-
-
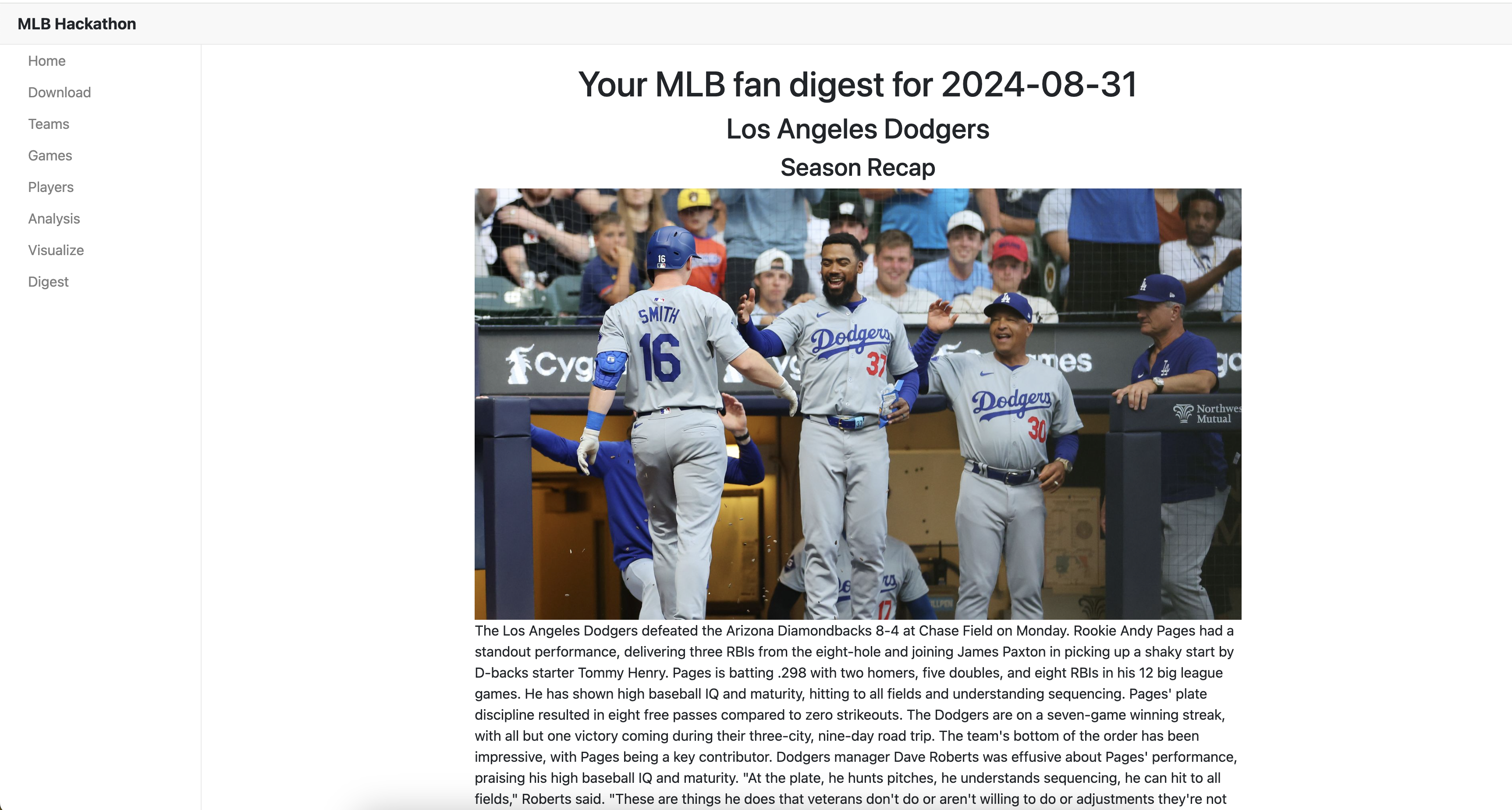
MLB Digest Screen
Inspiration
My primary inspiration for this MLB fan site hackathon stemmed from a desire to move beyond simply using LLMs and actually integrating them into a real-world, user-facing application. I wanted to understand the nuances and challenges of building with AI, rather than just interacting with it. I was excited to explore how AI could enhance fan engagement.
