Inspiration
Public support systems, especially housing and community benefits, are often fragmented and painfully slow. People in crisis are forced to wait in long queues, while administrators drown in paperwork, struggling to verify documents and prioritize the most urgent cases fairly. We were inspired to build HouseHub+ to fix this broken pipeline and reduce friction in accessing essential services. We wanted to create an intelligent triage system that speeds up resource allocation without removing human empathy or compromising citizen privacy.
What it does
HouseHub+ is a secure, AI-powered housing benefits navigator divided into two seamless experiences:
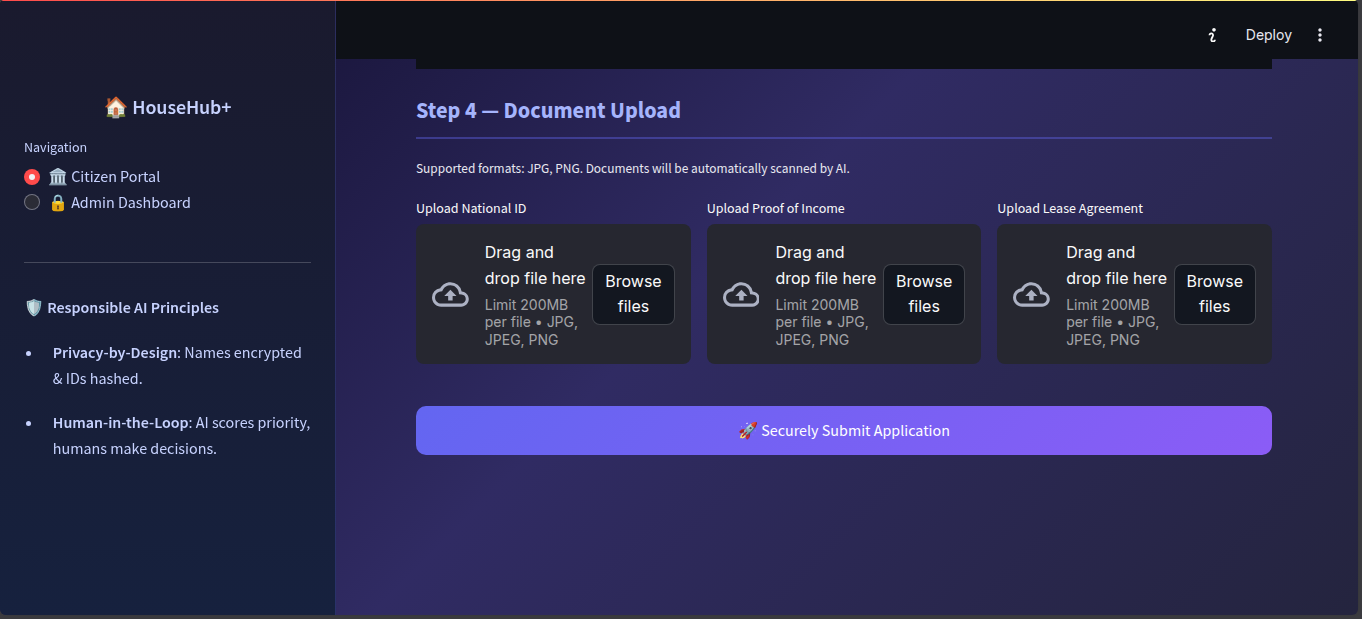
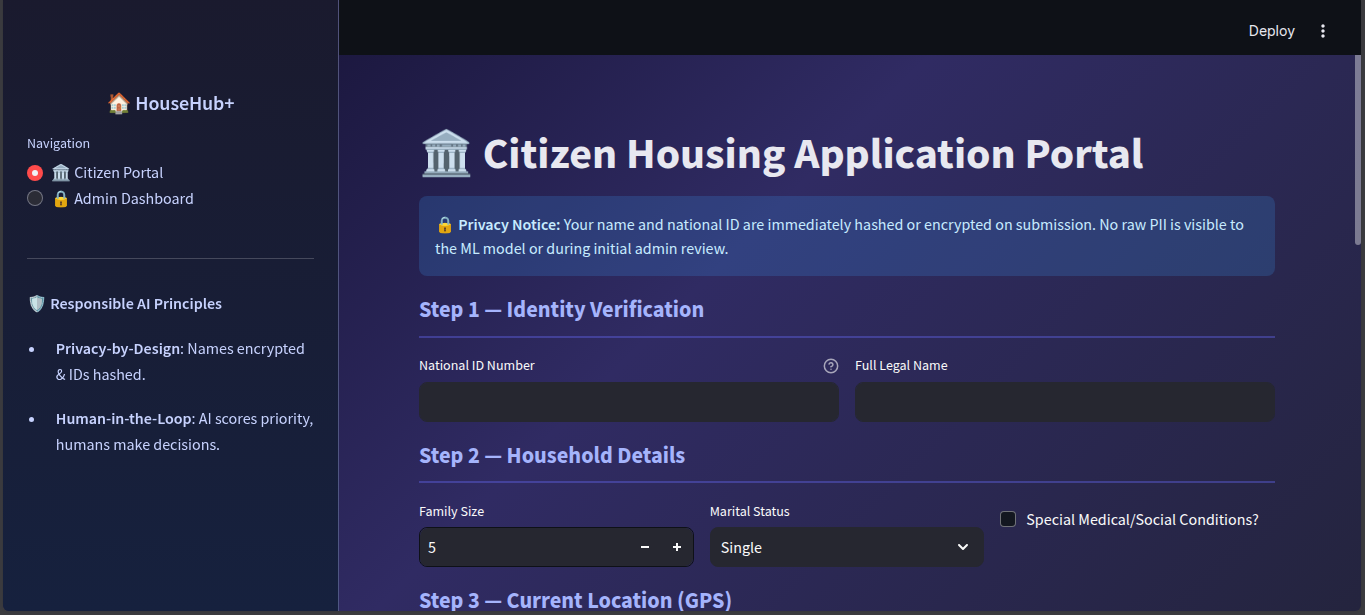
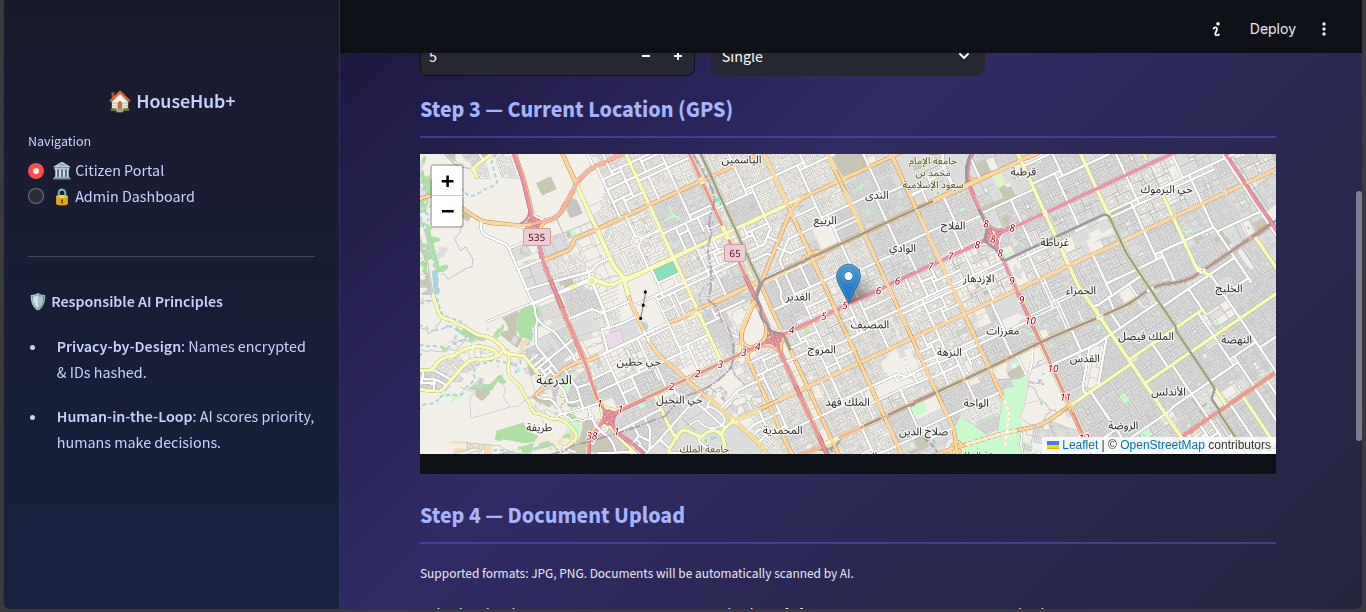
- The Citizen Portal: A secure interface where applicants submit their demographic details, general location, and official documents (Income/Lease).
