 custom protein docking skills we added in sandboxed Vertex AI environments, alongside 2,064 API tools through a ToolUniverse MCP server. ADK's GcsArtifactService versions every artifact to GCS with undo and redo through currentIndex branching. Firestore persists session and assistant state across Cloud Run cold starts. Context window compression (triggers at 100K, slides to 80K) eliminates the 15 minute session limit. Connect your GitHub and the agent picks up 70+ tools for repos, PRs, and code search through the same ADK tool pattern.
Evolve. Iterating alone is how you get stuck in local maxima. So ice remembers, and ice shares. Every artifact operation fires a background reflection step without blocking audio, where forced Gemini Flash function calling extracts what it has learned about you, your style, your research context, into user: scoped ADK state. Come back next week, ask about CRISPR delivery, and it picks up where you left off. Cognee's knowledge graph, backed by Gemini embeddings, takes this further: you choose what to index, a single artifact or an entire chat, and anyone on ice can search what others have contributed. The graph grows as people use it. Sessions can be shared via URLs or forked into independent copies with full state and _fork_source context injected into the system instruction. A lip synced avatar narrates shared sessions, walking your collaborator through the visualizations so they can fork and keep going.
Challenges we ran into
Making the baby talking experience work required solving problems that don't show up in text only agents.
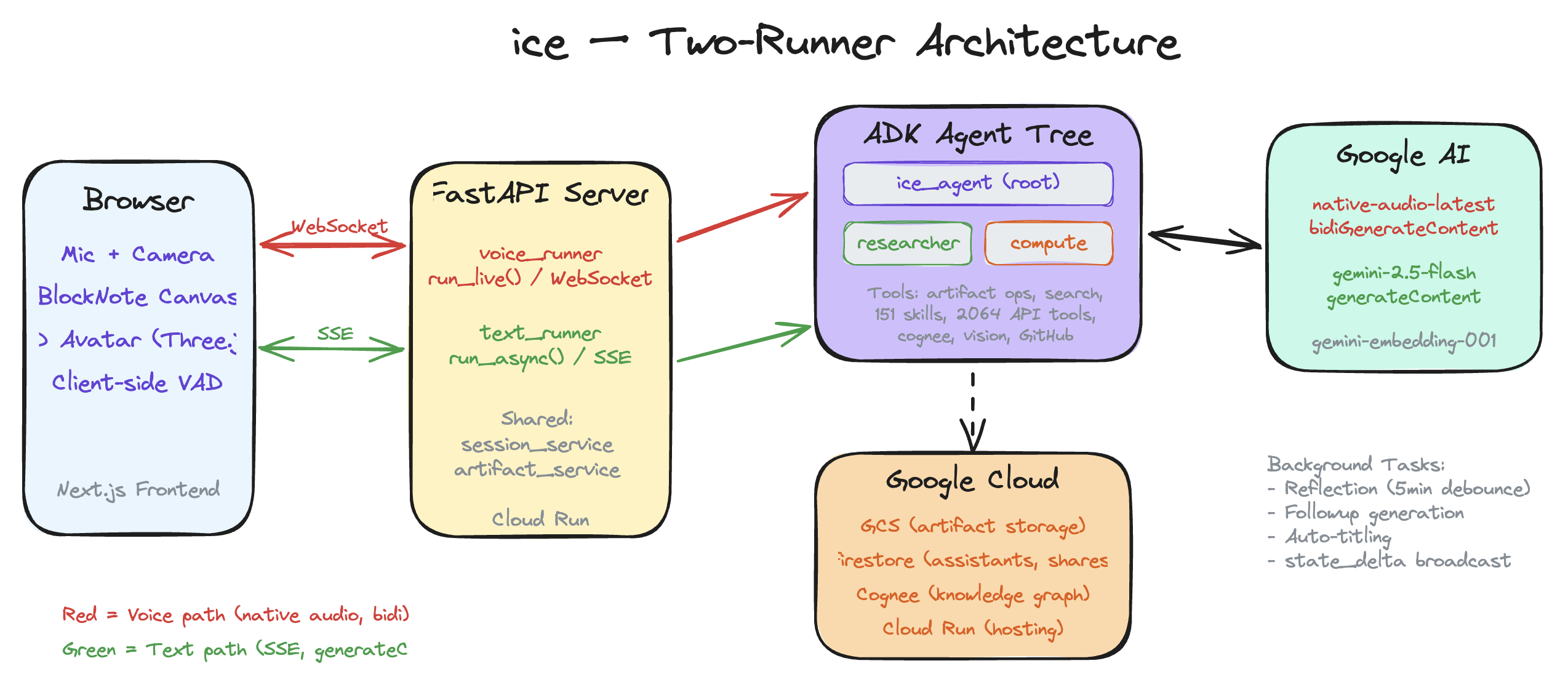
Native audio and text models cannot share a runner. For the video call to support both voice conversation and canvas text editing, we needed both bidiGenerateContent and generateContent. Mixing them in one runner caused 404 errors. We built a Two Runner architecture: voice_runner (WebSocket, run_live) and text_runner (SSE, run_async) sharing session and artifact services but each owning an independent agent tree built by the same _build_agents(model_fn) factory.
