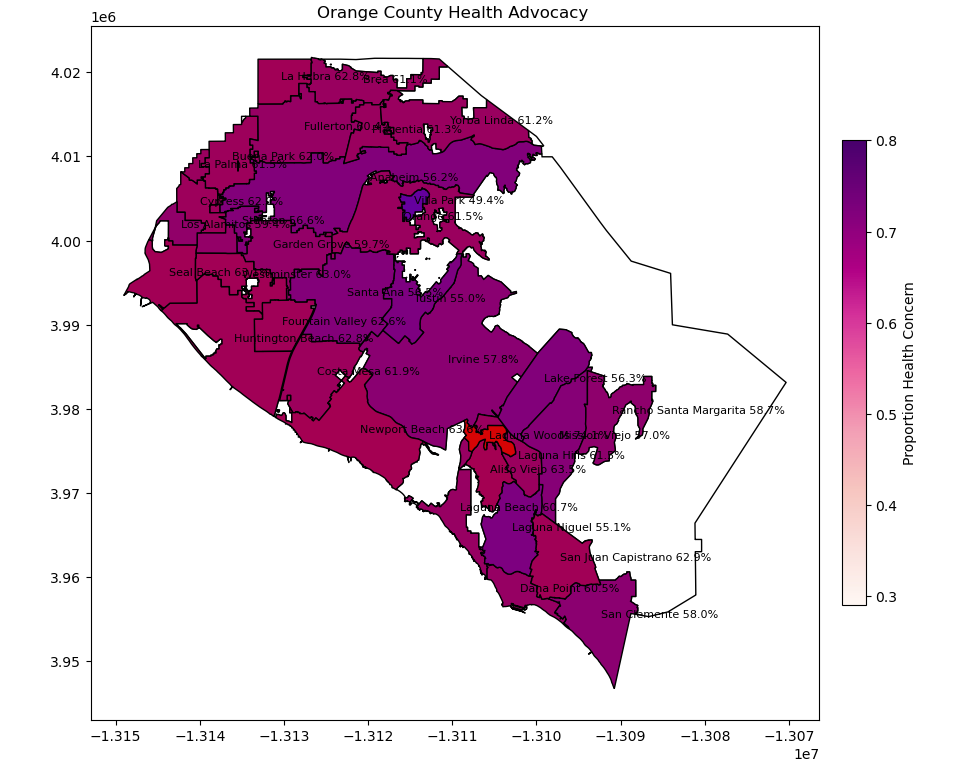

Overview
How important is health to residents of Orange County? Are the hobbies that people can partake in correlated with a greater interest in one's own health? We developed a machine learning model that predicts how likely an Orange County resident is to prioritize their own health with a 77% confidence rate. In addition, we created multiple graphs to visualize the relationship between hobbies and other various external factors.
The Dataset
We related the Consumer Dataset from Melissa Developer to determine whether or not people care about their health. Within the Melissa Consumer Dataset there are 42 million pieces of sociodemographic data (~289 mb) about citizens in Orange County.
Cleaning Data
We subset factors that we believed directly related to OC residents' health, such as photography, fishing, DIY projects, etc. First, we removed any columns that had too many null values and those that were irrelevant to our target value. Through extensive model hyperparameter tuning we carefully optimized selected factors that would reveal an individual's predisposition for caring about their health.
Processing Data
We used the Tensorflow and Keras libraries to create a logistic regression binary classification model and a simple neural network. We used 75% of the data to train the model and 25% to test the model. We achieved an initial model accuracy of 60%. After fine tuning the iteration and batch size of the model, we were able to achieve a final accuracy of 77%.
Challenges
Our initial project choice was the Dublin, Ireland Airbnb challenge from Stratascratch. After working on it for 5 hours, we realized that we could not make accurate conclusions based on this dataset and looked for new possibilities and settled on the Melissa Consumer dataset. Our determination and tenacity to succeed helped us overcome our mental blocks and push through the mental fog that comes with any data analysis project.
Accomplishments that we're proud of
We are extremely proud of our machine learning model with which we were able to achieve an almost 80% success rate in predicting the prioritization of health of Orange County residents.
What we learned
- Effectively communicate findings with visualizations and machine learning models.
- Adapting and overcoming adversity as well as learning from our mistakes
- Learned new libraries such as geo-pandas to map spacial data in conjunction with other visualization tools
Future Directions
- Allocate health resources to areas that have a lower percentage of people caring about their health
- Create opportunities for people to partake in hobbies as this will increase the possibility of individuals prioritizing their health
Built With
- geopanda
- matplotlib
- pandas
- python
- scikit-learn
- seaborn
- tensor





Log in or sign up for Devpost to join the conversation.