-
-
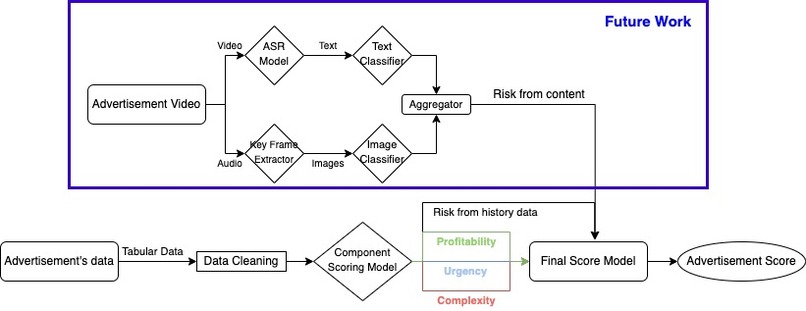
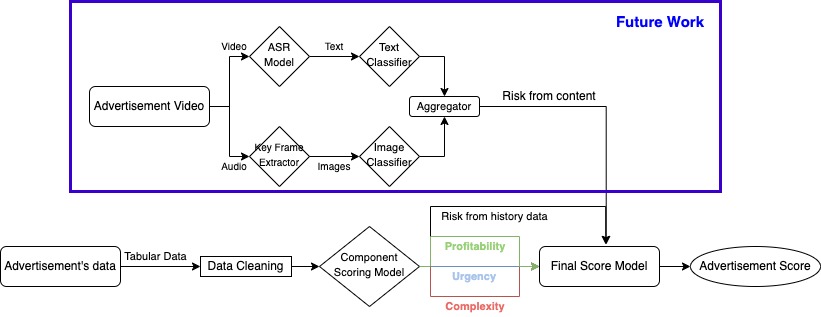
Ads Scoring Model - Workflow
-
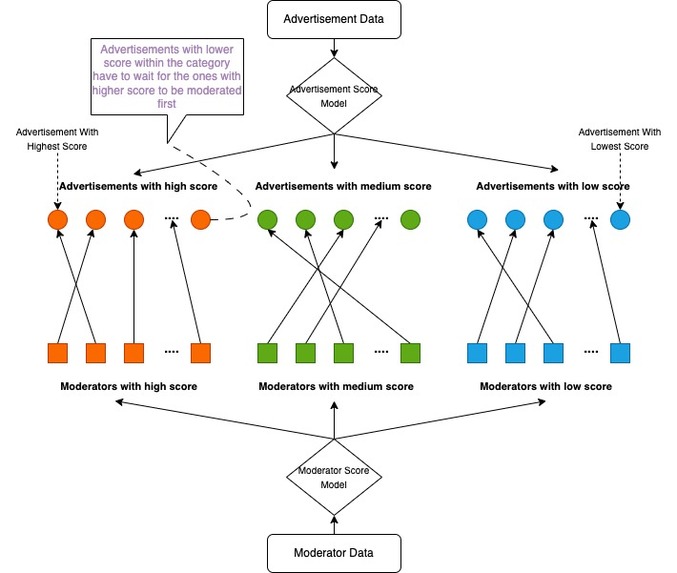
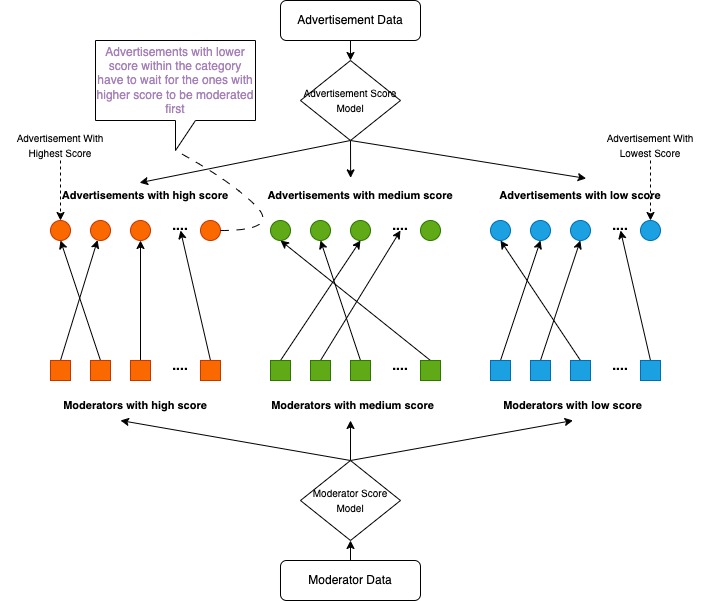
Matching Algorithm - Workflow
About our team
We are a team of five fourth-year NUS Data Science and Analytics students working under the guidance of our leader, Fang Zhengdong, who spurred incredible insights and innovation throughout the project. Zhengdong, together with our strong programmer Zhang Aijia, spearheaded the development of our dynamic matching models, leveraging the powerful Hungarian algorithm. Meanwhile, Zhao Xi, You Bohan, and Liu Chen dedicated numerous hours to analyse the sample dataset, carried out data transformation and implemented the two foundational scoring models that underpin our matching system, setting a strong base for a solution that promises both efficiency and precision in ad moderation.
