-
-
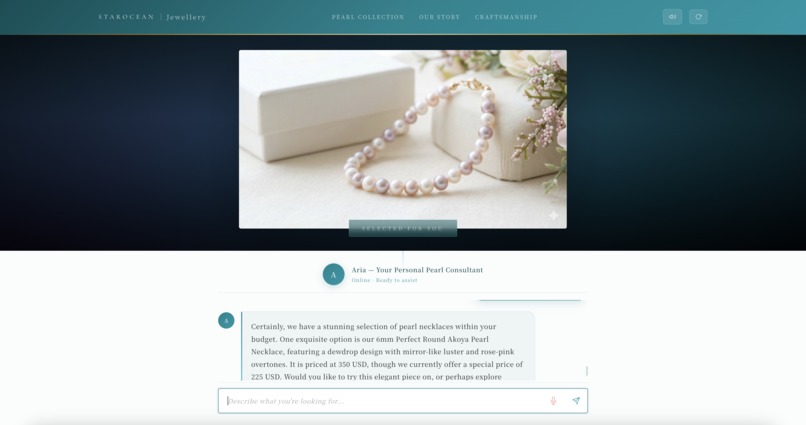
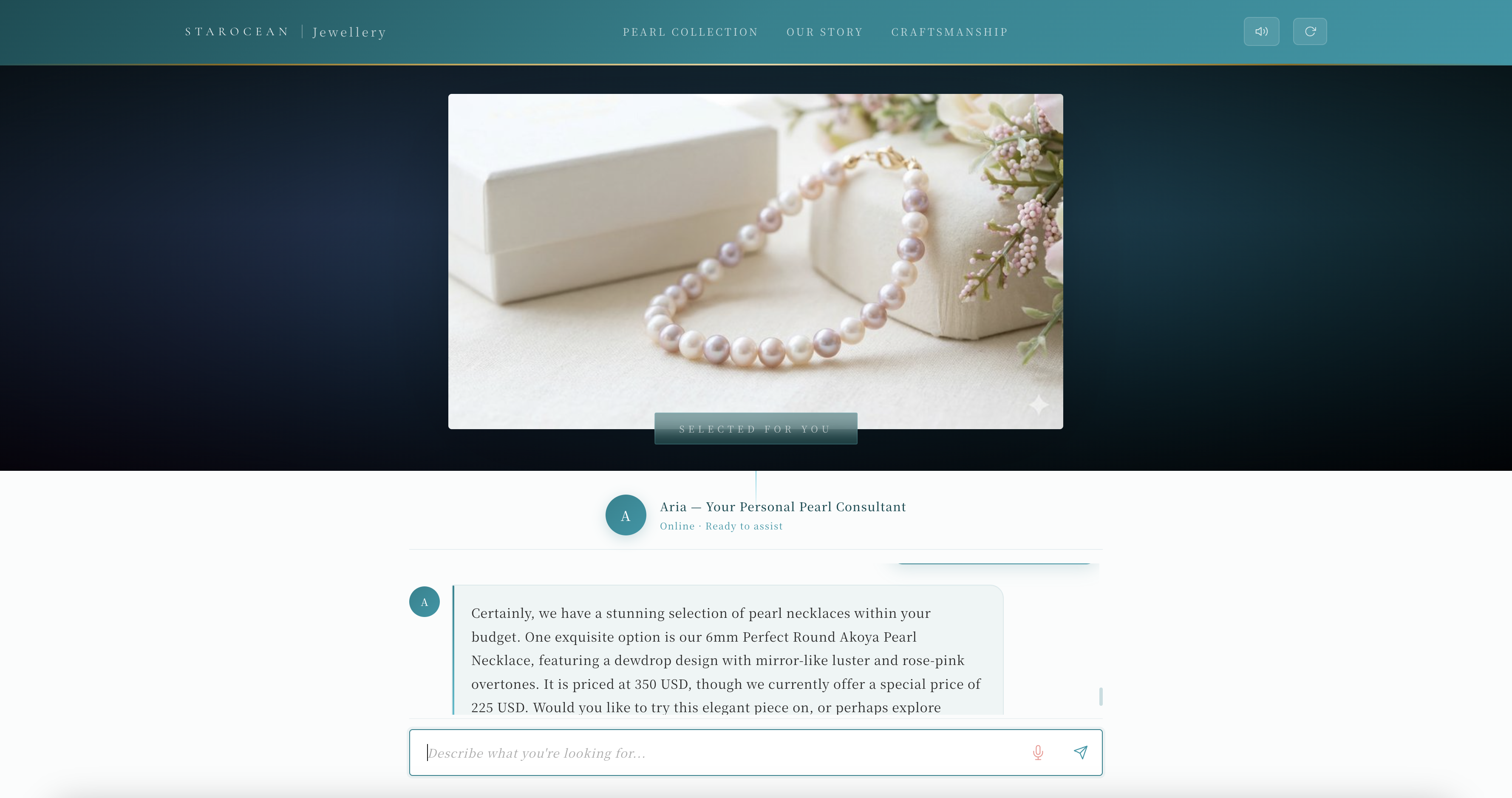
Aria_Web_App_View
-
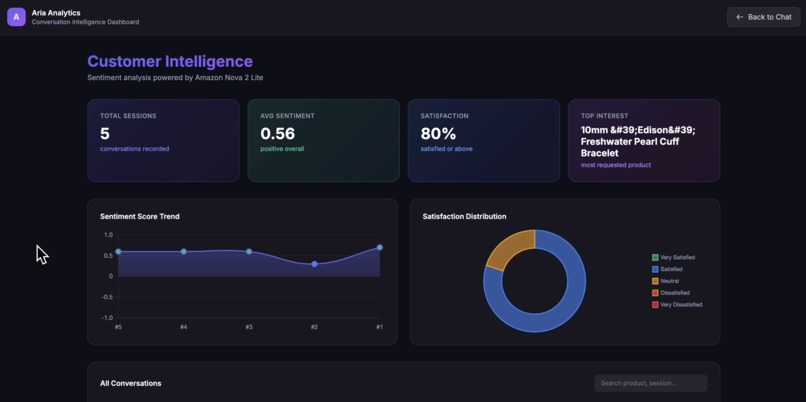
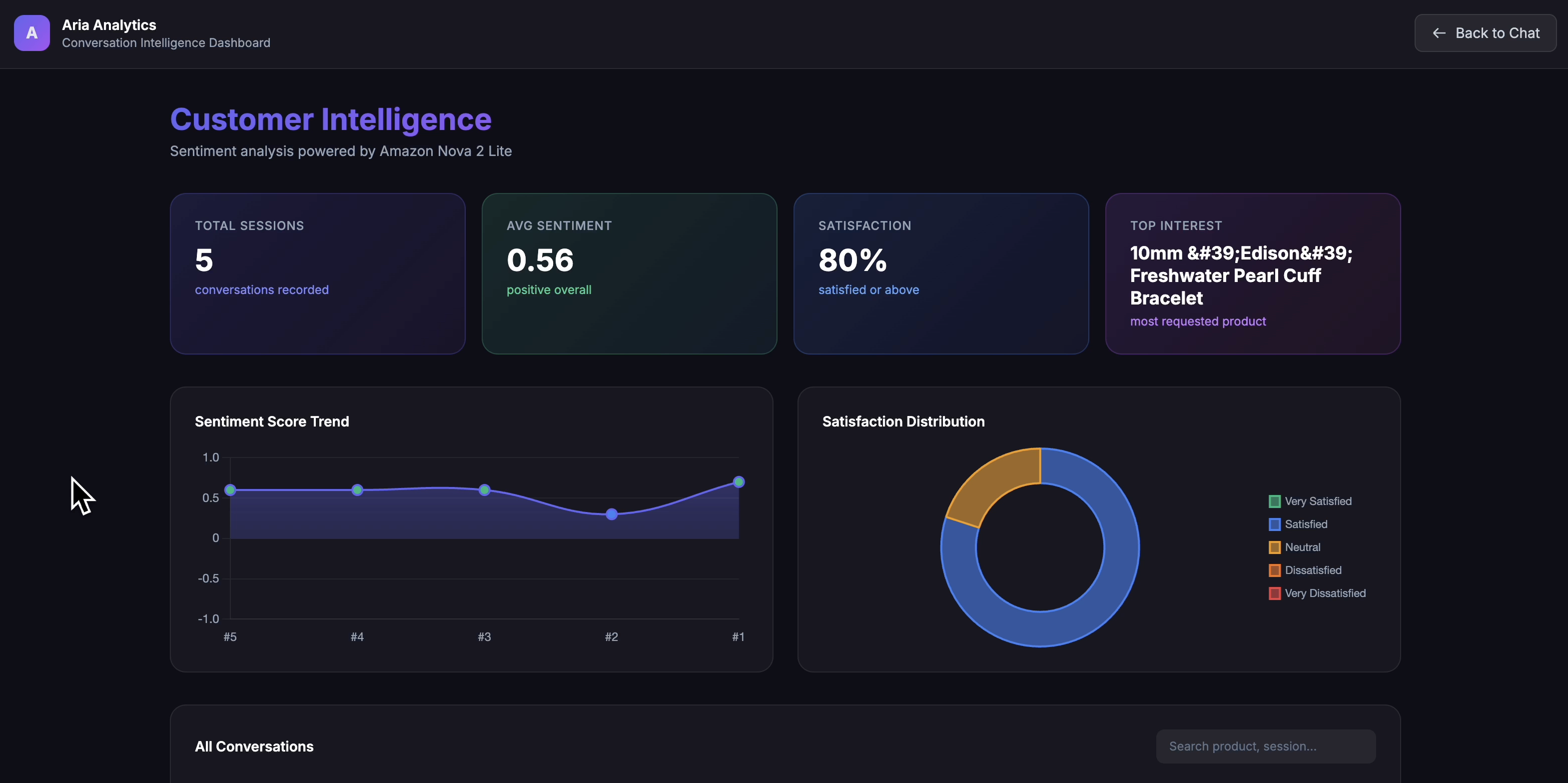
Conversation Sentiment Analysis Dashboard
-

Aria

Aria — AI Sales Assistant
Inspiration
The luxury retail industry still relies heavily on in-person consultations — a knowledgeable salesperson who can read a customer's intent, recall the entire catalog, and present the right product at the right moment. We asked: what if an AI could do this, but with the added superpower of understanding both language and images simultaneously?
Most e-commerce chatbots today are text-only. They can answer questions, but they can't see the products they're selling. A customer who asks "something elegant for a black-tie dinner" deserves to see the perfect piece — not just read a description of it. That gap between text understanding and visual product knowledge inspired Aria.
We wanted to build a sales consultant that genuinely understands the relationship between what a customer says and what a product looks like — powered entirely by Amazon Nova.
What It Does