What it does
My project, "MLB Fan Central," aims to be a one-stop shop for MLB fans, offering dynamic content powered by AI. It features personalized news summaries, AI-generated player profiles, and even a "What-If" scenario generator that explores alternative game outcomes based on historical data. The goal is to provide a richer and more interactive fan experience.
How I built it
My tech stack consisted of a React frontend, a Node.js backend, and initially, a MongoDB database (later switched to JSON files).
Frontend (React): I used React to create a dynamic and interactive user interface. This involved designing components for displaying news snippets, player profiles, and the "What-If" scenarios. I also incorporated user authentication to allow fans to personalize their experience.
Backend (Node.js): Node.js served as the bridge between the frontend and the data sources. It handled API requests from the React frontend, interacted with the database (initially MongoDB, then JSON files), and, crucially, communicated with the LLM. I used a library to make API calls to the LLM, passing in carefully crafted prompts to generate the desired content.
Data Storage (MongoDB/JSON): Initially, I chose MongoDB to store player statistics, team information, and historical game data. However, I quickly ran into challenges. My data, while structured, wasn't ideally suited for the kind of complex queries I needed to perform. I also found that the overhead of managing a MongoDB instance for this relatively small project was more than I needed. In the interest of time and simplicity, I migrated to storing the data in JSON files on disk. This proved to be a much more efficient solution for this specific use case. While MongoDB is excellent for many applications, for this project, simpler was better.
Challenges I ran into
My biggest challenge was definitely the data. Coming from a cricket background, I had very little knowledge of MLB. Understanding the intricacies of the game, the teams, the players, and the historical context was a steep learning curve. I spent a significant amount of time researching and familiarizing myself with the sport.
Another challenge was optimizing the interaction with the LLM. Fine-tuning the prompts to get the desired output required a lot of experimentation. I had to iterate through different prompt structures and parameters to achieve the right balance of accuracy, creativity, and conciseness. Dealing with the asynchronous nature of LLM calls and managing the flow of data between the frontend, backend, and the LLM also presented some technical hurdles.
Finally, the switch from MongoDB to JSON files, while ultimately beneficial, was a last-minute change that required a significant refactoring of my backend code. This taught me the importance of choosing the right tools for the job early on and being prepared to adapt when necessary.
Accomplishments that I'm proud of
Despite these challenges, I'm incredibly proud of what I accomplished during the hackathon. "MLB Fan Central" isn't just a project; it's a testament to the power of AI and the potential for creating engaging fan experiences. The ability to generate personalized content, offer "what-if" scenarios and create a full stack application in a short time frame.
What I learned
This hackathon was a crash course in the practical application of LLMs. I quickly discovered that while LLMs are powerful, they come with their own set of quirks. The limited context window was a significant hurdle. I had to be very strategic about how I structured my prompts and the amount of data I fed into the model at any given time. Batching data for LLM queries became essential for efficiency, and I learned techniques to chunk larger datasets into manageable pieces.
Perhaps the most surprising takeaway was the non-deterministic nature of LLM outputs. Running the same query multiple times didn't always produce the same result. This introduced a layer of unpredictability that I had to account for in my design, especially when generating player profiles or game summaries. I learned to implement strategies like caching and result verification to ensure consistency and a good user experience. I also learned the importance of data selection and management, and how the choice of database can impact the development process.
What's next for https://github.com/nsinghal12/mlb-hackathon
Future development for "MLB Fan Central" could include expanding the data sources to incorporate more real-time information, refining the AI models to improve the accuracy and creativity of the generated content, and adding more interactive features to further engage fans. I'd also like to explore integrating social media feeds and implementing a more robust user feedback mechanism.

Log in or sign up for Devpost to join the conversation.