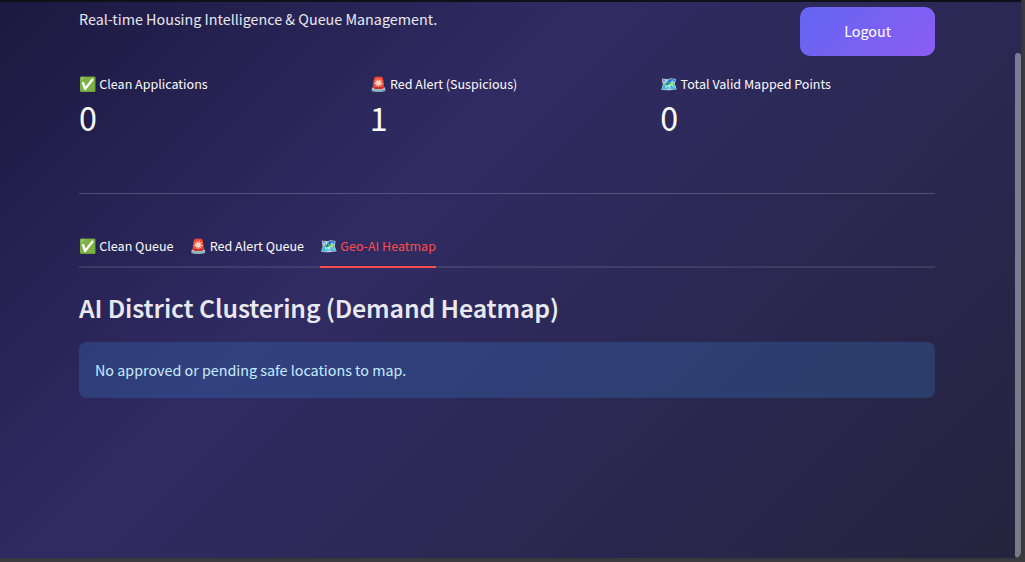
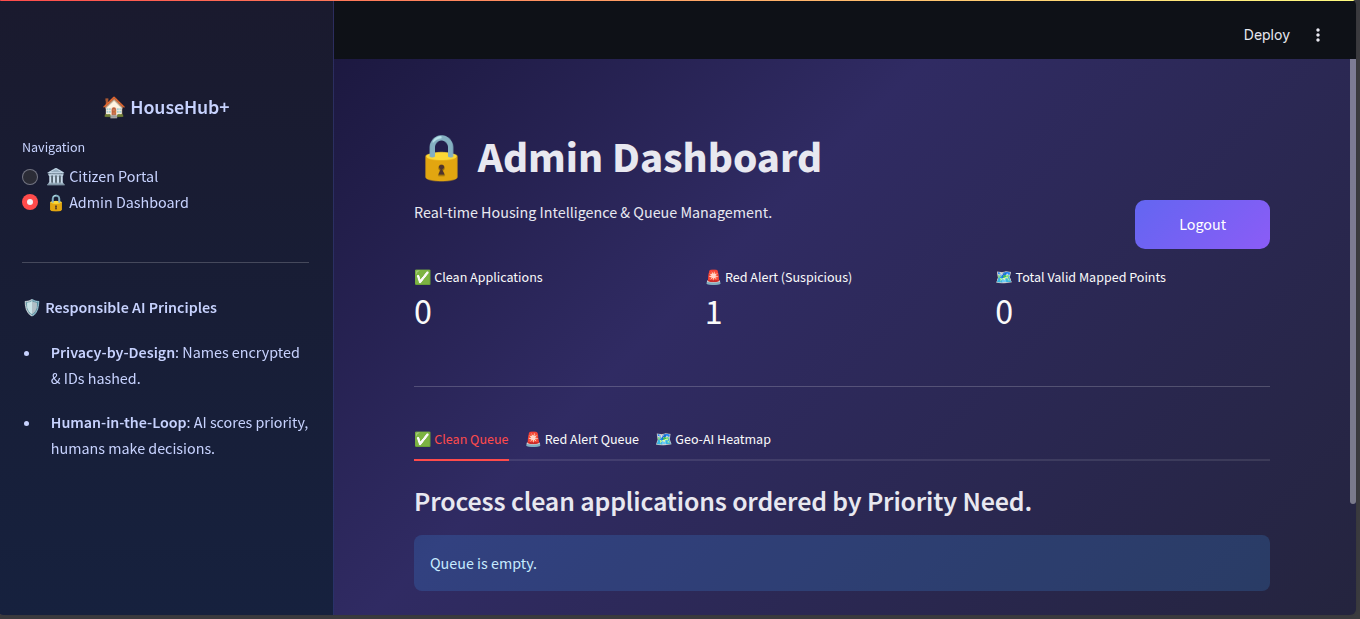
- The Admin Dashboard: An actionable decision-support hub for government or NGO workers. Instead of a messy inbox, admins see a sorted queue prioritized by a Machine Learning-generated "Need Score".