62K characters of XML crashes native audio sessions. ADK's SkillToolset appends all 151 skills as XML to the system instruction. The native audio model rejects this outright with error 1008. We subclassed it into _LiveSkillToolset which injects a compact one line per skill summary. Most of the time here was spent figuring out why sessions kept dying, not on the fix itself.
Quick actions are incompatible with live voice. The one click rewrites (fix grammar, simplify, translate) rely on a before_model_callback that only fires in run_async(), never in run_live(). We built a Two Path architecture: SSE mode injects the prompt template via callback; voice mode intercepts the request, makes a direct generate_content() call server side, and writes the artifact update to session state via EventActions, bypassing the live model entirely.
Gemini SSE sends function calls atomically. When the agent generates a 4,000 character artifact, the canvas stays blank until the model finishes. For a medium where you need to see thought take shape, that breaks the experience. We built progressive chunking: splitting function call content into 80 character partialArgs SSE events. A 3,864 character rewrite now streams as 98 chunks, rendering as it is generated.
Accomplishments that we're proud of
Thought outside the head, not just text on a screen. Artifacts embed both voice and visuals such that they can speak to you and modify themselves. Ask it to embed a 3D protein structure or a Mermaid diagram, and it modifies just that portion of the artifact, while letting you add a voice note over it. If you think ice computed with the wrong method, let the agent sandbox handle the recomputation while you continue talking about the multimodal representation.
~2,000 scientific tools, and the canvas to match. Manipulate artifacts with almost all scientific skills and tools on the internet and extend further with global shared memory. Choose to index specific artifacts or entire chats into the knowledge graph and search what others are indexing. The reflection agent silently runs in the background, storing your personal memory on ADK.
Getting past local maxima, together. Share your long chats with others and let the AI scientist walk them through the work. If there is a 3D electron-electron scattering diagram, let them speak with Feynman and get a reproducible code pushed to their GitHub.
What we learned
Voice and text are different mediums, not different channels. They are fundamentally different API surfaces (bidi vs. unary) that need separate runners sharing a session. Every time we tried to shortcut this, something broke. The same applies to UX: audio generation outpaces playback (101 chunks in 1.47 seconds for 5 seconds of audio), so barge in had to move client side, and artifact streaming needed progressive chunking. The model is fast enough; the protocol just was not designed for a medium where you need to see and hear thought in real time.
Artifacts need to be collaborative primitives, not static outputs. By storing ArtifactV3 in session state and broadcasting as state_delta events, the frontend never polls. Every tool call atomically updates persistence and UI. The append only contents array with currentIndex branching gives undo/redo for free. This was not our original design; we arrived at it after trying several worse approaches.
Sharing is what turns a tool into a medium. The fork architecture (copying messages, artifacts, and reflections with _fork_source injected) means a forked session has all original context without being coupled to it. This is what makes "let Feynman walk you through it" possible: anyone forks a session and immediately has an AI scientist with full context of the original thinker's work.
What's next for ice
From forking to co-editing. The current share/fork creates a point in time copy. The next step toward dynamic multimodal literacy is live co-editing: multiple users on the same session with state deltas broadcast to all WebSockets. The primitives are already there; the missing piece is a pub/sub layer to fan out to co-editors.
A knowledge graph that thinks like a scientist. Today Cognee uses per user and global node sets. Next, when you index a protein structure, ice should automatically link it to UniProt IDs, PDB entries, and reaction pathways. The global graph becomes a living scientific knowledge base that every ice user contributes to and searches.
Your own AI scientist. A "Feynman" with QED pedagogy, a "Pauling" with structural chemistry priors, a "Turing" with theoretical CS context, each carrying their own Cognee node_set, voice, 3D avatar, and reflection history. Users publish and subscribe to community built personas the same way they share sessions. The medium fits the human.
Built With
- adk
- agentenginesandboxcodeexecutor
- firestore
- gemini-live-api
- google-cloud
- python
- react
- three.js





Log in or sign up for Devpost to join the conversation.