hOS - The Human Operating System
Inspiration
When was the last time you actually understood your own blood work? Not just glanced at a portal that says "normal" or "high," but genuinely understood what your liver enzymes trending upward over three tests might mean alongside what your last chest X-ray showed?
For most people, the answer is never. Diagnostic data is fragmented across systems that don't talk to each other. Your pathology results live in one portal. Your imaging lives in another. Your GP gets a PDF, skims it in the four minutes they have with you, and gives you a one-line summary. The cross-referencing — the part that actually catches things early — almost never happens unless you're seeing a specialist who already suspects something.
This isn't just inconvenient. It's a systemic failure in how health data gets interpreted. The tools that do exist fall into two camps. Consumer wellness apps like InsideTracker or Function Health are cloud-based, subscription-locked, and built on proprietary scoring that you can't audit or verify. They treat your most sensitive data as their product and their interpretations as a black box. On the clinical side, diagnostic software exists, but it's locked behind institutional licenses, tied to specific imaging hardware, and inaccessible to individuals or small practices.
Neither camp solves the core problem: there is no tool that takes your raw diagnostics — blood work, imaging, body composition — normalises them into a common framework, runs validated analysis, and gives you a clear, auditable, reproducible interpretation. One where you can trace every finding back to the exact model and scoring system that produced it.
We needed a diagnostic interpretation engine built to a clinical standard, that runs locally, respects your privacy, and connects the dots across every domain of your health data. So we built one.
Our view is that it the future tools like this this one won't be looked at as extras, or for power users who are deeply invest in their health and lifestyle. It'll be a part of life - control our health, understanding what and how things went bad or good - and allowing you to change the things you want change.
