
ahoussemdev: AI-Powered Document Intelligence
💡 Inspiration
We live in an era of information overload. Businesses and individuals are drowning in PDF contracts, technical manuals, and research papers. The traditional method of "Ctrl+F" is brittle and fails to understand context.
I was inspired to build iahoussemdev to bridge the gap between static documents and dynamic knowledge. I wanted to create a tool that doesn't just "search" text, but understands it, allowing users to converse with their documents as if they were speaking to the author.
🧠 What it does
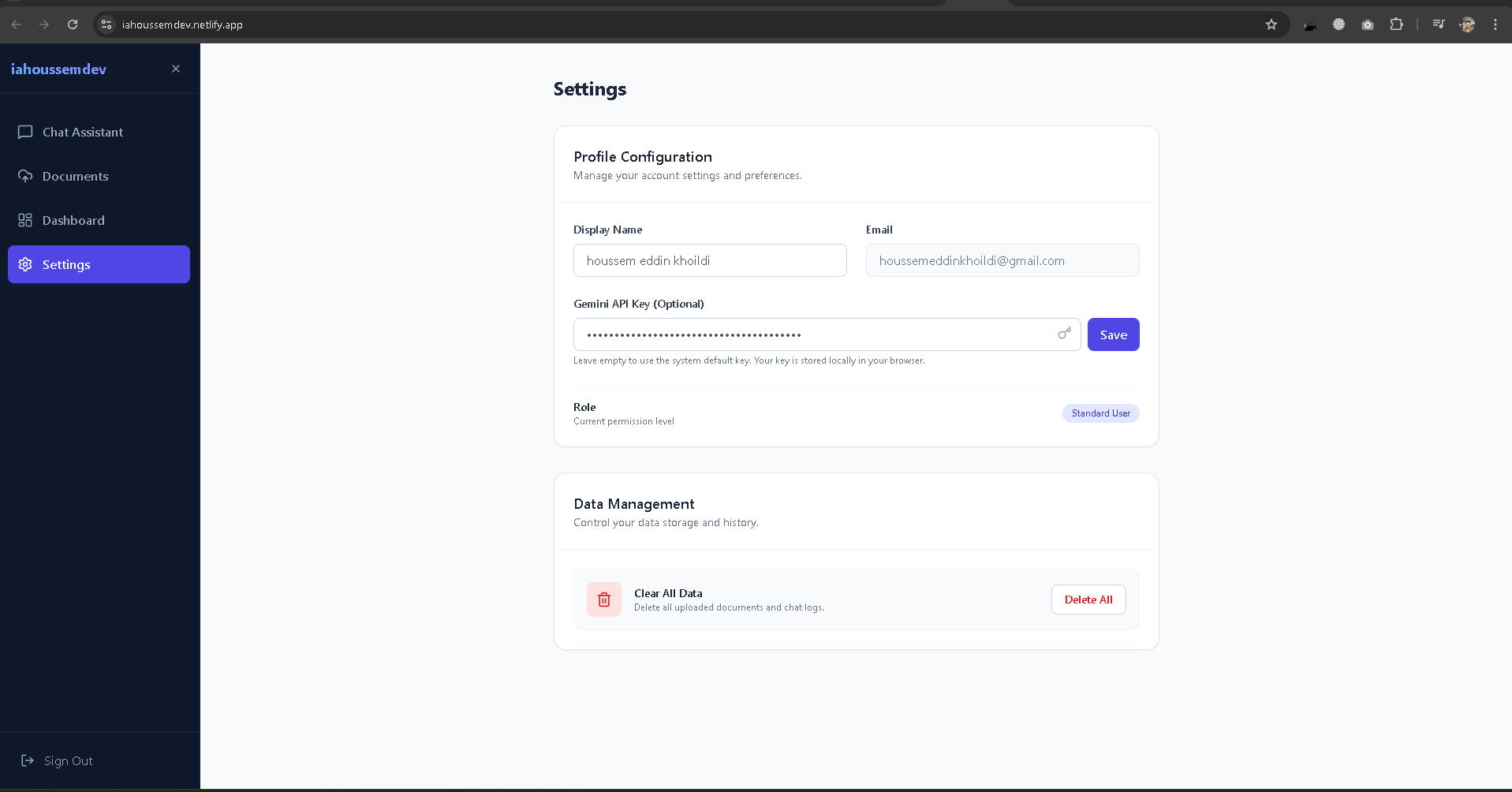
iahoussemdev is a full-stack web application that transforms static PDF files into interactive AI assistants.
Upload: Users drag and drop PDF documents.