Inspiration of Project
The project is about optimisation ads moderation process, which is similar to one of our teammates’ school project (Course Code DSA3101), where they created a stochastic optimisation model to reallocate assignment deadlines to minimise the stress level of students. Using similar ideas, we formulate the methodology to structure the scoring model and the matching model which we will describe in detail in the next section.
We have also conducted a research to learn about existing stochastic optimisation model with reference to the 2 documents below: Stochastic dynamic matching: A mixed graph-theory and linear-algebra approach: link A framework for dynamic matching in weighted graphs link
What it does
Our project consisted of 2 main segments — scoring models and matching models. The 2 scoring models will generate a score for each ads and each moderator respectively. The score, together with the market data and other important attributes such as handling time and complexity, is then put into the matching model to match the score between ads and moderators’ market, and assign the best suitable ads to moderators with Hungarian Algorithm. Together, the scoring model and the matching model ensures that each moderator will be assigned to the most suitable ads content and number of tasks, maximising their individual efficiency and accuracy.
How we built it
Our scoring models made use of the idea of nested linear regression, where we categorised the given attributes into big segments and combined them together with an assigned weight — justified with real life business context. Prior to that, a holistic round of data exploration and transformation have been performed to avoid latent weight and skewed distribution.
Our matching algorithm simplified a complex NP Hard combinatorial issue by transforming it into several assignment problems by using a priority queue.These problems can be optimally solved via Hungarian Algorithm. Additionally, the algorithm categorised both moderators and advertisement content into three distinct groups based on their respective scores to ensure the matching quality.
Challenges we ran into
One challenge we face is the lack of y-labelling in the sample dataset. This means we will not have a way to fit our data into a linear regression model for the scores. To solve this issue, we decided to use our business context to assign weightage to each factor manually, and perform min-max to ensure the scoring model will always provide a score ranging between 0 and 1.
Another obstacle we encountered was the optimisation of the combinatorial challenge inherent in our matching model, akin to allocating 40,000 units across 1,000 categories. Achieving a global optimum had a prohibitive time complexity of 1k * 40k, an approach unrealistic in practical business environments. Consequently, we adopted a 'divide and conquer' tactic, fragmenting the large problem into smaller, manageable segments and employing an appropriate algorithm to address it. We delineated both the ads and moderators into three distinct categories based on their respective scores. Utilising a priority queue allowed us to further divide content in each category into smaller batches, the batch size corresponding to the number of moderators in each group. This strategy transformed a complex combinatorial issue into several 'assignment problems' with significantly reduced time complexity, enabling the identification of optimal solutions for each batch through the application of the Hungarian algorithm.
Accomplishments that we're proud of
Our model efficiently reduces ad & moderator score differences, evidenced by a favourable left shift in the mean and distribution, guaranteeing that top moderators handle high-value content aptly. Moreover, we enhanced the median market similarity score by 90%, enabling moderators to work with content that resonates with their background, optimising both revenue and review time. This refinement, coupled with a 72% reduction in median of task handling time, has notably elevated review speed and efficacy, promising a much-improved moderation process without sacrificing quality.
What we learned
Through this project, we are given the opportunity to apply theoretical knowledge about stochastic optimisation to real-world models, enhancing our understanding of how these models can address actual business problems. The project also served as a platform for learning from one another, including new concepts such as the Hungarian algorithm. Lastly, it helped us to integrate theoretical understanding with business context, allowing us to determine and justify the weight assigned to each factor in linear models.
What's next for Hungry_Ads
While lacking access to the advertisement's full content, we see a necessity in reviewing it to assess any potential risks, going beyond mere historical data reliance. We crafted a framework to analyse video content more efficiently, enhancing our risk assessment capability for ads. This system breaks down videos into images, examined using reliable image classifiers such as CLIP to spot possibly illegal items in the ads. Likewise, we transform audio to text to employ text classifiers like BERT for identifying illicit references. Finding such elements escalates the ad's risk level, assuring more precise outcomes from our advertisement scoring model.
Built With
- chatgpt
- hungarian
- np-hard-combination
- python










Log in or sign up for Devpost to join the conversation.