What it does
hOS is a local-first desktop application that ingests raw diagnostic data — blood work PDFs from pathology labs, medical images like chest X-rays, and body composition measurements — and runs deterministic, auditable analysis entirely on your machine.
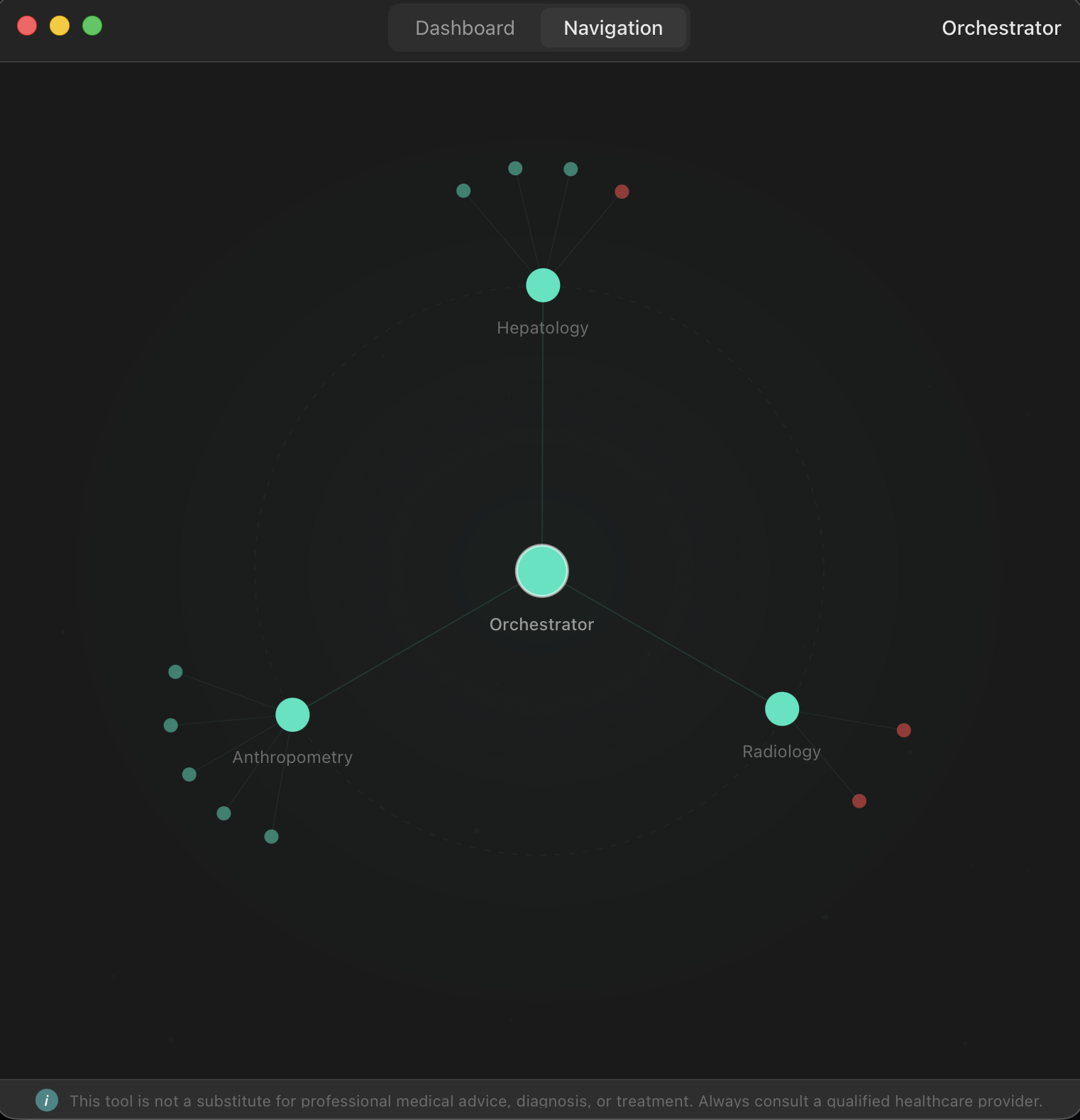
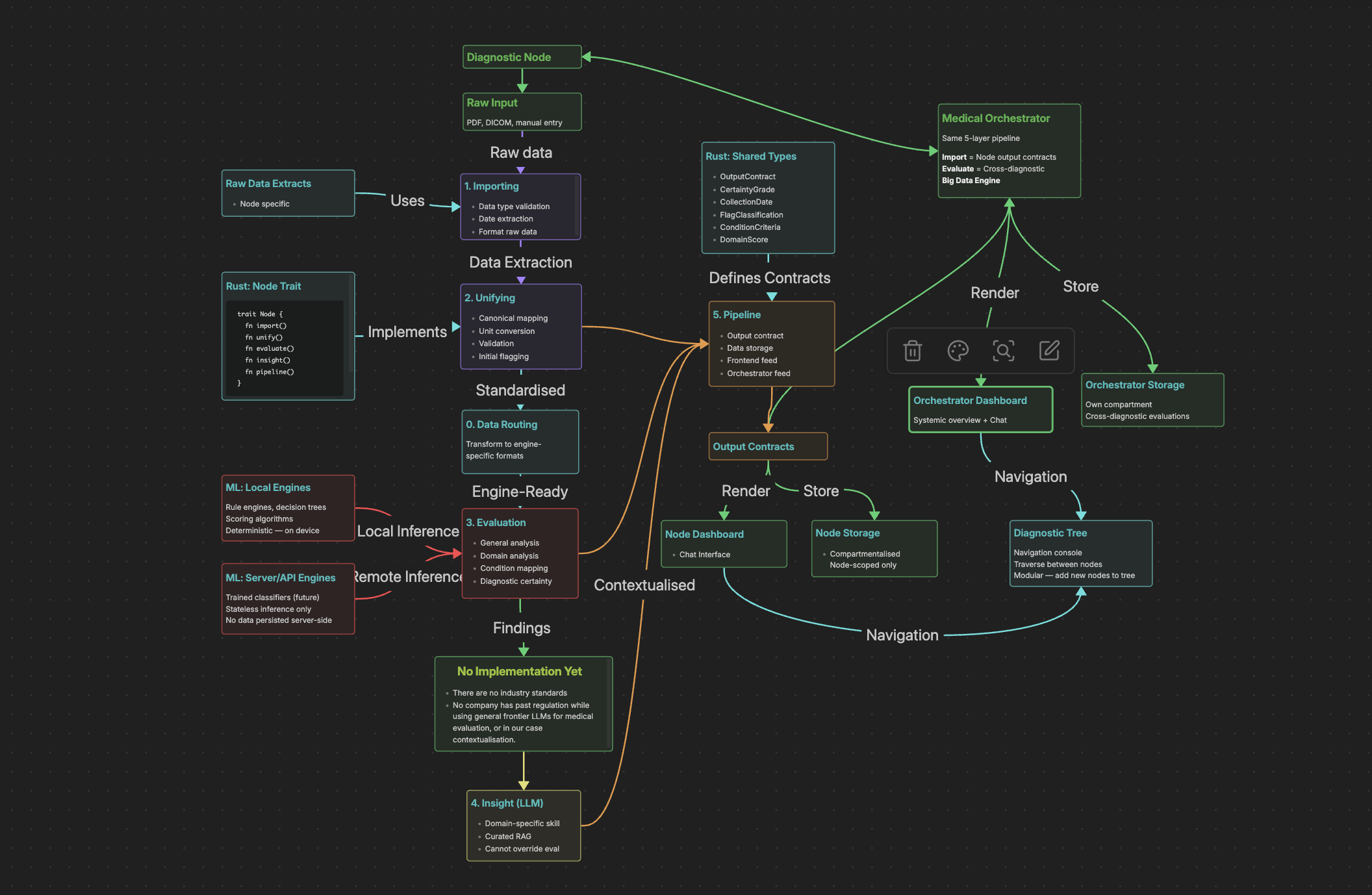
The core of hOS is a node-based pipeline architecture. Each diagnostic domain is its own node, and every node follows the same five-layer contract: import raw data, unify it into canonical typed structures, evaluate it against validated scoring systems, generate insight, and pipeline the results both to its own dashboard and upward to a cross-diagnostic Orchestrator.
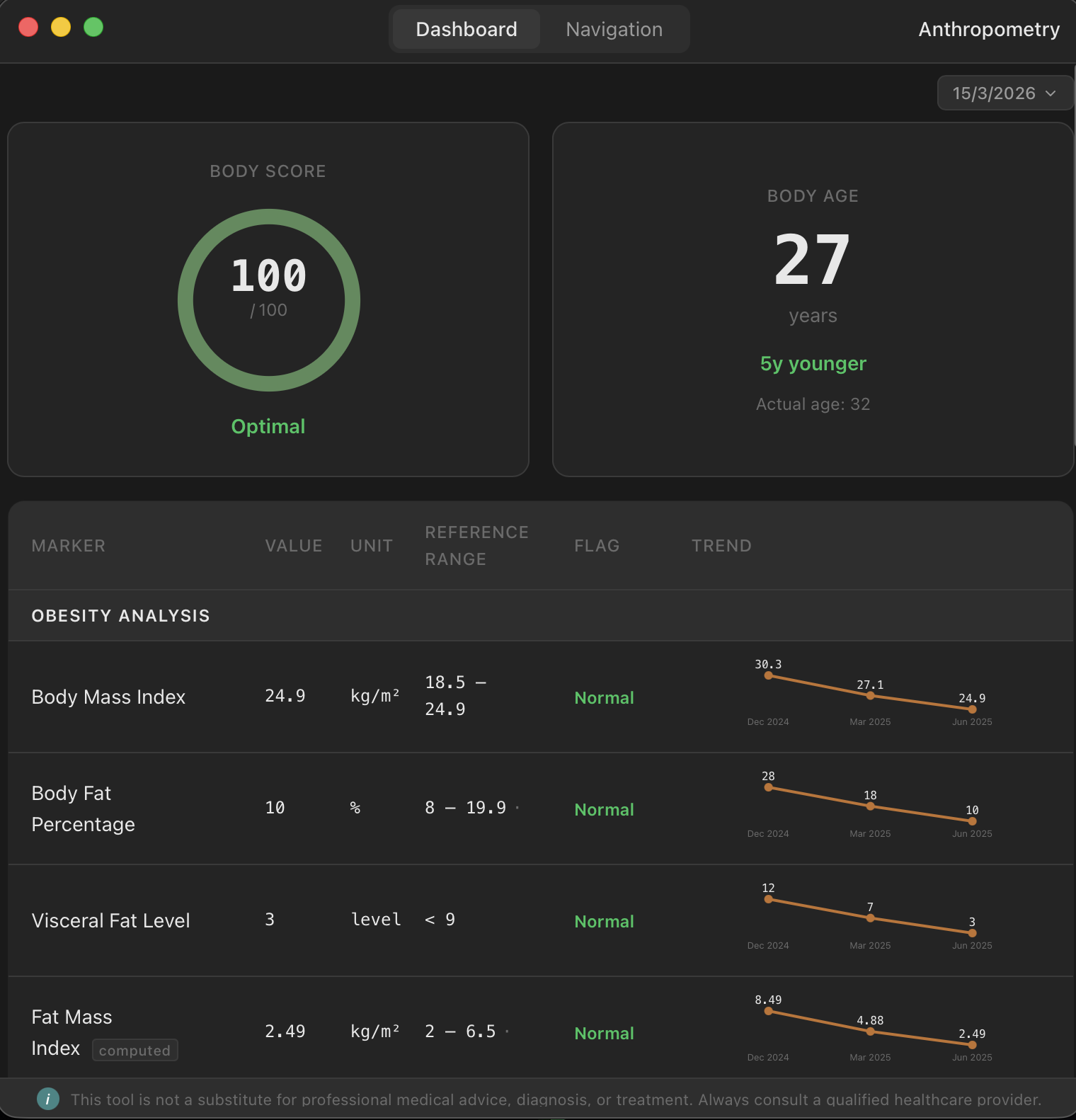
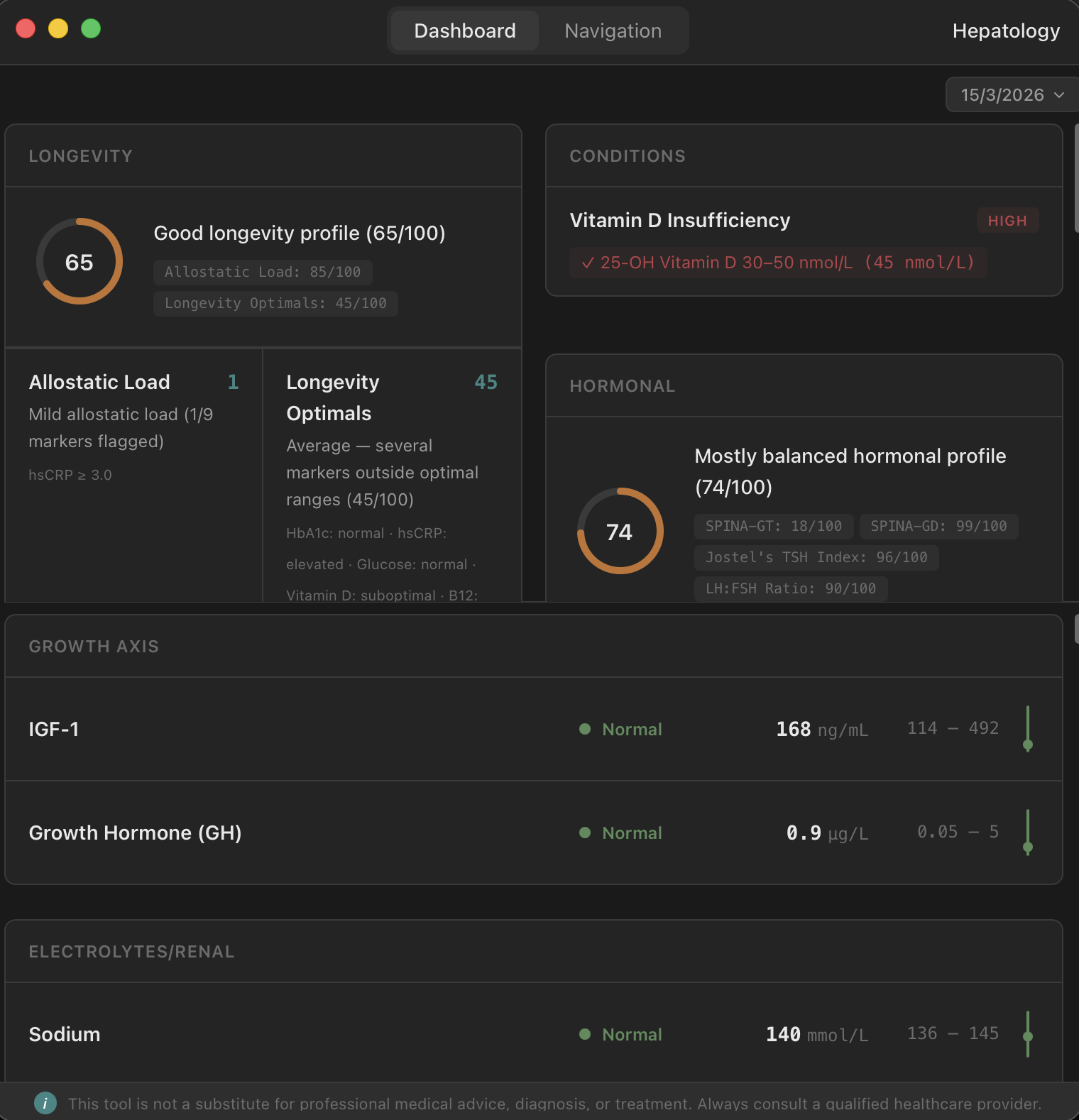
