-
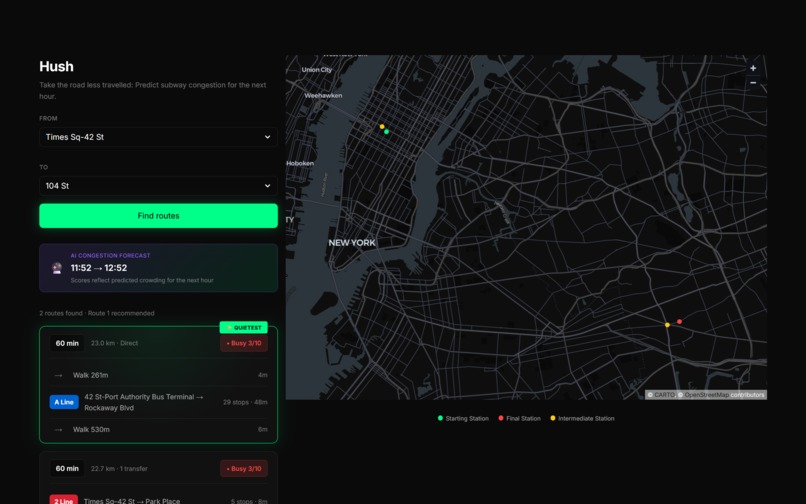
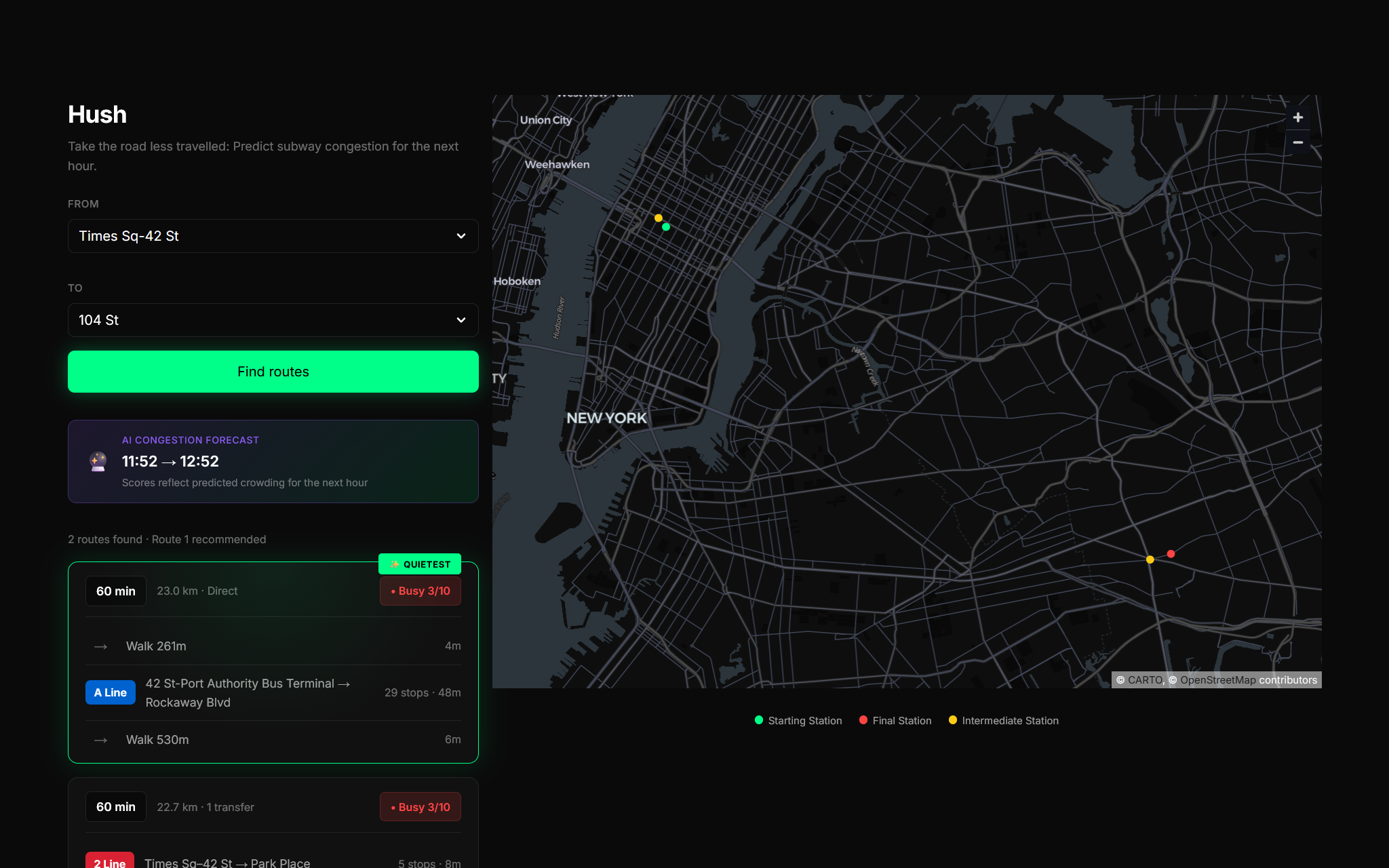
Web Interface
-
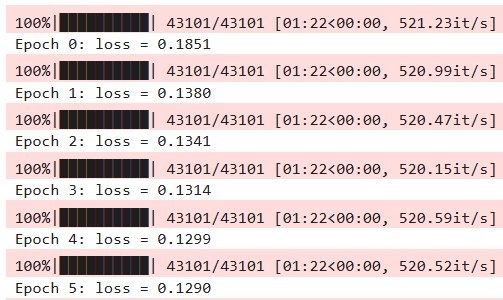
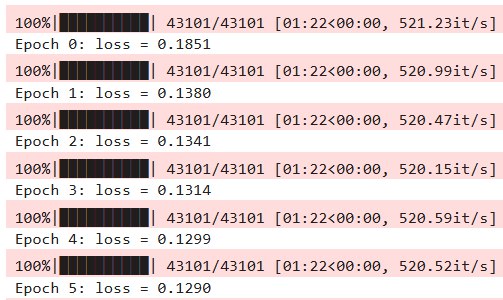
GNN Training
Inspiration
Public transit was engineered for efficiency, not for empathy.
For the average commuter, a packed train is just a nuisance. But for the elderly, neurodivergent individuals, or expectant mothers, it is a genuine barrier to the city.
We analyzed every major navigation app and found the same flaw: they all optimize for a single variable—Time. They will save you two minutes, even if it means forcing you into a crushing, high-stress environment.
Hence, we set out to build Hush — a project designed to engineer a layer of sensory intelligence on top of standard transit data. By assigning a crowdedness score to each journey, we are able to identify quieter, safer routes for those who need it.
What it does
Hush integrates with Google Maps, taking a user inputs for origin and destination and using Routes API to fetch the top three fastest routes.
Instead of simply displaying these routes by duration, Hush utilises a proprietary machine learning model to predict the passenger density for each leg of the journey. It then generates a Calm Score ranging from 0 (Severe Crowding) to 10 (Empty). This allows users to make an informed decision: take the fast route, or the slightly longer, peaceful one.
How we built it
Frontend (Streamlit): We built a responsive web interface using Streamlit, which renders the interactive map and handles user queries.
Backend (Python): The core routing engine. It pulls transit paths using the Google Routes API.
Model (GNN): A Graph Neural Network (GNN) processes variables like time of day and historical station data to predict the crowdedness of a specific route, rerouting users away from chaos.
Dataset - MTA Ridership Data 2020-2025
Challenges we ran into
The project was initially supposed to run on the TfL live congestion API. However, after pulling the data, we discovered that the accessible TfL congestion data was limited to only one week of historical logs—insufficient for training a robust predictive model.