Process: The app extracts text client-side using pdf.js.
Analyze: It uses the Google Gemini API to understand the content.
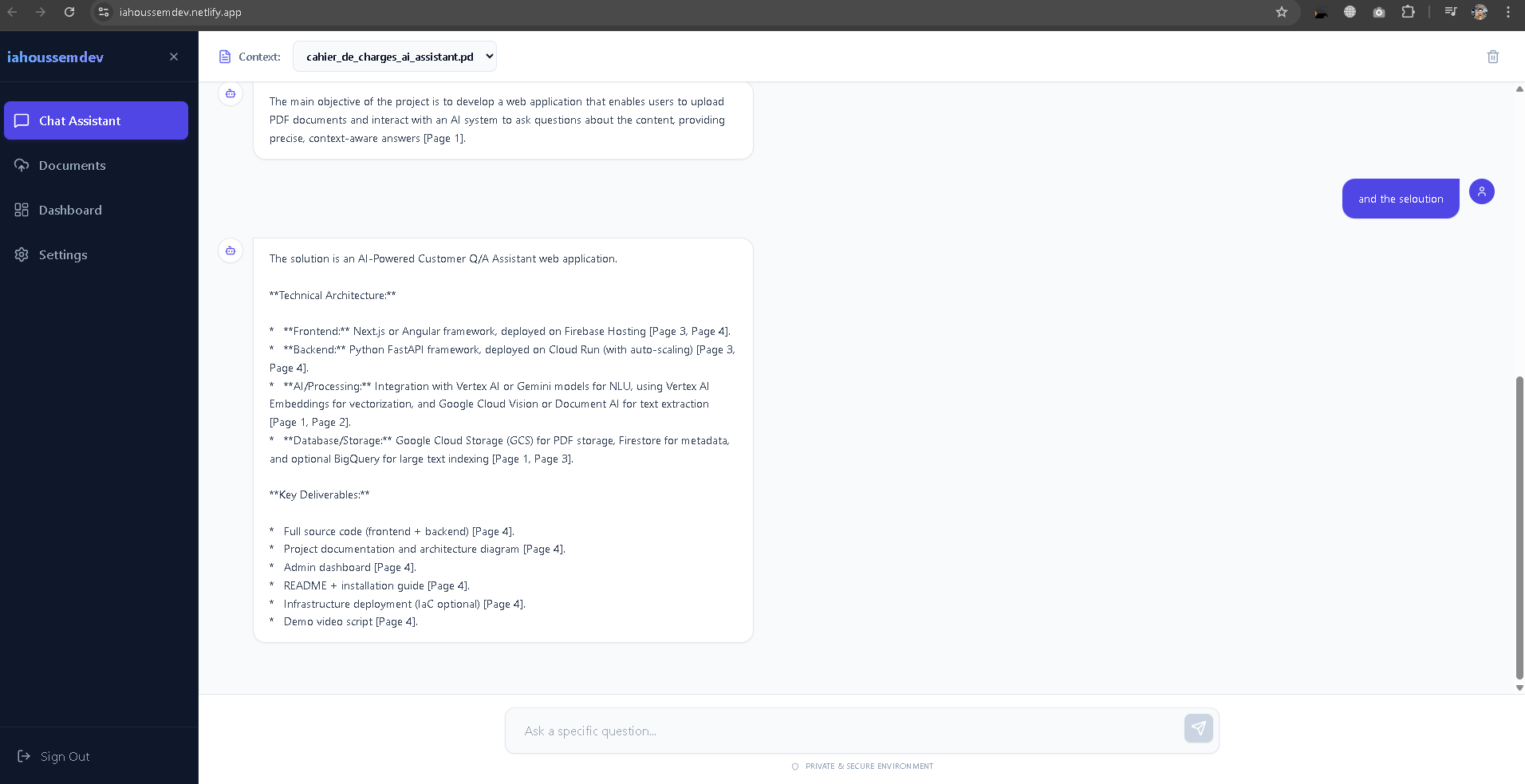
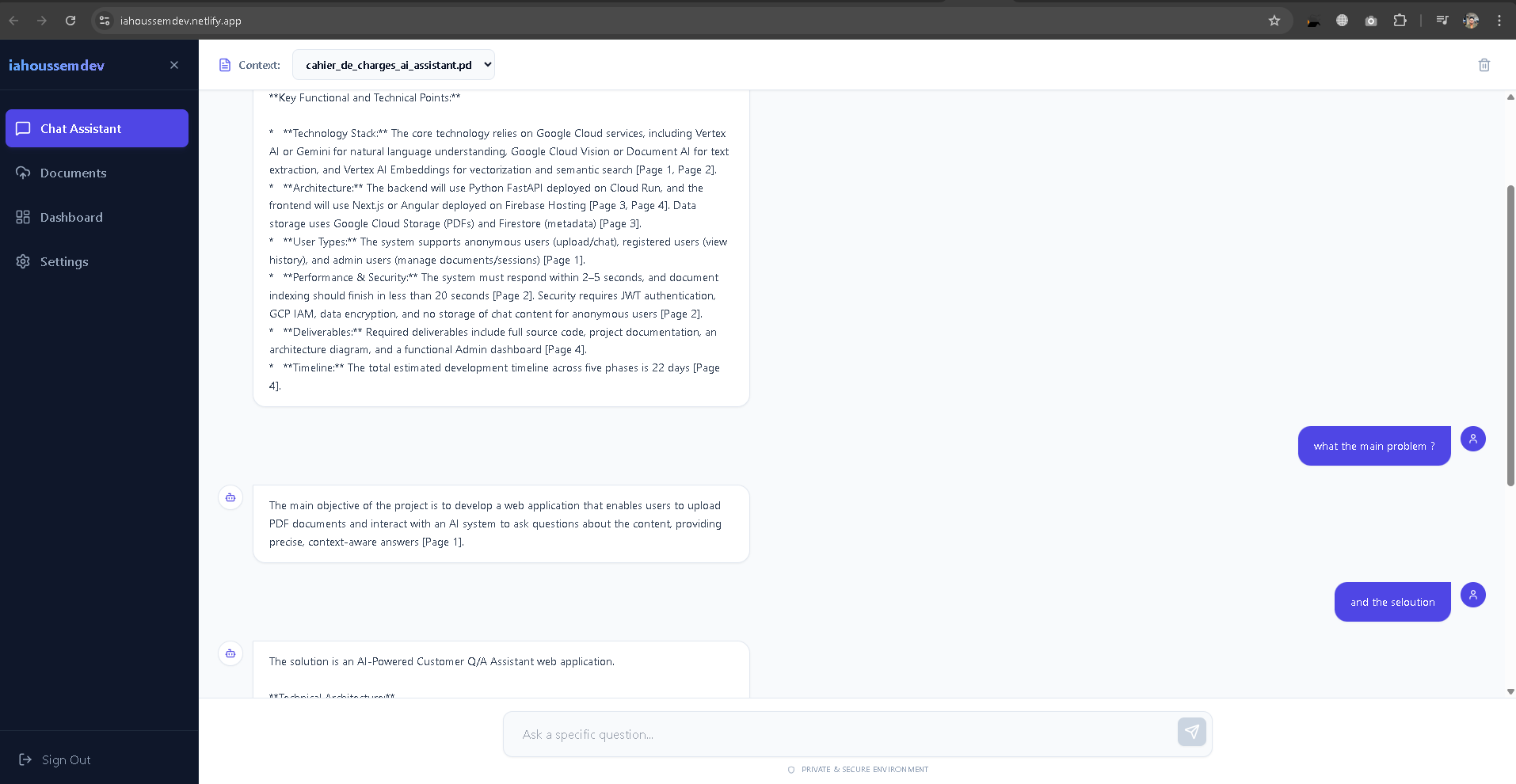
Chat: Users ask natural language questions, and the AI responds with precise answers based only on the document context, citing sources where possible.
⚙️ How we built it
We adopted a modern Serverless RAG (Retrieval-Augmented Generation) architecture to ensure speed and scalability.
Frontend: Built with React and Vite for a lightning-fast user experience. We used Tailwind CSS for a sleek, responsive, professional UI that works on mobile and desktop.
The AI Engine: We integrated Google's Gemini 2.5 Flash model. We chose this model for its massive context window and low latency. The application constructs a prompt dynamically:
$$P(Answer | Context, Query)$$
Where the Context is the extracted PDF text and the Query is the user's question.