Aria is an AI-powered pearl jewelry sales consultant that combines multimodal understanding with retrieval-augmented generation (RAG) to deliver a luxury shopping experience:
- Understands natural language queries and retrieves the most relevant products from a catalog of 10 pearl jewelry items
- Semantically matches product images to the conversation — when Aria recommends a Tahitian pearl pendant, the actual product image appears automatically
- Streams responses in real-time via Server-Sent Events (SSE) for a fluid conversational feel
- Speaks its responses aloud using Amazon Polly Neural TTS with sentence-level progressive playback
- Analyzes customer sentiment in real-time using Nova Lite, tracking satisfaction and product interest across conversations
- Presents an analytics dashboard showing conversation history, sentiment trends, and customer insights
How We Built It
Multimodal RAG Pipeline
The core of Aria is a multimodal RAG pipeline that operates in a unified 1024-dimensional vector space where both text and images coexist:
1. Indexing Phase (offline)
We embed the entire product catalog — both text chunks and product images — into a shared semantic space using Amazon Nova Multimodal Embeddings (amazon.nova-2-multimodal-embeddings-v1:0):
- Product descriptions are chunked (800 characters, 100-character overlap) and embedded as text vectors
- Each product image (10 JPGs) is independently embedded as an image vector
- Both sets of vectors are L2-normalized and cached to disk as a pickle file (~80KB)
2. Query Phase (real-time)
When a customer asks a question:
- The query is embedded via Nova Multimodal Embeddings
- Text retrieval: cosine similarity against text chunk vectors → top-3 product descriptions injected as context
- Image retrieval: cosine similarity against image vectors → best-matching product image displayed in the UI
- The retrieved context, conversation history, and system prompt are passed to Amazon Nova Lite (
amazon.nova-lite-v1:0) via the Bedrock Converse API
3. Response Generation
Nova Lite generates a response streamed token-by-token via the ConverseStream API. The frontend receives tokens via SSE and renders them progressively. As complete sentences form, each is sent to Amazon Polly for TTS synthesis — audio clips play back in strict sentence order using a slot-based queue.
