-
-

J.A.R.V.I.S v0.0.1beta
-
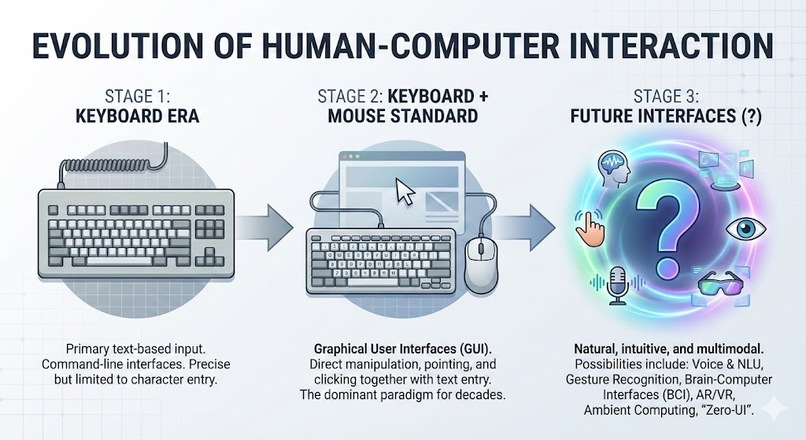
Toward a multimodal world

Inspiration

The paradox of modern computing: I communicate naturally with humans through voice, but interact with AI through typing. In January 2026, Google introduced Agentic Vision with Gemini 3 Flash—a vision of AI that doesn't just see the world, but acts upon it.
I built I.R.I.S. to realize this vision: an interface that doesn't wait for a prompt, but reacts to attention. By combining real-time gaze signals with the Gemini 3 Flash Agentic SDK, I've bridged the gap between visual context and autonomous action.
What it does
I.R.I.S. (Intent Resolution and Inference System) is a reactive agent that transforms your macOS environment into an attention-aware workspace. It uses your gaze as a high-bandwidth signal of intent, allowing you to interact with any UI element simply by looking and speaking.
Key Capabilities:
- Agentic Vision: Continuous multimodal analysis of your screen to proactively offer "Agentic Skills" (Refactoring, Summarization, Bug Fixing) before you even ask.
- Precision Action via TARS: Overcomes the "coordinate hallucination" of LLMs by using a dedicated TARS action server to execute pixel-perfect clicks, scrolls, and typing.
- Contextual Awareness: Automatically detects "chat-like" apps or IDEs to tailor its reasoning and suggestions to your current task.
The Flow: Look at an issue → Say "Fix this" → I.R.I.S. analyzes via Gemini 3 Flash Agentic SDK → The Agentic Loop plans the resolution → TARS executes the action.
How I built it
I.R.I.S. is a multi-layered system designed for low-latency feedback and high-precision execution:
The Intelligence Stack:
- Gemini 3 Flash Agentic SDK: The core "brain" powering the Agentic Loop. It enables native function calling and tool use, allowing the model to interact with the OS, search the web, and manipulate files autonomously.
- TARS Action Server: A specialized execution layer that translates natural language instructions into concrete screen actions (Click, Drag, Type, Hotkey), ensuring reliability where standard LLMs fail.
- Agility KSTK (Knowledge Stack): The foundational gaze and vision models (including the KSTK/LBF weights) that provide high-speed facial landmark detection and gaze estimation.
The Framework Architecture:
- IRIS Gaze (Rust & Swift): A high-performance bridge to the
iris-gaze-rslibrary for real-time tracking. - IRIS Vision: Local OCR and Accessibility API integration for semantic screen mapping.
- IRIS Media: A custom audio/video pipeline for real-time "Live" multimodal sessions.
Challenges I ran into
The Precision Gap: Standard LLMs struggle to map "Look at that button" to exact screen coordinates. I solved this by architecting TARS, which treats the screen as a navigable environment rather than just a static image.
Latency & Fluidity: Maintaining 60 FPS gaze tracking while streaming multimodal data required a strict modular separation. By offloading gaze estimation to a Rust-based core and using the Agentic SDK for asynchronous tool execution, I kept the interaction loop tight and responsive.
State Management: Handling "Proactive" mode without being intrusive. I implemented cooldowns and "chat-app detection" so I.R.I.S. only nudges you when it detects a genuine interaction opportunity.
Accomplishments that I'm proud of
- Agentic Vision Realization: Building one of the first macOS implementations of the Gemini 3 Flash agentic loop.
- TARS Integration: Moving from "AI that talks" to "AI that clicks" with pixel-perfect accuracy.
- KSTK Foundations: Leveraging advanced LBF models for stable gaze tracking even in challenging lighting.
What I learned
- Gaze is the Ultimate Filter: By knowing where a user looks, I can prune 90% of the "noise" on a screen, making LLM tool-calling significantly more accurate.
- The Hybrid Approach: Real-world agents need a mix of cloud reasoning (Agentic SDK) and local precision (TARS/KSTK) to be useful.
What's next for I.R.I.S.
The "Infinite Skill" Paradigm: The next phase of I.R.I.S. is the transition to a single, recursive capability: The Meta-Skill. Instead of shipping a fixed menu of features, I.R.I.S. will have only one core directive: The Skill to Learn and Create New Skills.
When I.R.I.S. encounters a task it hasn't seen before, it will use the Agentic SDK to:
- Analyze the user's intent and visual workflow.
- Synthesize a new Skill definition (logic, instructions, and TARS-action patterns).
- Persist that skill into my registry for future use.
The Vision: I.R.I.S. will become an infinite system that grows alongside the user without any further development—moving from a predefined tool to a self-evolving interface. From gaze to intention to infinite action.
Like in my dream back to June 2024: https://blog.liviogama.com/dreaming-a-potential-future-for-spatial-computing

Log in or sign up for Devpost to join the conversation.