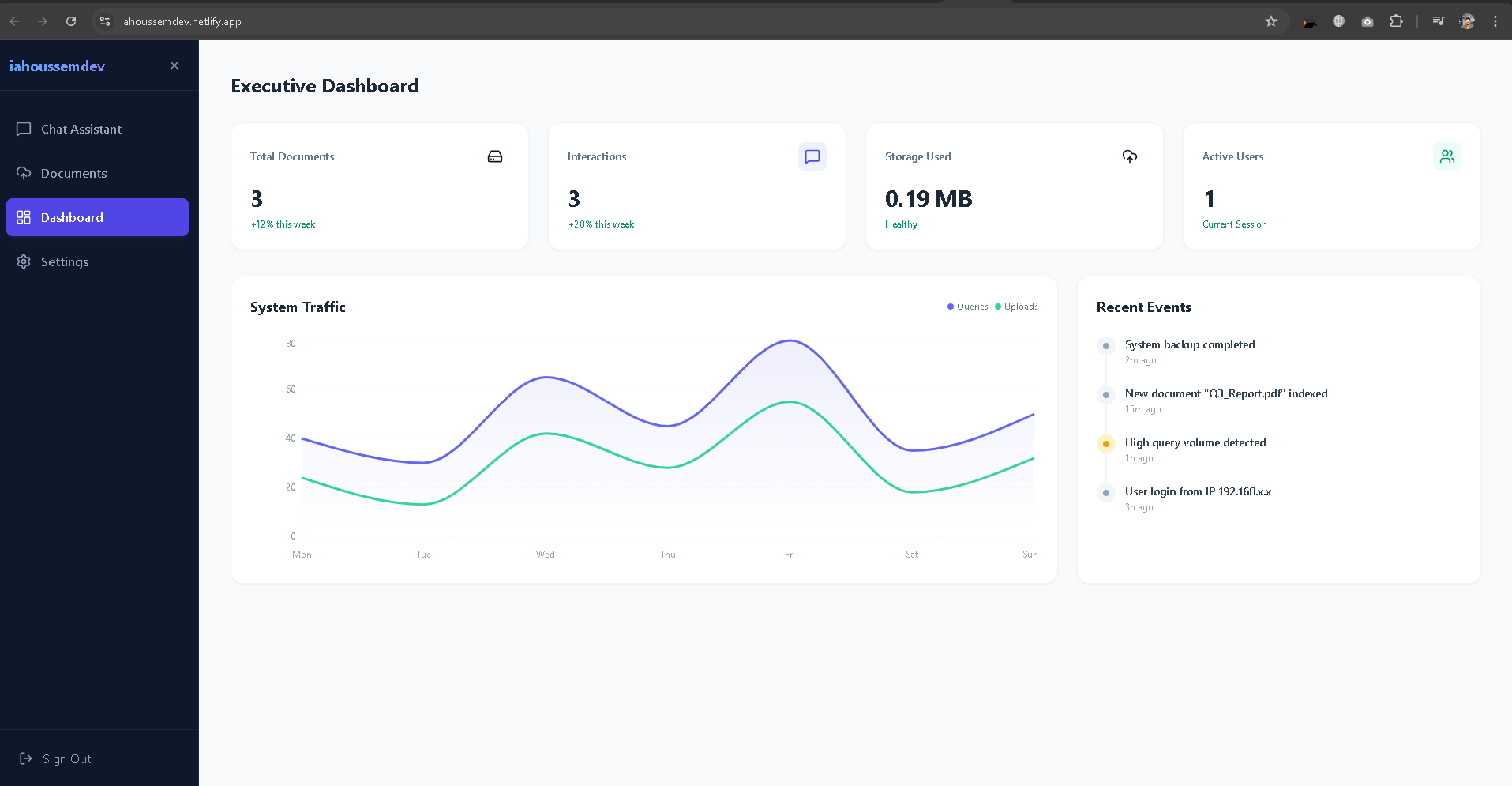
Data Persistence: We utilized Firebase Firestore to store chat history, document metadata, and user sessions in real-time.