We quickly pivoted to target the NYC subway system (MTA), which came with it own challenges as well. While raw data was readily available (5 years of hourly ridership data), the data was dirty and incompatible with the APIs we were experimenting with. We implemented custom Python scripts to solve these issues, such as converting between station names and station codes to coordinates for our Routing API. Additionally, MTA does not provide live data, hence, we trained our model with the data from 2020-2023, while 'simulating' live data using the 2024 data set.
We originally planned to incorporate meteorological data into our Graph Neural Network (GNN). However, we hit a hardware bottleneck as our local machines lacked the GPU power to train such a high-dimensional model within the 24-hour hackathon window. We chose to drop weather data in favour of a functional, high-accuracy core model.
Accomplishments that we're proud of
Our team attempted to train a model in 2025's edition of ICHack. We're proud that we've finally seen this through - a testament to how far we've progressed as engineers since.
What we learned
The ideation phase is arguably just as important than the execution phase. In this year's edition of ICHack, we took the whole afternoon to not just bounce ideas, but also conduct in depth research into our potential ideas (such as datasets available). This gave us confidence to ensure that we will be able to see through our project once we had committed to it.
What's next for Hush
Multi-Modal Routing: Currently, Hush optimizes subway travel. Our next step is to expand the model to include buses and walking routes, creating a truly seamless, sensory-safe journey from door to door.
Multi-Variable Modelling: We aim to increase the granularity of our predictions by incorporating meteorological data. Rain and snow significantly alter commuter behaviors and crowd densities; adding these variables will make our "Crowdedness Score" even more robust.
Built With
- google-maps
- mtahourlyridershipdataset
- python
- pytorch
- streamlit

Log in or sign up for Devpost to join the conversation.