-
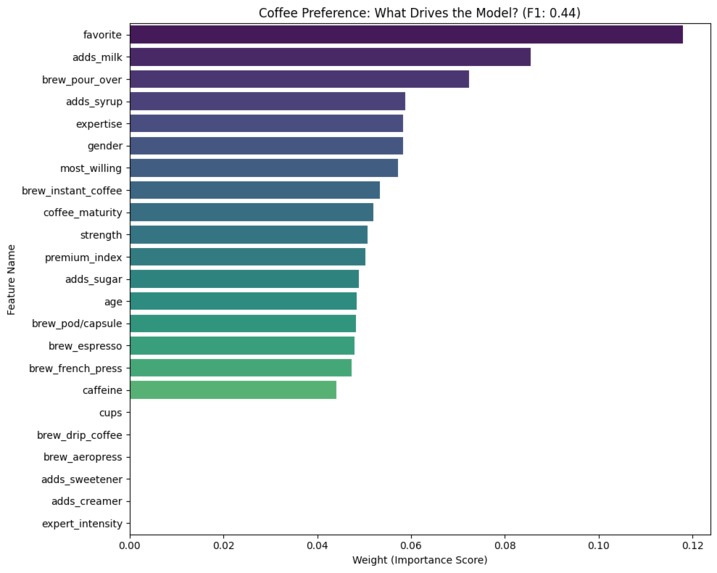
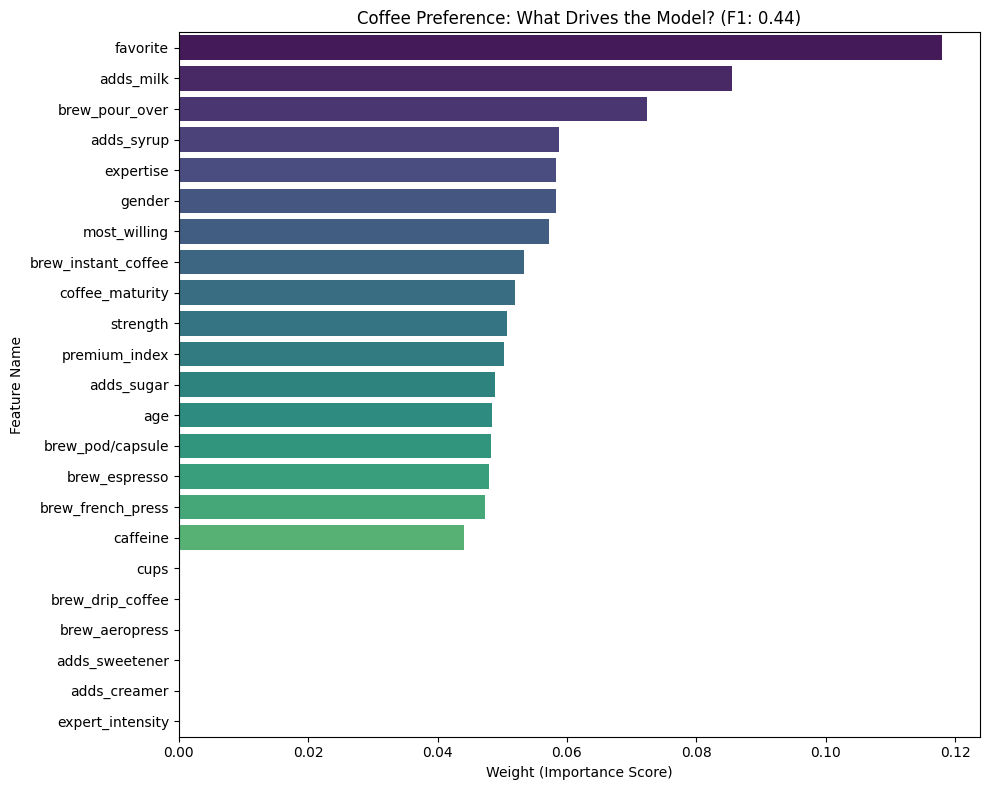
Key Features
-
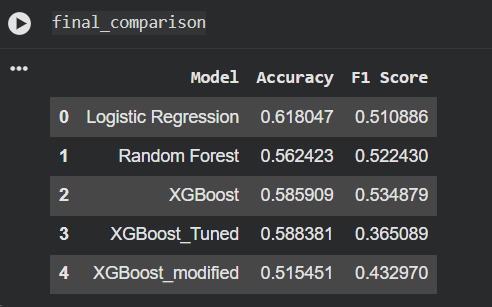
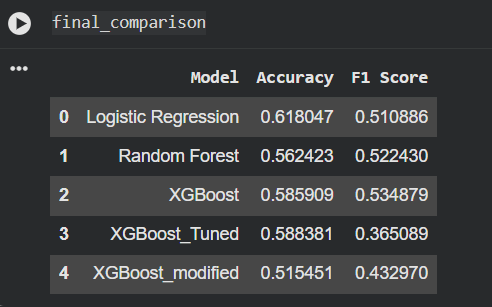
Model Comparision
-
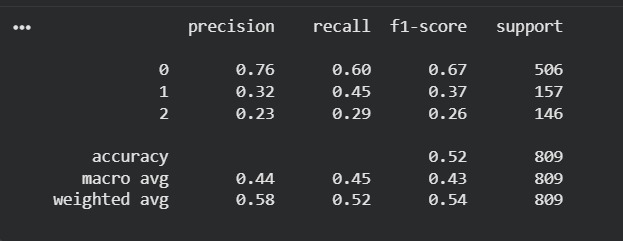
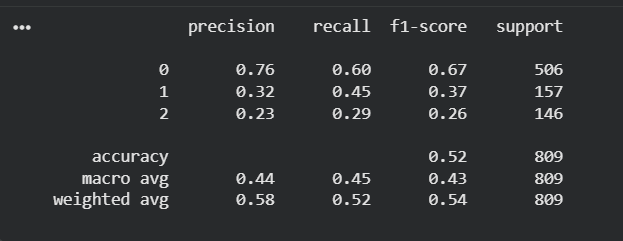
Classification Report of the Final model
Inspiration :
I noticed that most coffee subscription services use a one-size-fits-all approach, recommending roasts based on basic demographics like age or gender. As a coffee lover and data scientist, I knew that a 22-year-old student and a 60-year-old executive could share the same palate, yet traditional models would treat them differently. I wanted to build an engine that listens to behavior, not just birthdays.
What it does:
Bean Matched is a machine learning-powered recommendation engine that predicts a user's ideal coffee roast (Light, Medium, or Dark). By analyzing "psychographic" data—specifically how a user brews their coffee and their "Sweetened Behavior" (additions like milk and syrup)—the model identifies the specific profile of a drinker with high precision, moving away from demographic stereotypes to behavioral truth.
How we built it :
The project was built using a robust Python-based data science pipeline.
Preprocessing: Cleaned raw & messy survey data of public opinion into numeric form that the machine can understand. Handled missing values (specifically the "Age Leak" where missing ages were incorrectly influencing predictions).
Feature Engineering: Created a custom metric called sweetened_behavior ($S$) where:$$S = \text{adds_milk} + \text{adds_sugar} + \text{adds_syrup}$$ To capture the nuance of a Coffee Connoisseur, I moved beyond raw survey data and engineered three Super-Features that act as high-signal indicators for the model: Coffee Maturity ($M$): Combines age and expertise to find the Seasoned Palate: $$M = \text{age} \times \text{expertise}$$ Expert Intensity ($I$): Filters for Heavy Users who also possess high technical knowledge: $$I = \text{cups} \times \text{expertise}$$ Premium Index ($P$): Identifies high-value customers by linking price willingness with specialized espresso usage: $$P = \text{most_willing} \times \text{brew_espresso}$$
