
Apollo
Inspiration
In additive manufacturing, downtime is not just a maintenance issue. It affects production schedules, part quality, operator trust, and ultimately cost.
For HP Metal Jet systems, the hardest question is not simply:
"Will something fail?"
The harder operational question is:
"What should we do now, why should we trust that decision, and what would have happened if we chose differently?"
That question inspired Apollo. Industrial printers already produce huge amounts of sensor data, but the hard part is not displaying the data. The hard part is understanding what is happening inside the machine early enough to make a better decision.
Our core example was a thermal-printhead cascade:
- Insulation degrades and starts leaking heat.
- The heater works harder to keep the enclosure stable.
- Binder viscosity changes with temperature.
- The nozzle spray pattern becomes unstable and eventually clogs.
- The dashboard says "nozzle failure," even though the root cause started in the thermal subsystem.
Apollo is our attempt to build the reasoning layer behind that machine: a physics-grounded digital twin that can run the printer forward, compare maintenance policies, branch counterfactual universes, and let an operator ask an AI agent why a component is failing with citations back to the simulated historian.
What it does
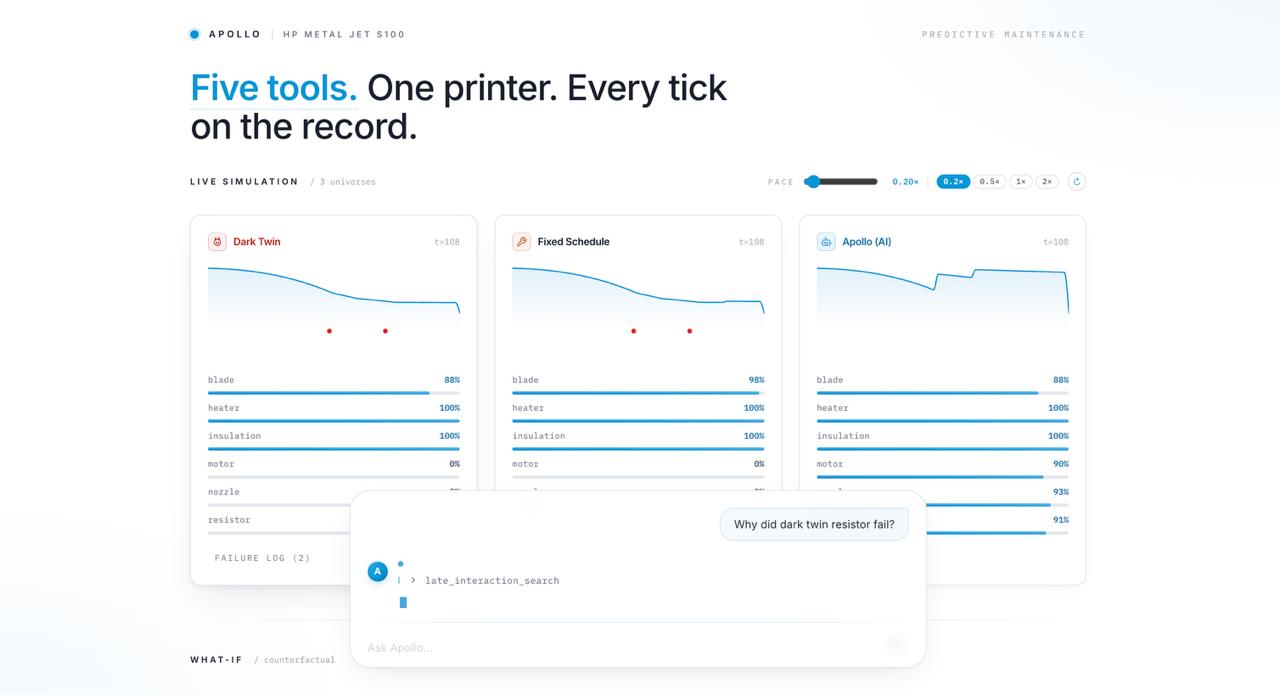
Apollo simulates an HP Metal Jet S100-class industrial metal binder-jet printer with six components across three subsystems:
- Recoating: recoater blade and drive motor
- Printhead: nozzle plate and thermal firing resistors
- Thermal: heating element and insulation panel
Each component ages under a failure model matched to its physical mechanism: exponential wear, Weibull time-to-failure, Coffin-Manson thermal fatigue, and a Physics-Informed Neural Network for the heating element. The components are then coupled through a 6x6 matrix and three named cascades:
- CSC-A: blade wear -> bed unevenness -> motor torque -> bearing fatigue
- CSC-B: insulation -> heater duty -> enclosure temperature -> binder viscosity -> nozzle clog -> resistor stress
- CSC-C: blade ceramic flaking -> powder contamination -> nozzle clog
On top of the simulator, Apollo runs a three-policy benchmark:
- Dark Twin: no maintenance
- Fixed: calendar or threshold maintenance
- AI: a Genetic Algorithm-optimized maintenance policy
The agent side lets users ask questions such as:
- "Why is the nozzle failing?"