Sentiment Analysis
After each conversation turn, Aria sends the full dialogue to Nova Lite with a structured analysis prompt. The model returns a JSON object with:
- Sentiment score ($-1$ to $+1$)
- Qualitative analysis (50-word summary)
- Customer satisfaction (5-point scale)
- Product interest (specific items mentioned)
If the LLM call fails, a keyword-based heuristic fallback ensures the analytics pipeline never breaks.
Architecture
User (Browser)
│
├── Web Speech API (STT) ──► Text query
│
▼
Flask API (Gunicorn, gthread)
│
├── Nova Multimodal Embeddings ──► Query vector (1024D)
│ │
│ ├── Cosine similarity vs. text vectors ──► Top-K context chunks
│ └── Cosine similarity vs. image vectors ──► Best product image
│
├── Nova Lite (Converse / ConverseStream API)
│ └── Streamed response with RAG context
│
├── Nova Lite (Sentiment Analysis)
│ └── JSON sentiment + satisfaction + product interest
│
└── Amazon Polly Neural TTS
└── Sentence-level MP3 audio ──► Ordered playback queue
Tech Stack
| Layer | Technology |
|---|---|
| LLM | Amazon Nova Lite via Bedrock Converse API |
| Embeddings | Amazon Nova Multimodal Embeddings (1024D) |
| TTS | Amazon Polly Neural (Joanna, en-US) |
| STT | Browser Web Speech API |
| Backend | Python / Flask / Gunicorn |
| Vector Search | NumPy (cosine similarity, in-memory) |
| Database | SQLite (conversation history + sentiment) |
| Deployment | Docker → Google Cloud Run |
| Frontend | Vanilla HTML/CSS/JS, Tailwind CSS |
Challenges We Faced
1. Cross-Modal Embedding Alignment
The biggest unknown going in was whether Nova Multimodal Embeddings would produce vectors where text queries and product images are meaningfully comparable. A query like "something for a wedding" needs to land close to an image of delicate pearl drop earrings — not just close to the text description of those earrings. We found that Nova's unified embedding space handles this remarkably well, with a similarity threshold of just 0.15 being sufficient to reliably surface the correct product image.
2. Streaming TTS with Sentence Ordering
Streaming LLM tokens and generating TTS audio per-sentence introduces a concurrency problem: sentence 3 might finish TTS synthesis before sentence 2. We solved this with a slot-based audio queue — each sentence reserves a numbered slot before the TTS fetch begins, and playback only advances when the next sequential slot is filled. This ensures audio always plays in the correct order regardless of network timing.
3. Credential Management Across Services
Aria uses multiple AWS services (Bedrock for LLM + embeddings, Polly for TTS) that require different authentication paths. In a containerized Cloud Run environment without instance profiles, we had to carefully separate credential flows — bearer token authentication for Bedrock and IAM credentials for Polly — without one interfering with the other.
4. Cold Start Optimization
Embedding 10 product images on every container startup would add 15-20 seconds of latency. We solved this by pre-computing all text and image embeddings at build time and shipping the vector cache (~80KB pickle file) inside the Docker image. The app starts and serves requests in under 2 seconds.
What We Learned
- Multimodal embeddings are production-ready. Nova Multimodal Embeddings produce a genuinely unified space where text and image similarity scores are directly comparable — no post-processing or calibration needed.
- Streaming changes the UX equation. The difference between waiting 3 seconds for a full response and seeing the first token in 200ms is enormous for perceived quality. Combined with progressive TTS, it makes the AI feel conversational rather than transactional.
- Sentiment analysis as a side-channel. Using the same LLM for both customer-facing dialogue and backend analytics (sentiment scoring) is cost-effective and surprisingly accurate — the model already has full conversational context.
- Simple vector search scales further than expected. For a 10-product catalog, in-memory NumPy cosine similarity with pre-normalized vectors is faster than any external vector database and adds zero infrastructure complexity.
What's Next
- Multilingual support — Aria already accepts language hints (Chinese, Japanese, Malay, French, German) and Nova Lite responds accordingly; we plan to add per-language Polly voices
- Video product demos — the UI already supports video playback; connecting product videos to the semantic matching pipeline is the next step
- Larger catalogs — moving from 10 to 1000+ products with approximate nearest neighbor search (FAISS or ScaNN)
- Fine-tuned sales persona — using conversation logs from the analytics dashboard to refine Aria's sales strategy over time

Log in or sign up for Devpost to join the conversation.