-
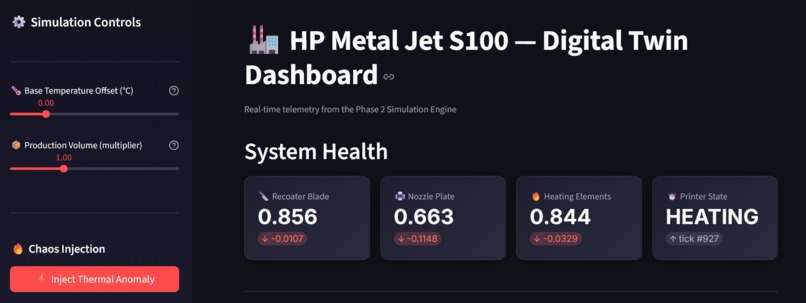
the main dashboard
-
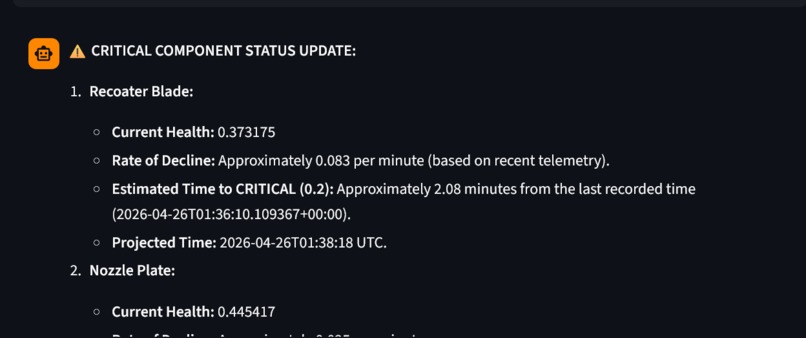
an example of a ReAct Loop
-
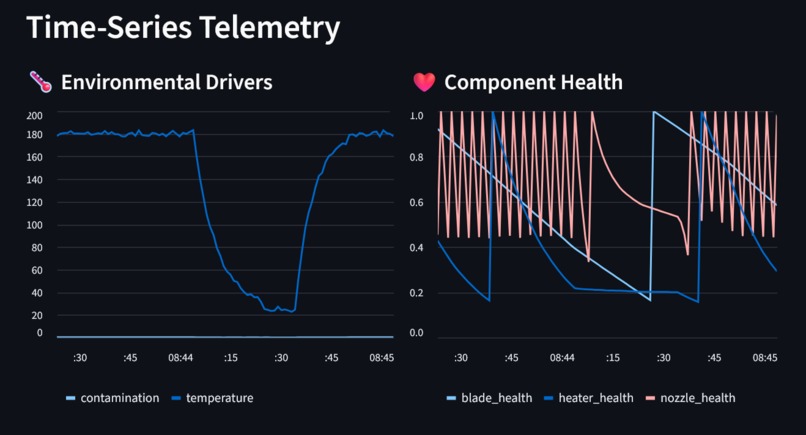
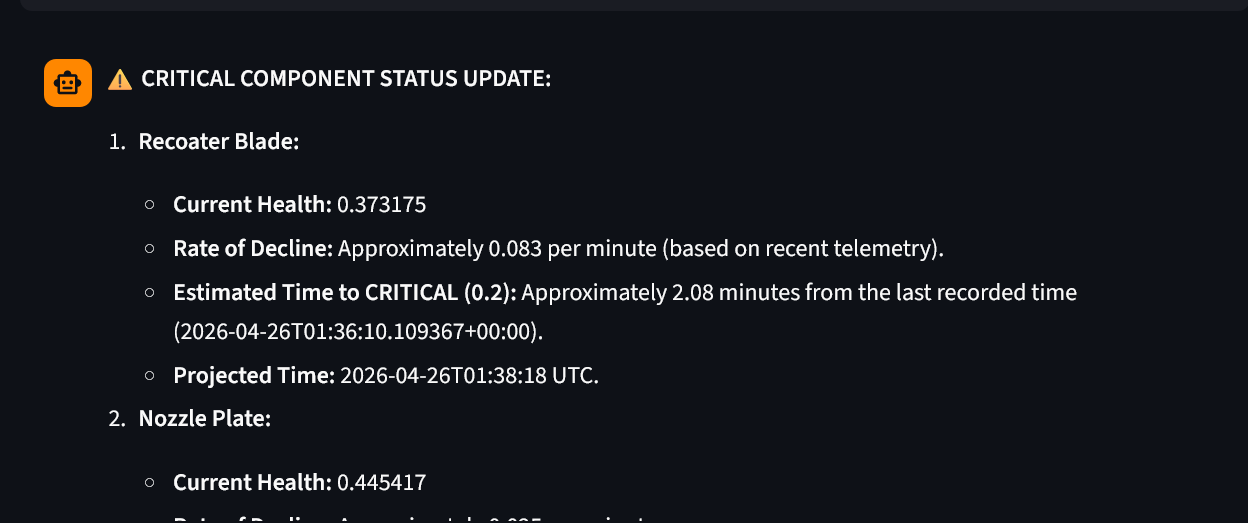
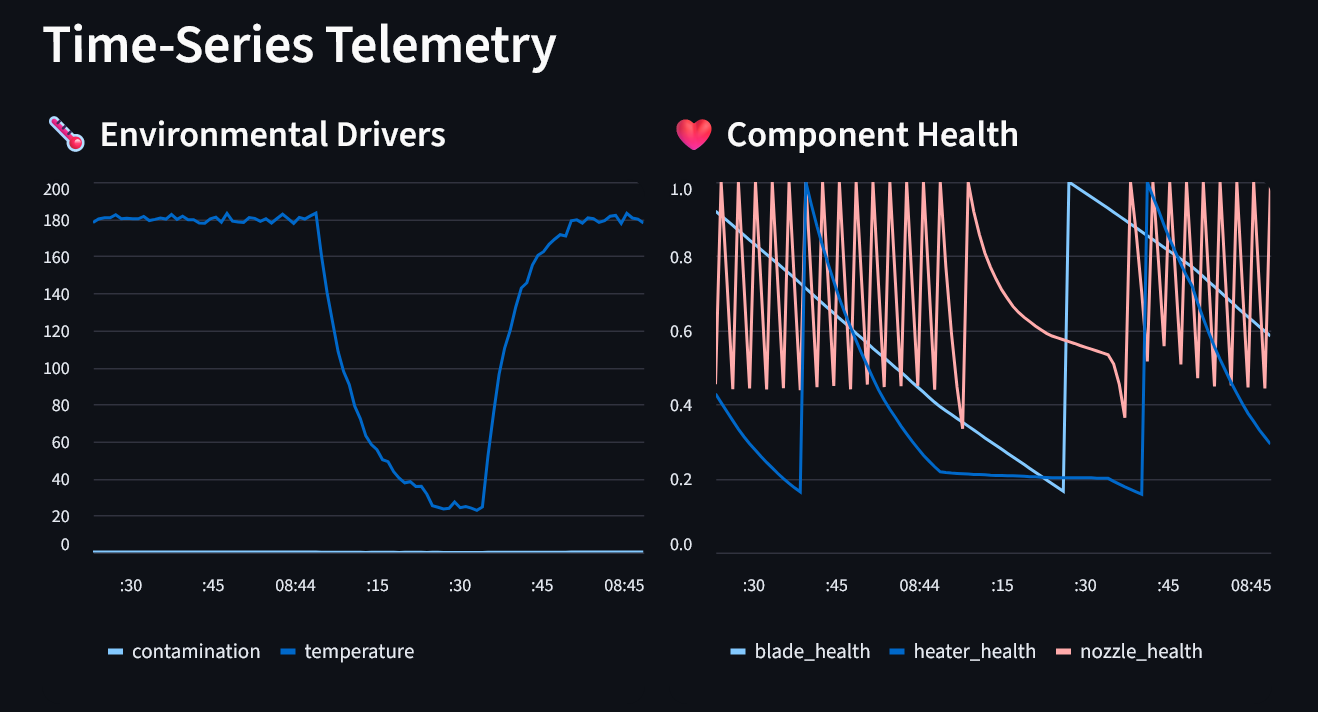
live telemetry dashboard