- "When did the Dark Twin lose its first component?"
- "What if we replaced the blade at hour 4?"
- "Compare AI maintenance against fixed maintenance."
Apollo answers through tools, not vibes. It can inspect history, search telemetry, compare runs, branch counterfactuals, and explain what changed. Every non-refusal answer must cite a real historian record, or the response is refused instead of hallucinated.
How we built it
The project is split into three bounded contexts:
src/engine: component physics, failure models, coupling, PINN, forecastssrc/sim: scenarios, run loop, historian, policies, GA, counterfactuals, retrievalsrc/apolloandfrontend: agent tools, citations, streaming, React UI
The backend is Python with FastAPI, NumPy, SQLite, DeepXDE, MAPIE, DEAP, PyLate, Pydantic, and SSE streaming. The frontend is React, Vite, Tailwind, and Recharts. The runtime agent path uses Gemma 4 31B with a GEPA-compiled prompt, while the evaluator uses Ragas and DeepEval to test faithfulness and hallucination behavior.
We treated architecture as part of the product. The repo contains 22 ADRs that document why we chose a simple coupling matrix over a Bayesian network, a Genetic Algorithm over reinforcement learning, exact simulator branching over causal inference, late-interaction retrieval over plain dense embeddings, and a strict citation pipeline over trust-the-prompt grounding.
Strong technical decisions
We deliberately chose technically challenging pieces where they made the product more defensible:
- Three physics-backed failure families instead of one generic degradation curve: exponential wear, Weibull reliability, and Coffin-Manson thermal fatigue.
- ISO 281:2007 for bearing-life reasoning, plus IPC-9701A and ASTM E2714-13 for thermal/mechanical fatigue context.
- A single heating-element PINN, not "AI everywhere." The PINN is used where a real heat-diffusion PDE exists, and the PDE residual is part of the loss.
- A 6x6 coupling matrix for cascades. It is small enough to explain on a slide and strong enough to make cross-subsystem failures visible.
- Bit-identical deterministic simulation so policy comparisons and counterfactual replay are fair.
- MAPIE/EnbPI conformal intervals so forecasts include calibrated uncertainty, not just point estimates.
- Late-interaction retrieval because telemetry is code-like and numeric-heavy; token-level matching is a better fit than mean-pooled dense embeddings.
- A strict citation/refusal pipeline because industrial AI should say "I do not have enough evidence" instead of fabricating confidence.
Research we used
We wanted the physics and AI choices to be explainable to a technical judge, so we spent a lot of the hackathon reading and translating physics literature into implementation constraints. The important part was not memorizing papers; it was using them to decide which model belongs to which component, which parameters are realistic ranges, and which assumptions we should disclose.
