-
Front page
-
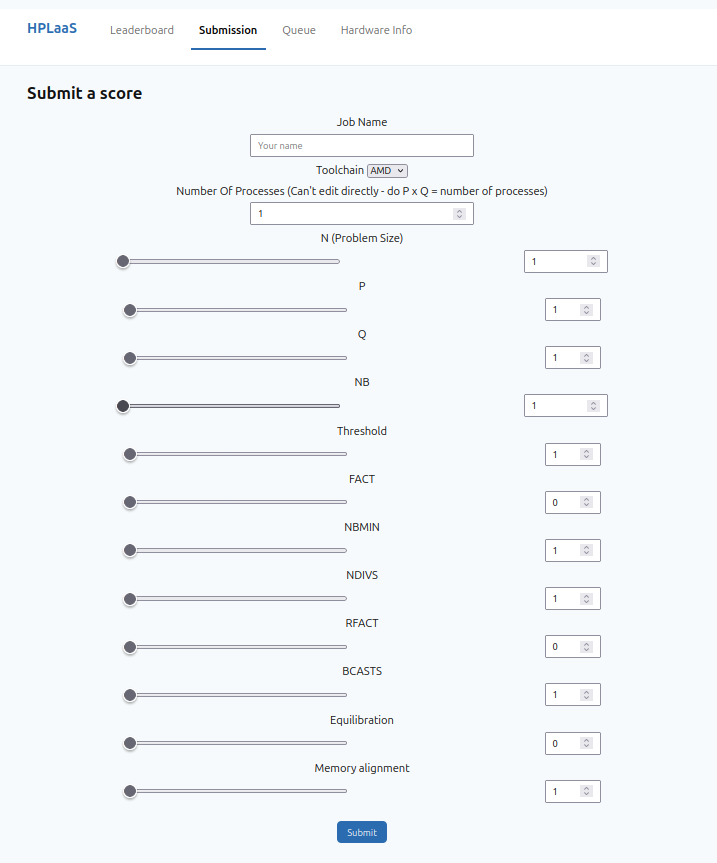
Job submission page
-
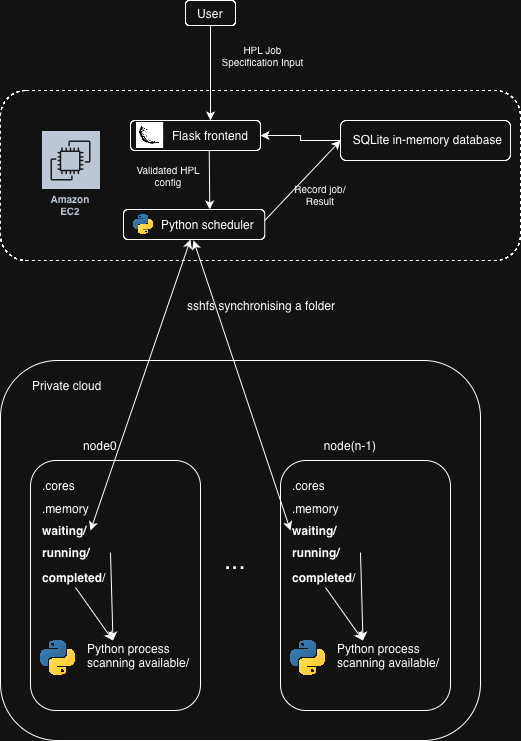
Architecture Diagram
Inspiration
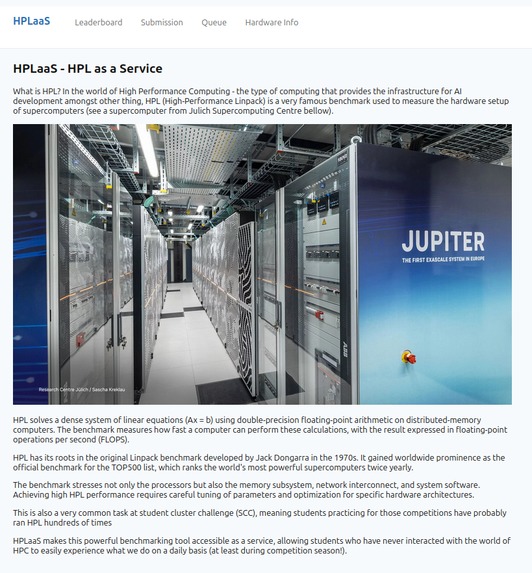
HPC: High Performance Computing For years, HPL has been the de-facto benchmark for supercomputers in the world of HPC. HPC is a classically under-represented field, meanwhile it makes up the whole world's infrastructure. We wanted to provide a platform that gave a gentle introduction to this world of HPC and where better to start than benchmarking supercomputers?
