-
-

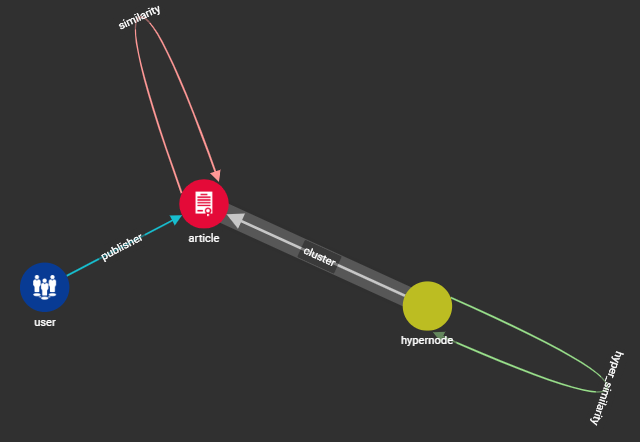
Graph Schema
-

Graph
-


Inspiration
Millions of people search for the news/articles/papers which are trending or viral on Google or similar search engines. But search engines start to repeat results after the third page. A big reason for this is duplicate resources from common sister agencies like Associate Press and all the newspapers that use its articles, as well as reshares or reposts, artificially inflate the volume of an article/post and its importance. Re-posts or re-shares often are also changed slightly, so Google does not see them as duplicates. This causes inflated importance of some posts (going “viral” unnecessarily) and gives a noisy Google search experience that may be hiding more relevant news articles from end-users.
What it does
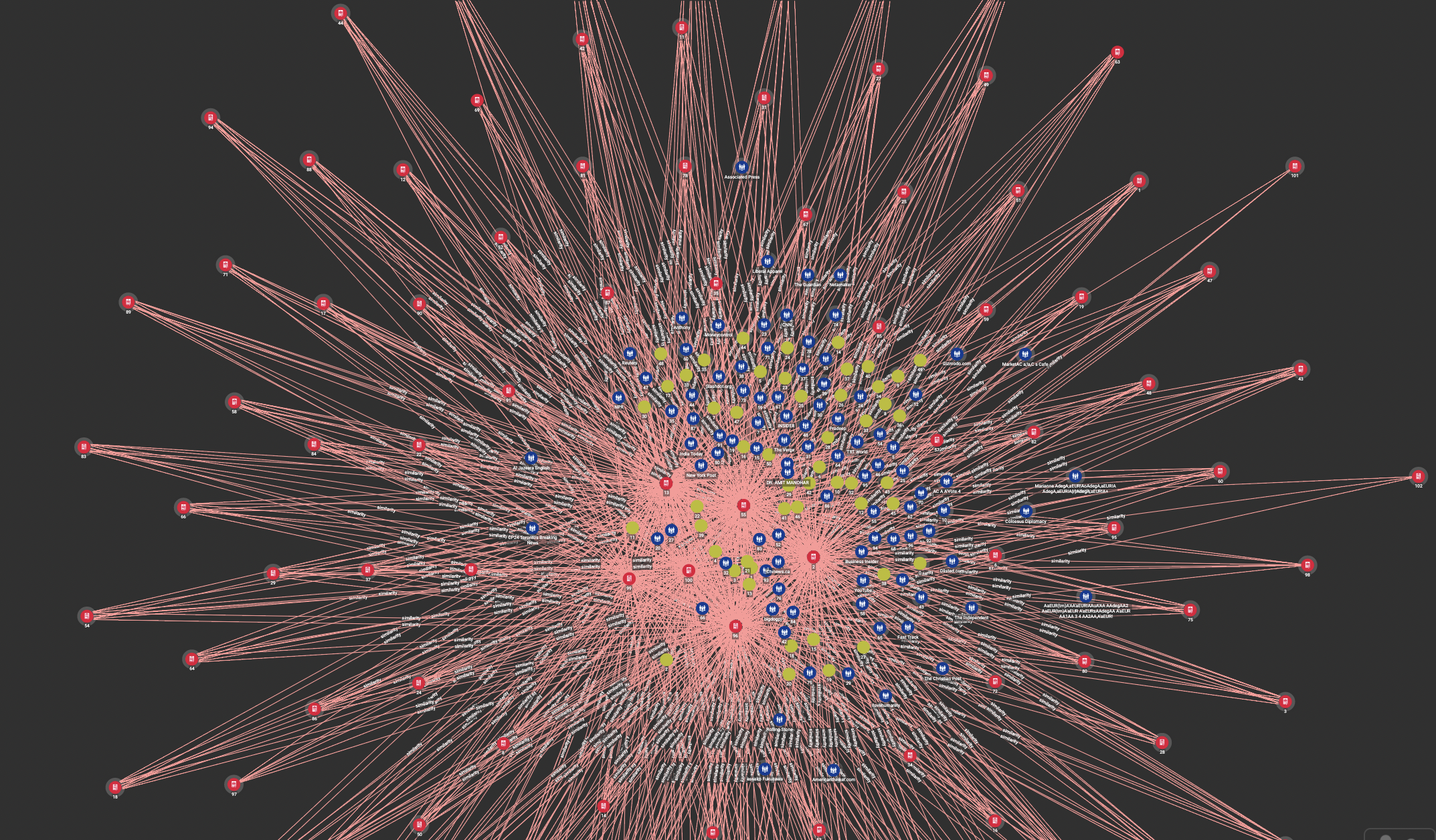
It uses Graph and Hyper-graphs to detect duplicate and similar articles and creates clusters of similar articles. The desired state has a hyper-node graph that represents the common metadata for a cluster of duplicate or near-duplicate articles/posts and how their metadata relates to one another. The individual articles and their metadata would be clustered together as relations to the hyper-node. Each hyper-node would in effect represent all versions of the individual articles and posts that are duplicates and give a normalized representation of the article/post. This hyper-node and its metadata can then be used to group articles/posts together in a search application to minimize noisy search for news articles/posts and help end-users identify if an article/post is actually 'going viral' or just overhyped and not worth their time.
How we built it
- To scope this solution, we have taken a mix of news articles and posts and created a hypergraph of as many duplicates.
- Documented the metadata for each article/post in your dataset, assess the metadata for duplicate information to create a similarity score, the most similar articles/posts will create the cluster of articles/posts related to each hyper-node.
- Threshold for similarity is 75% (0.75 f-score)
- Documented the normalized information (the data the clustered articles/posts have in common) as metadata for the hyper-node and the similarity between each hyper node.
- Represented the similarity of metadata between hyper-nodes that allows for the solution to scale so that as new news articles/posts are posted, the metadata can be queried to identify if the new article/post is an existing duplicate or a new article/post.
Challenges we ran into
- Working with graph databases and query language was a foreign concept for our team.
- Understanding and implementing hypergraphs was a roadblock that we faced.
Accomplishments that we're proud of
- As undergrad students we had minimal exposure to GraphML and solving such a problem has been a great learning experience in itself
What we learned
- Grateful to Tigergraph Community for conducting such awesome sessions for our understanding that made this project tough yet enjoyable.
What's next for hyper-news
Currently, we are dealing with short text similarity only, but we plan to extend our model and make it more robust to language modelling so that we can compare short-long texts and documents all together.









Log in or sign up for Devpost to join the conversation.