The hepatology node handles blood work. Upload a PDF from a major pathology lab — Laverty, QML, Sullivan Nicolaides, Quest, LabCorp — and hOS extracts every marker, normalises units and reference ranges, and runs multiple validated scoring systems. Longevity indices, metabolic panels, hormonal profiles, composite disease risk scores. All in under a second, with 99%+ extraction accuracy on supported labs.
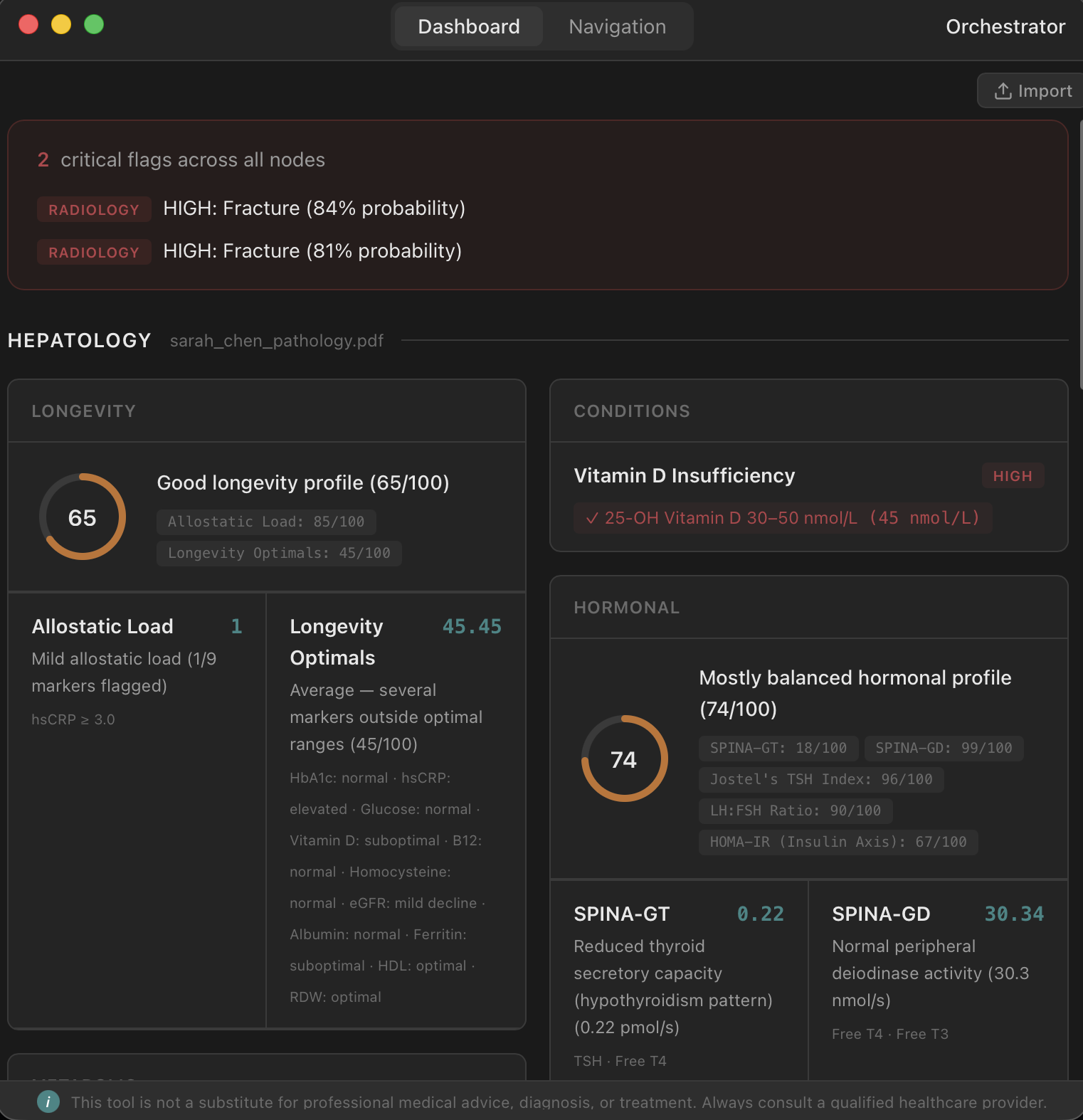
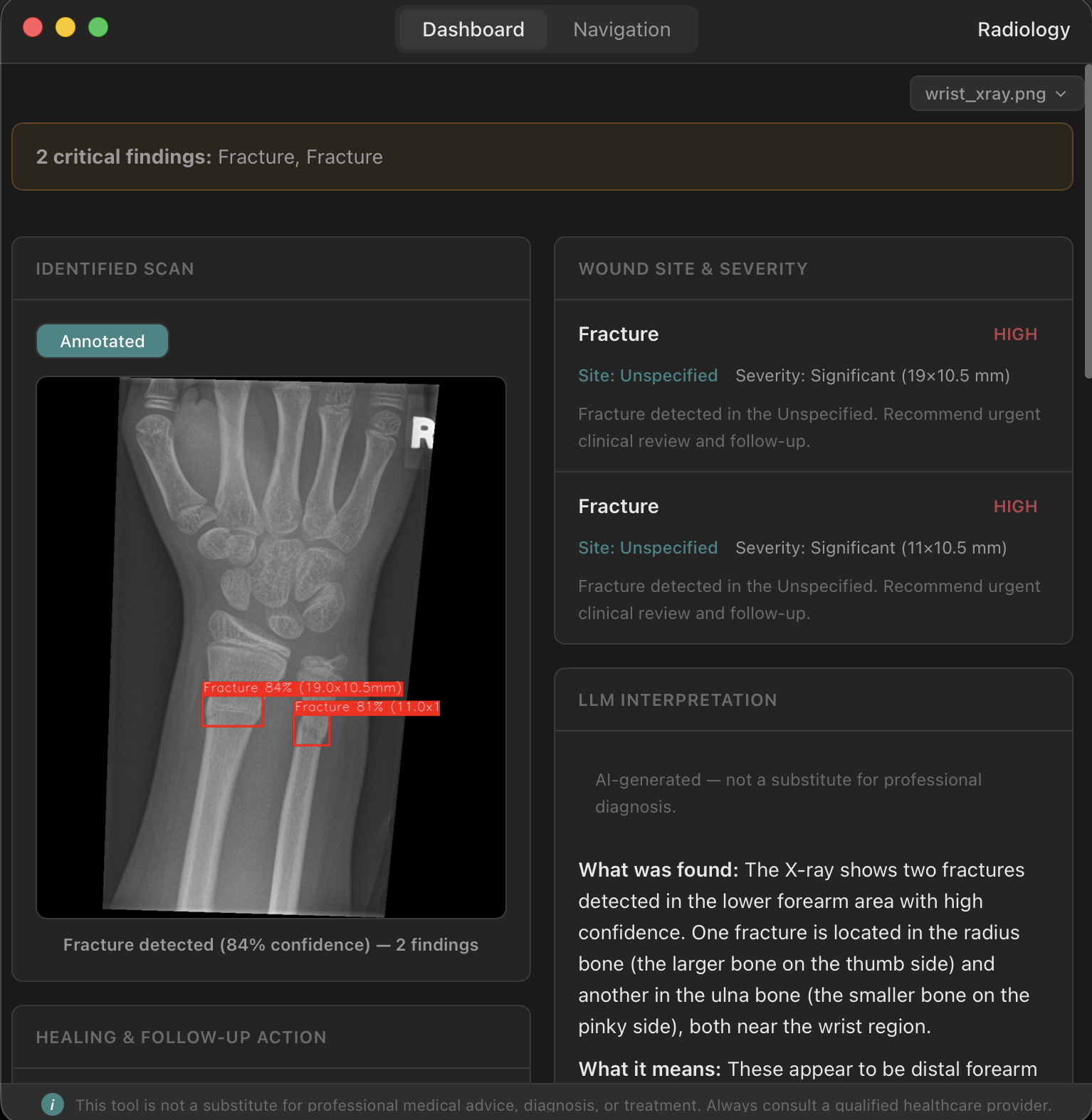
The radiology node handles medical imaging. Drop in a chest X-ray and hOS runs two inference pipelines: TorchXRayVision for pathology detection and YOLOv8 for fracture detection. You get confidence scores, severity flags, and quality warnings — all deterministic, all reproducible.
The Orchestrator sits on top of everything. It consumes output contracts from every node and performs cross-diagnostic analysis — the kind of pattern recognition that normally requires a specialist reviewing multiple reports side by side. Metabolic syndrome, for instance, requires correlating blood markers with body composition data. The Orchestrator handles that automatically.