What it does
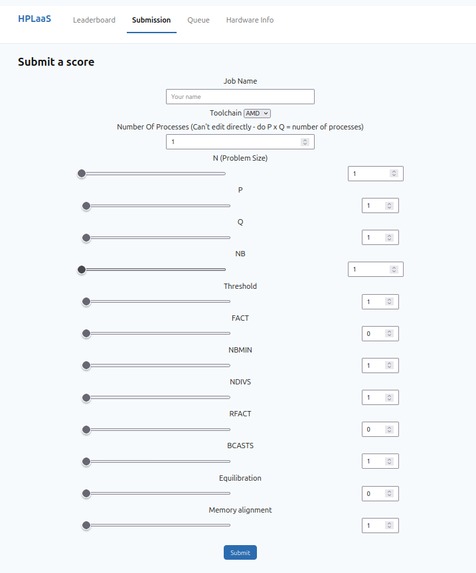
Users are able to sign up under a username and submit benchmarks (jobs) each with a set of parameters of their choosing. These parameters determine things such as the size of the underlying matrix (N) HPL is using, the size of the process grid (P x Q), the number of blocks (NB) the matrix is split up into.
Ultimately all of these determine how many GFlops (Floating point operations per second) the benchmark is able to achieve, the higher the better!
How we built it
- With hope, tears and a dream.
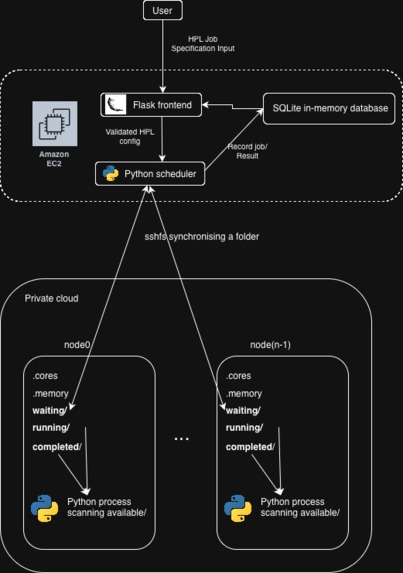
- The EC2 instance (provided by QRT) hosts the Flask app and job scheduler.
sshfs, the filesystem which synchronizes the files between the EC2 and compute backend so that they could have the same view of the jobs folder.- A weird ssh config to bypass password authentication for the ssh-based connection (critical for
sshfs). - Private on-prem compute service with 256 physical cores, hyper-threaded, with 1.5TB of memory (we have very good connections).
- Compiled and pre-compiled HPL binaries, built for maximum performance on the on-prem compute nodes.
- Python demons 😈 on the compute service which checks the shared jobs folder and submits jobs.
- More python demons 😈 on the EC2 instance which checks the shared jobs folder and processes finished jobs.
- SQLite database to store information on the runs, job parameters, achieved results, and more, modified using the Tortoise ORM python library.
- Everything contained within rootless docker containers for maximum portability and security.
Challenges we ran into
We didn't really run into any challenges, it was more like a small stumble into a plethora of problems. Verdict?
- Don't touch nginx
- Hope your EC2 instances have more than one open, public facing port (EC2 provider is mean)
- No ability to expose ports on our compute nodes (compute provider is mean) which would have made metric scraping with node-exporter trivial (it wasn't)
- Don't use
sshfsas your NFS replacement - Better planning as the project grows
Accomplishments that we're proud of
We got it to run and everyone can access it, and its cool, and we made wacky tools work together, and not mention its cool and HPC related!
What we learned
We learnt how to:
- Use Flask, Docker, and nginx (partially)
- Gained much more hands-on experience with port forwarding and SSH
- Used
sshfsfor the first time - Architecture and design a quite complex system with many moving components
- Work on 0.0001hr of sleep
What's next for HPLaaS (HPL as a Service)
HPLaaS could be polished up slightly, however once that is done, our goal is to host many more similar benchmarks for people to play with. Imagine NAMDaaS, or ICONaaS, or STREAMaaS,... In fact, we could have user compiled binaries and complete pipeline modifications.
HPLaaS + NAMDaaS + ICONaaS + STREAMaaS + ....aaS = BenchaaS 🗣️🔥





Log in or sign up for Devpost to join the conversation.