Model Selection: Implemented an XGBoost Classifier with custom class weighting to handle imbalanced target classes. I used James Hoffman Coffee Taste Dataset having 4000+ records of public opinions. Dataset : link
Challenges we ran into :
the biggest hurdle was the Accuracy Trap . My base model hit 58% accuracy, but a deep dive into the classification report showed it was almost entirely blind to Medium and Dark roast drinkers (Recall of only 0.05). It was achieving high accuracy by guessing the majority class (Light Roast). I had to make the difficult decision to lower the raw accuracy in exchange for a model that actually understood the entire market.
Accomplishments that we're proud of:
- Macro F1-Score Lift: Successfully increased the Macro F1-score from 0.32 to 0.44.
- Balanced Discovery: Boosted the recall for the Medium Roast class from 5% to 45%, making the model genuinely useful for multi-product inventory management.
- Feature Transparency: Identified that Brew Method and Milk Additions are significantly more predictive of roast preference than Age or Gender.
What we learned:
I learned that in real-world machine learning, higher accuracy isn't always better. A model with 52% accuracy that identifies all customer segments is far more valuable to a startup than a 58% model that ignores 40% of the audience. I also deepened my understanding of how Class Weights can be used to force an algorithm to care about minority data.
What's next for Bean Matched:
- Hyper-Personalization: Integrating a Taste Profile feature based on chemical acidity levels of different beans.
- Deployment: Turning the pickled model into a Flask-based API to power a real-time web recommendation quiz.
- Feedback Loop: Implementing a Reinforcement Learning layer where user feedback on recommendations retrains the model in real-time.
Built With
- google-colab
- matplotlib
- numpy
- pandas
- pickle
- python
- scikit-learn
- seaborn
- xgboost


Log in or sign up for Devpost to join the conversation.