Reliability and degradation models:
- Weibull, W. (1951), "A statistical distribution function of wide applicability"
- Coffin, L. F. (1954), cyclic thermal stress fatigue
- Manson, S. S. (1954), thermal stress fatigue
- Archard, J. F. (1953), contact and rubbing wear
- ISO 281:2007 for rolling bearing life
- IPC-9701A and ASTM E2714-13 for thermal/mechanical fatigue context
Additive manufacturing, printhead, and materials context:
- Goh et al. (2020), machine learning in 3D printing
- Bernard et al. (2023), metal additive manufacturing trends
- Hou et al. (2022), online monitoring for metal powder bed fusion
- Han et al. (2020), polymer materials for additive manufacturing
- IS&T Print4Fab 2020 thermal inkjet micro-heater / printhead lifetime study
- Aghababaei, Warner, and Molinari (2016), adhesive wear mechanisms
- Vakis et al. (2018), tribology modeling across scales
Physics-informed ML:
- Raissi, Perdikaris, and Karniadakis (2019), Physics-Informed Neural Networks
- Lu, Meng, Mao, and Karniadakis (2021), DeepXDE
- Karniadakis et al. (2021), physics-informed machine learning
- Cuomo et al. (2022), survey of scientific machine learning with PINNs
Forecasting and uncertainty:
- Xu and Xie, "Conformal Prediction Interval for Dynamic Time-Series" (EnbPI), ICML 2021
- MAPIE for conformal prediction intervals
Retrieval and agent evaluation:
- Khattab and Zaharia (2020), ColBERT late-interaction retrieval
- Ragas and DeepEval for grounded answer evaluation
- Agrawal et al., GEPA prompt optimization
- DSPy for declarative LM program compilation
Challenges we ran into
The biggest challenge was making the project look like one coherent system instead of several impressive demos duct-taped together.
The physics model had to be simple enough to finish in a hackathon, but not so simple that a judge could dismiss it as arbitrary. That meant mapping each component to a failure family, keeping the math deterministic, and disclosing which parameter values were literature-anchored ranges versus synthetic point estimates chosen to make a 10-hour demo scenario resolve. This was much harder than just fitting a curve: we had to study enough physics to know when exponential wear, Weibull reliability, Coffin-Manson fatigue, or a PINN was the right abstraction.
The cascades were also hard to tune. If coupling is too weak, nothing happens on stage. If coupling is too strong, everything collapses at once and the agent has no useful story to tell. We had to balance three cascades so the Dark Twin fails visibly while the AI policy can still intervene.
The PINN was another tradeoff. A real 3D heater model was out of scope, so we reduced the heating element to a 1D heat-diffusion PDE. That gave us a neural model with a real physical residual in its loss, while still fitting within laptop training and CPU inference constraints.
The standards and literature work was a challenge of its own. We used ISO 281 to anchor bearing-life thinking, thermal-fatigue standards to justify Coffin-Manson-style reasoning, and additive-manufacturing literature to keep the printhead, binder, and blade stories physically plausible. That research shaped the code, not just the write-up.
The agent was the most fragile surface. Prompt-only grounding is not enough for industrial operations, so we built a stricter path: Pydantic schemas, typed tools, citations that resolve against SQLite, and a refusal template when the data does not support an answer. That forced us to make the historian schema, component enum, timestamps, tool contracts, and frontend citations all line up.
The retrieval problem was unexpectedly specific. Generic embeddings are good
for prose, but our telemetry rows look like code: nozzle_clog_prob=0.31,
motor_rpm=4820, psd_d50=24.5um. We chose late-interaction retrieval because
token-level MaxSim preserves those small but important tokens better than
mean-pooled dense vectors.
The maintenance optimizer was also a design battle. Reinforcement learning sounds attractive, but it would have been slow, unstable, and hard to defend. We used a Genetic Algorithm because the policy is only seven numbers, the fitness curve is visible, and the result is explainable.
Accomplishments that we're proud of
We are proud that Apollo feels like an actual product, not a collection of separate hackathon features. The simulator, historian, optimization loop, counterfactual engine, grounded agent, and frontend all reinforce the same idea: an industrial AI system should understand the machine, not just summarize sensor readings.