-
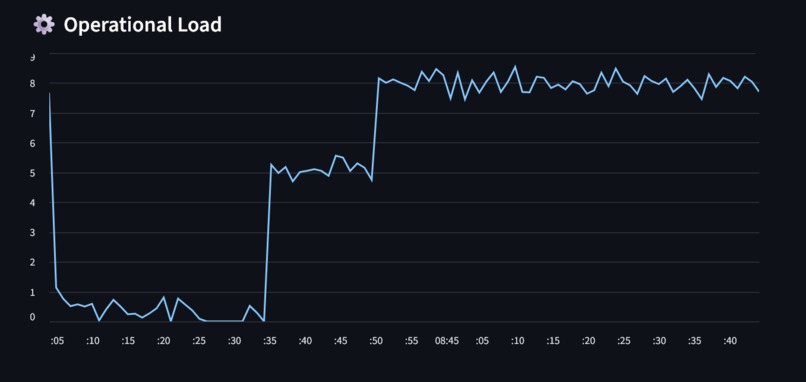
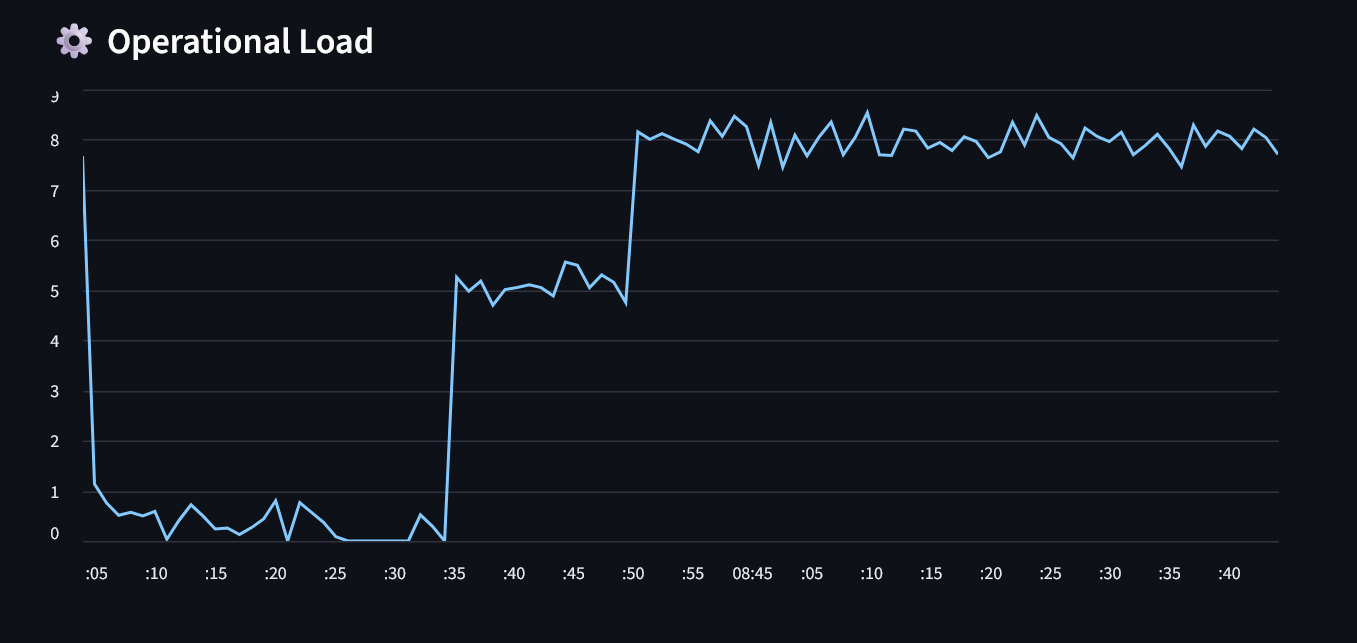
operational load live

Inspiration
As Computer Science students, the task is highly relatable to us as it integrated AI&ML in a real-world industry product.
What it does
Our system is consisted of 3 phases for the HP Metal Jet S100:
Phase 1 (Model): Three physics-based degradation models simulate how the Recoater Blade (linear wear), Nozzle Plate (Weibull thermal fatigue), and Heating Elements (exponential decay $R(t) = e^{-\lambda t}$) degrade under operational stress.