The key principle behind all of this: same input, same model version, same output. Every time. No black-box LLM making clinical calls. Every scoring system is validated or provable. Every finding is traceable. Because we're not building a wellness app — we're building toward TGA and FDA approval as a real medical tool.
How we built it
We started with the architecture. Before writing a line of code, we spent significant time designing the node model and the five-layer pipeline contract. Getting the abstractions right upfront meant that when we split into parallel workstreams, everything could develop independently and still fit together.
The frontend is React with TypeScript, bundled with Vite, running inside a Tauri v2 desktop shell. Tauri gave us a lightweight, secure desktop app without the overhead of Electron, and its Rust backend meant we could keep the pipeline logic close to the metal where it mattered.
The Rust backend implements the node trait, storage layer, and Tauri IPC commands. Every type that crosses the Rust-frontend boundary gets Serde derives for JSON serialisation — a hard requirement of Tauri's IPC model, and one that forced us into good discipline around our data contracts early.
For the ML and data processing layer, we went with Python. Blood work extraction uses template-based regex parsing against known lab formats, run through pdftotext. It's not glamorous, but it's deterministic, fast, and hits 99%+ accuracy — which matters more than elegance when you're building for clinical use. Medical image inference runs through PyTorch, with TorchXRayVision providing DenseNet-based pathology detection and YOLOv8 handling fracture detection across multiple body regions.
The philosophy throughout was: use whatever tool is objectively best for each specific operation. Rust for the pipeline, storage, and type safety. Python for ML inference and PDF extraction. The node trait doesn't care what language implements a given layer — it only cares about the shape of data flowing in and out.
We parallelised aggressively. One workstream focused on the hepatology node end-to-end, another on the radiology pipeline, and a third on the frontend dashboards and cross-node navigation. Clear output contracts meant we could develop in parallel without blocking each other.
Challenges we ran into
Polyglot integration. Having Rust call Python processes, manage their lifecycle, handle errors gracefully, and parse their output back into typed Rust structs is nontrivial. We had to be disciplined about where the boundary sat — Python processes live inside specific node layer implementations, never in the top-level wiring — and make sure failures in the Python layer surfaced as proper Result types in Rust, not silent crashes.
Keeping things deterministic under ML inference. Neural networks are not inherently reproducible across different hardware and library versions. We had to pin specific model versions, lock dependency trees, and verify that the same input produces the same output across our development machines. For a wellness app this wouldn't matter. For something targeting regulatory approval, it's non-negotiable.