The most innovative part is the combination. We did not build only a digital twin, only a chatbot, only a dashboard, or only a maintenance optimizer. We connected all of them: the AI can inspect simulated physics, explain cascading failure, compare policy outcomes, branch an alternate universe, and cite the exact operational record behind its answer.
We are especially proud of the "Dark Twin" framing. Instead of showing a static baseline, Apollo shows the alternate universe where no intelligent maintenance was watching. That turns policy comparison into something judges can understand immediately: here is the machine with Apollo, and here is the same machine without it.
We are proud that the product is innovative without being hand-wavy. The failure models are literature-anchored, the motor reasoning references ISO 281 bearing life, the PINN has a real heat-equation residual, the forecast bands are conformal intervals, and the agent is forced to ground every non-refusal answer in the historian. That made Apollo feel more like decision intelligence for a factory floor than a generic AI assistant.
We are proud of the counterfactual experience. Since we own the simulator, "what if we repaired this part earlier?" is not a guess or a generated story. Apollo can branch the same run from the same state, apply the alternate action, and show the difference.
We are proud that we built a system we could defend technically. Every major tradeoff is documented in an ADR: why three failure families, why one PINN, why GA instead of RL, why MAPIE, why late-interaction retrieval, why strict citations, and why Gemma plus GEPA.
What we learned
Almost every important part of Apollo was something we had never built before. We had used models and dashboards before, but we had never built a physics-based digital twin, trained a PINN, added conformal prediction intervals, implemented late-interaction retrieval over telemetry, evolved a maintenance policy with a Genetic Algorithm, and wrapped the whole thing in a citation-enforced agent in one project. Getting those pieces to work together was an amazing experience.
We learned that the most exciting AI systems are often hybrid systems. The LLM was not the product by itself. It became powerful because it had tools connected to physics, history, counterfactuals, and optimization. That changed how we think about agents: the intelligence is in the loop between the model and the system it can operate.
We learned how hard, and how rewarding, it is to translate papers into running software. Reading about Weibull failure, Coffin-Manson fatigue, PINNs, EnbPI, late-on-code-edge, and GEPA is one thing. Turning those ideas into code, tests, UI, and a demo story under time pressure is completely different. We had never before needed to connect ISO standards, thermal physics, reliability engineering, AI evaluation, and frontend product design in one system, and doing that was one of the most valuable parts of the project.
We learned that uncertainty makes a product feel more honest. Before this, it was tempting to show only point predictions because they are cleaner. After building forecast bands, we realized that showing "I expect this, with this much confidence" is a better operator experience.
We learned that a refusal can be a product feature. In most demos, refusing to answer feels like failure. In Apollo, a refusal means the system protected the operator from an unsupported claim. That was a new way for us to think about trustworthy AI.
Finally, we learned how much architecture matters in a short hackathon. Splitting the work into engine, simulation, and agent/presentation let us move quickly without losing the product shape. It was one of the most ambitious builds we have attempted, and seeing the pieces connect was the best part of the weekend.
What's next
The next step would be replacing synthetic calibration with real printer data and validating the component parameters against observed failures. We would also extend the policy beyond static thresholds, add richer maintenance actions, stress-test the conformal intervals under regime shifts, and benchmark the retrieval and agent loop on larger historian datasets.
Longer term, Apollo could become a general pattern for industrial AI systems: physics first, simulator second, agent third, and every generated answer grounded in a traceable operational record.
Built With
- claude
- claude-agent-sdk
- deap
- deepeval
- deepxde
- dspy
- fastapi
- gemma
- gepa
- javascript
- langfuse
- mapie
- opentelemetry
- openweathermap
- pydantic
- pylate
- python
- pytorch
- ragas
- react
- recharts
- sqlite
- sse-starlette
- tailwindcss
- typescript
- vite




Log in or sign up for Devpost to join the conversation.