Phase 2 (Simulate): A real-time simulation engine cycles the printer through IDLE → HEATING → PRINTING → COOLDOWN states, injecting Gaussian noise for sensor realism and persisting every tick to a SQLite historian. A proactive maintenance agent monitors health velocities and intervenes before failures occur.
Phase 3 (Interact): An AI Co-Pilot powered by GPT-4o-mini uses a ReAct reasoning loop to autonomously query the historian, chain multi-step investigations, and deliver grounded diagnoses. Every response cites specific timestamps and data points. A neurosymbolic safety firewall ensures the AI can never push parameters outside physical bounds.
Go-Further extensions:
- A Physics-Informed Neural Network (PINN) that learns the heater degradation law while being constrained by the governing ODE $dH/dt = -\lambda \cdot \text{load} \cdot H(t)$, achieving 0.36% MAE.
- An A2C Reinforcement Learning agent that discovers a zero-failure maintenance policy from pure reward signal — no hand-coded rules.
How we built it
Phase 1 was built first as a pure, deterministic Python module (model.py) with an abstract Component base class. Every degradation formula was unit-tested against hand-calculated values before moving on. Phase 2 wrapped Phase 1 in an async simulation loop (engine.py) with a state machine, noise injection, and SQLite persistence. We built a Streamlit dashboard (app.py) with real-time health gauges and what-if controls. Phase 3 was layered on top, querying the Phase 2 historian via SQL. We implemented the reasoning pattern (Pattern C: Agentic Diagnosis) with a ReAct loop that can chain up to 5 tool calls per query. PINN was trained on 100K synthetic samples generated by the Phase 1 heater model, using a dual loss function (data fidelity + physics residual via autograd). RL Agent used an A2C Actor-Critic architecture with a custom environment wrapping the Phase 1 engine. Tech stack: Python 3.10+, PyTorch, NumPy, Streamlit, OpenAI API, SQLite. 132 tests across 5 test suites ensure correctness.
Challenges we ran into
RL reward divergence: Our initial RL agent's reward diverged to -14,000 per episode. The failure penalty was applied every step a component remained failed, creating a compounding negative spiral. Fix: one-time penalty + immediate episode termination on failure.
Temperature spikes breaking the Nozzle Plate: Instantaneous jumps from 25°C to 180°C during state transitions caused the Weibull hazard to spike unrealistically. We solved this with exponential temperature smoothing ($\text{temp} = 25 + (T_{\text{target}} - 25)(1 - e^{-3t/d})$) to model thermal inertia.
Grounding the LLM: Early versions of the AI Co-Pilot would hallucinate component names and invent data. We solved this by enforcing strict system prompt rules, giving it structured SQL tools, and displaying the full reasoning trace so every claim is auditable.
Accomplishments that we're proud of
- Zero-failure RL policy discovered entirely from reward signal, so the agent independently learned when to maintain each component without any human-designed rules.
- PINN with 0.36% error that perfectly satisfies the governing ODE — the physics residual converges to machine epsilon, proving the network learned the actual physics, not just a curve fit.
- 132 automated tests across all modules: we never merged code that broke existing functionality.
- Full auditability: every AI response traces back to specific timestamps in the historian. No black boxes.
- Neurosymbolic safety firewall: the AI can suggest parameter changes, but deterministic bounds-checking prevents physically dangerous adjustments.
What we learned
- Physics constraints make neural networks dramatically more data-efficient. The PINN achieved sub-1% error with simple training because the ODE constraint eliminated most of the function space and the network only had to learn the decay constant, not the entire functional form.
- Reward shaping is everything in RL. The difference between a diverging agent and a zero-failure policy was a single design choice: one-time vs. per-step failure penalties.
- LLMs are powerful but need strict guardrails. The ReAct pattern with tool-based grounding transforms a general-purpose LLM into a reliable diagnostic assistant, but only if you never let it answer from training knowledge.
What's next for HP Metal Jet S100 — Digital Twin & AI Co-Pilot
- Cascading failure models: creating realistic inter-component failure chains.
- Live environmental data: connecting real weather APIs to drive temperature and humidity inputs, bridging the gap between simulation and reality.
- Containerised deployment — packaging the entire pipeline in Docker for one-command deployment on any machine.
Built With
- openai
- python
- streamlit

Log in or sign up for Devpost to join the conversation.