Resisting the LLM temptation. It would have been easy — and flashy for a hackathon — to pipe everything through a large language model for natural-language interpretation. We deliberately didn't. Frontier models aren't reproducible enough for clinical use, and regulatory frameworks haven't caught up. The diagnostic core has to be deterministic. We deferred the insight layer entirely rather than compromise on that principle, even though it meant having less to demo.
Accomplishments that we're proud of
We're proud of the architecture holding up. The node model and five-layer pipeline sounded good on paper, but seeing it work in practice — where we could develop the hepatology and radiology nodes completely independently and have them slot into the same Orchestrator framework — validated the design. The trait is the contract, not the implementation, and that principle paid off.
Getting two separate ML inference pipelines running locally — chest X-ray pathology detection and fracture detection — with proper confidence scoring and severity classification was a significant win. These aren't API calls to a cloud service. They run on your machine, on your data, with no network dependency.
We're also proud of what we chose not to build. Deferring the LLM insight layer was the right call for a project targeting clinical credibility. It would have been the easy demo, but it would have undermined the core principle. Every finding in hOS traces back to a validated, reproducible pipeline, and we didn't compromise that for a flashier presentation.
And we're proud of the local-first commitment. Your health data never leaves your machine. No cloud uploads, no subscription gates, no third party touching your diagnostics. In an era where health data is increasingly commodified, that feels important.
What we learned
Architecture-first pays compound interest. We spent what felt like a disproportionate amount of time on the node model and pipeline contract before writing implementation code. That investment paid back immediately when we could parallelise development across nodes without stepping on each other, and it continues to pay back every time we add a new scoring system or data source.
Determinism is harder than it sounds. Saying "same input, same output" is easy. Actually achieving it across different machines, Python environments, and ML library versions requires deliberate engineering — pinned dependencies, locked model versions, and explicit verification. It's the kind of work that doesn't show up in a demo but is the entire foundation of clinical credibility.
What's next for hOS
The Orchestrator. Cross-diagnostic analysis is where hOS becomes more than the sum of its parts. Correlating blood markers with imaging findings and body composition data to flag systemic patterns — metabolic syndrome, inflammatory cascades, hormonal imbalances — is the next major milestone. The architecture is ready for it; the output contracts from each node are designed to feed directly into the Orchestrator's import layer.
Any diagnostic domain, same architecture. This is the part that excites us most. The node model isn't specific to blood work or imaging — it's a general-purpose contract for diagnostic interpretation. The five-layer pipeline (import, unify, evaluate, insight, pipeline) and the output contract system mean that adding a new diagnostic domain doesn't require rethinking the architecture. It requires implementing the layers. Cardiology, dermatology, pulmonary function, genomics, audiometry — each of these is a node waiting to be built. The import layer learns to ingest that domain's raw data. The unify layer normalises it into typed structs. The evaluation layer runs validated scoring. And the Orchestrator immediately gains the ability to cross-reference that new domain against everything else. A cardiology node doesn't just give you cardiac analysis — it gives the Orchestrator the ability to correlate cardiac findings with liver enzymes, imaging results, and body composition in ways that would normally require a multidisciplinary team. The modularity isn't a nice architectural property. It's the scaling strategy. Every new node makes every existing node more valuable, because the Orchestrator sees further with each domain it can draw from. And because the trait contract is language-agnostic — a node can implement its layers in Rust, Python, or anything else — the barrier to adding a new domain is domain expertise and validated models, not engineering rework.
The regulatory path. Everything we've built is designed with TGA and FDA approval in mind. The deterministic pipeline, the audit trail, the reproducibility guarantees — these aren't nice-to-haves, they're prerequisites. The next phase includes formal validation studies and beginning the regulatory submission process.
And the insight layer — when frontier models reach the point where their outputs are reproducible and auditable enough for clinical use, and when regulatory frameworks provide clear guidance, we'll add LLM-based contextualisation. But not before. The diagnostic core comes first.
Built With
- claude




Log in or sign up for Devpost to join the conversation.