-
-
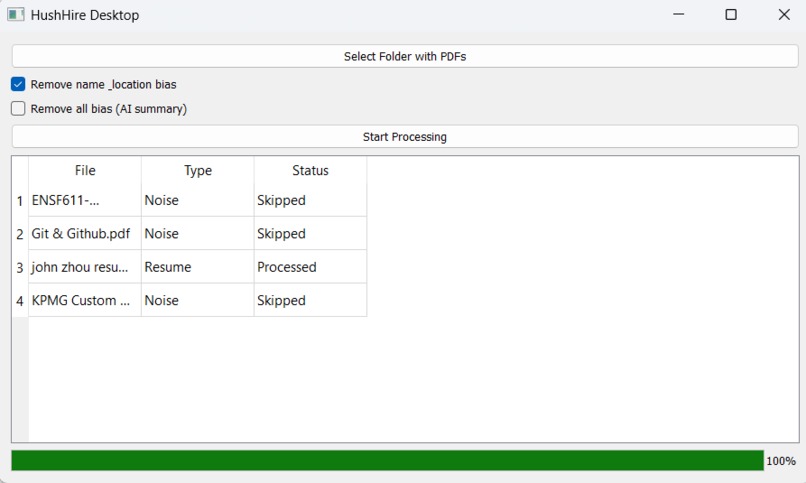
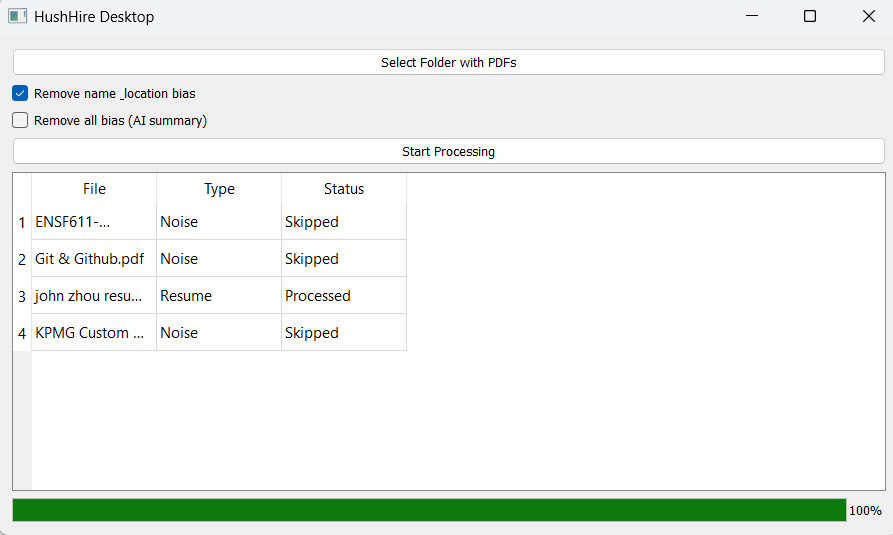
Windows Desktop application
-

Website. Api endpoint

Inspiration
Hiring decisions are often influenced by bias unrelated to ability—such as names, locations, institutional prestige, or resume writing style. At the same time, identifying the right candidate is difficult, as many applicants mass-apply, creating significant noise.
Under the “Noise and Silence” prompt, we asked:
- What if we could silence bias before it speaks?
- What if we filtered noise before it ever enters the system?
What it does
HushHire is a bias-aware resume processing system that helps surface meaningful resume while silencing bias.
It performs the following actions:
Noise filtering A machine-learning classifier verifies whether an uploaded PDF is a resume, preventing non-resume documents from entering the pipeline. This prototype establishes the foundation for future enhancements, including automatically filtering out resumes that clearly do not match the job requirements.
Bias removal (user-selected mode)
- Partial bias removal: removes names and geographic identifiers while preserving the original wording.
- Full bias removal: generates a structured, bias-reduced summary focused on skills, experience, and impact. This reduces bias between native and non-native English speakers.
HushHire outputs both structured JSON and human-readable summaries, making it suitable for human review and downstream systems.
How we built it
HushHire combines traditional machine learning with modern large language models:
Resume detection: An in-house SVM + TF-IDF classifier trained to distinguish resumes from non-resume PDFs.
Bias reduction: Carefully engineered prompts guide an LLM to:
- Remove identity and location cues
- Normalize organizations and institutions into generic categories
- Optionally summarize responsibilities into neutral, skill-focused descriptions
Web application: Built with Next.js, TypeScript, Tailwind CSS, and FastAPI, providing an interactive, single-resume workflow with real-time progress feedback.
Desktop application: Built with PyQt5, enabling batch processing of local folders for privacy-preserving, offline-friendly resume auditing.
Challenges we ran into
Balancing bias removal and information loss Early versions removed too much context. We refined prompts to preserve meaningful content while silencing bias-inducing signals.
Ensuring consistent structured output from LLMs We had to carefully enforce strict JSON schemas and validate outputs to avoid downstream failures.
Packaging machine learning models into a desktop application Bundling scikit-learn pipelines and prompts into a standalone executable required careful dependency handling and build configuration.
Designing a UI that communicates progress and trust We iterated on layouts to avoid visual noise while clearly showing what the system is doing at each step.
Accomplishments that we're proud of
- Building a noise-filtering stage, reinforcing responsible AI use
- Supporting both interactive web and batch desktop workflows
- Producing outputs that are both machine-readable and human-readable
- Successfully packaging the desktop app as a standalone executable
- Creating a system that aligns fairness principles with real-world hiring workflows
What we learned
- Bias mitigation is as much about input control as it is about model choice
- LLMs are powerful, but require careful constraints to be reliable in structured systems
- Combining classic ML with LLMs can yield practical, trustworthy solutions
What's next for HushHire
- Automatically filtering out resumes that clearly do not match the job requirements.
- More options to choice the exact feature to "slience".
- Build a universal API that allows companies to integrate with their resume collection systems. Resumes will be processed and standardized before reaching recruiters.
- Expanding the current functionalities to apply to cover letters
Built With
- fastapi
- next.js
- openai
- scikit-learn
- tailwind
- typescript




Log in or sign up for Devpost to join the conversation.