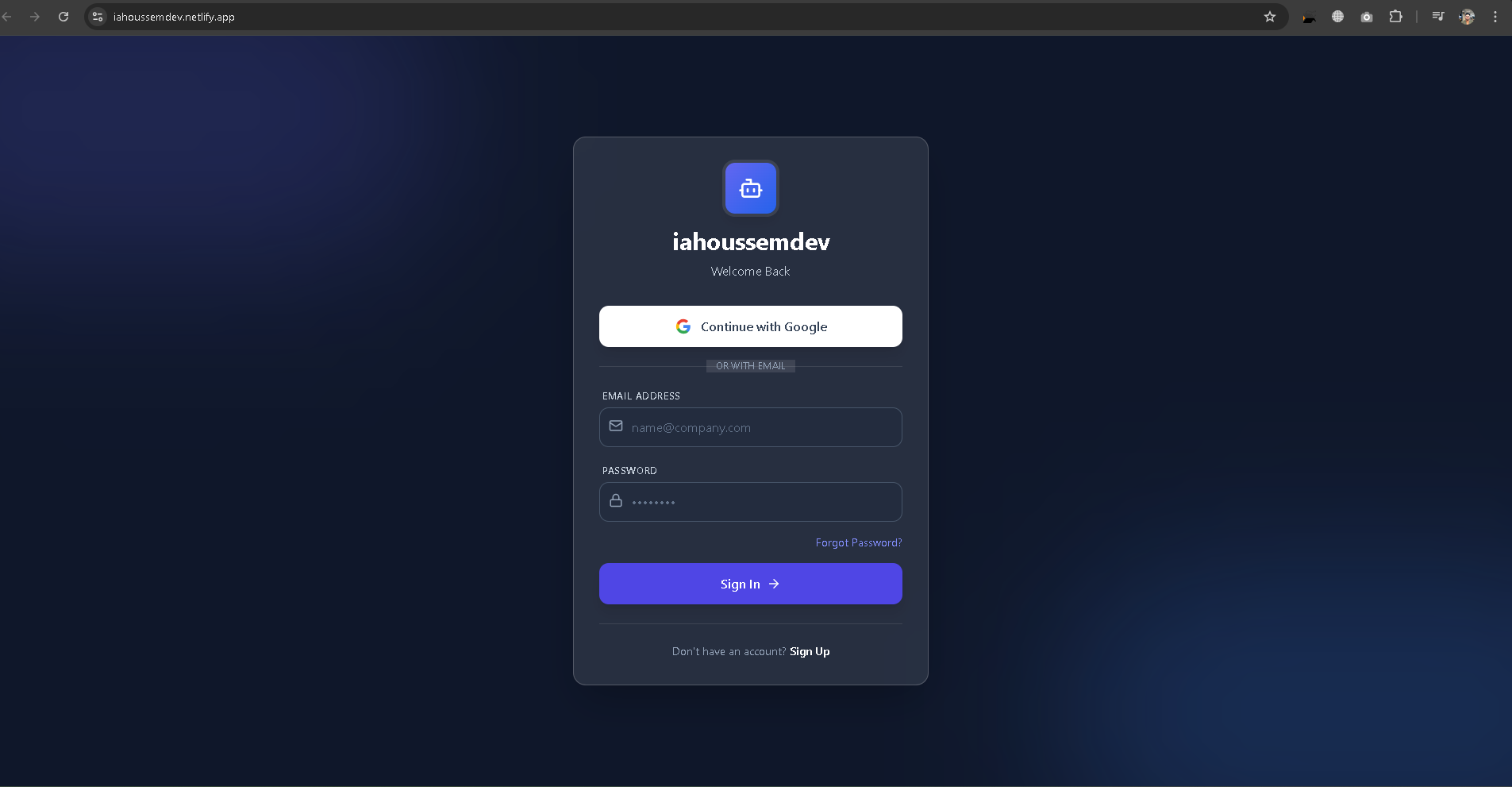
Authentication: Secure Firebase Authentication handles user identity, supporting both Email/Password and Google Sign-In flows.
Client-Side Processing: Instead of heavy server-side OCR, we used pdf.js to parse text directly in the user's browser, ensuring data privacy and reducing server costs.
🚧 Challenges we faced
Context Window Limits: Handling large PDFs was tricky. We had to optimize text extraction to ensure we provided Gemini with the most relevant sections without hitting token limits.
Browser Security: Implementing Google Sign-In inside a modern web environment triggered Cross-Origin-Opener-Policy issues, which we solved by configuring Firebase Auth domains correctly.
State Management: synchronizing the chat UI with Firestore real-time updates while maintaining input focus was a complex UX challenge that required careful component restructuring.
📚 What we learned
Prompt Engineering: We learned how to strictly instruct the LLM to act as a "Customer Support AI" and avoid hallucinating facts not present in the source text.
Firebase Security: We gained deep insights into configuring authorized domains and securing API keys using environment variables (VITE_GEMINI_API_KEY).
Client-Side Performance: Optimizing the rendering of large lists and charts (using Recharts) taught us valuable lessons in React performance.
Built With
- analytics)
- data
- document
- firestore
- jsx-frameworks:-react
- libraries:
- lucide-react
- parsing)
- pdf.js
- recharts
- serverless-stack:-languages:-javascript-(es6+)
- this-project-leverages-a-modern
- visualization)
- vite-styling:-tailwind-css-ai-&-ml:-google-gemini-api-(gemini-2.5-flash)-cloud-&-database:-google-firebase-(auth
Log in or sign up for Devpost to join the conversation.