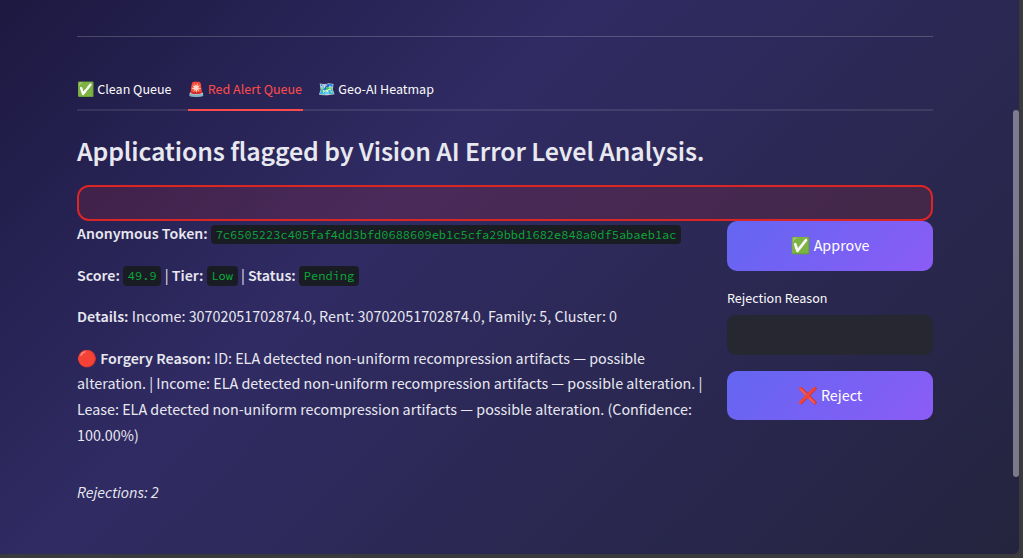
Crucially, it features a Red Alert Queue. If our computer vision models detect a forged document or fail to read it, the application isn't blindly rejected by the AI. Instead, it is routed to this queue for manual human inspection, keeping the human firmly in the loop.
How we built it
We architected HouseHub+ with a strict focus on modularity and security:
- Frontend & UI: Built using
Streamlitfor a highly interactive, responsive dashboard, paired withFoliumto generate localized heatmaps. - Privacy & Security Layer: Implemented
cryptography(Fernet) for AES-256 encryption of names, andhashlibfor SHA-256 one-way hashing of National IDs. - Vision AI: We combined
OpenCVusing Error Level Analysis (ELA) to detect image manipulation/forgery, andEasyOCR(initialized for both English and Eastern Arabic numerals) to extract financial figures inclusively. - Priority & Geo-AI: We trained a
Scikit-LearnRandomForestRegressor on synthetic demographic data to output a normalized Need Score (0-100) and Tier. We also deployed a KMeans clustering model on GPS coordinates to map high-demand districts without pinpointing individual addresses. - Database: Managed via
SQLitewith strictON CONFLICTschemas to decouple personally identifiable information (PII) from assessment data.
Challenges we ran into
Building a production-ready MVP in a few days presented several hurdles:
- Memory Management: Loading heavy ML models and OCR readers concurrently caused memory leaks. We solved this by implementing strict singleton patterns and
@st.cache_resourcedecorators. - OCR Reliability & Over-reliance: We realized that poor-quality images caused the OCR to output zeros, which could lead to unfair scoring if the system blindly trusted the AI. We mitigated this over-reliance risk by implementing a strict AI Guardrail: if OCR extraction fails, the AI stops scoring and immediately flags the application for human review.
- Backward Incompatibility: Upgrading our encryption from basic encoding to military-grade AES-256 risked breaking the database. We built graceful fallbacks using
try/exceptblocks to handle legacy records securely.
Accomplishments that we're proud of
- Privacy-by-Design: We successfully decoupled citizen identities from their financial data. An admin only sees a hashed
User_Tokenand a Need Score. The applicant's real name is only decrypted the exact moment an admin clicks "Approve". - True Human-in-the-Loop: We successfully mitigated the risk of automated rejections. Our AI acts only as an advisor and fraud-detector, leaving the final, empathetic decision to the human administrator.
- Inclusivity: By ensuring our OCR natively supports Eastern Arabic numerals alongside English, we built a tool that respects local nuances and doesn't marginalize non-English speaking citizens.
What we learned
We learned that "Responsible AI" is not just a buzzword; it requires deliberate software engineering choices. We learned how to balance the speed of Machine Learning with the necessity of privacy (using hashing/encryption) and fairness (using inclusive OCR and human oversight) to provide real impact and decision value.
What's next for HouseHub+
Our immediate next steps include migrating the backend to PostgreSQL to handle millions of concurrent applications, deploying the containerized app via Docker to AWS, and upgrading our document verification from basic OCR to deep-learning-based Document AI (like LayoutLM) for full structural understanding of governmental forms.
Built With
- cryptography
- docker
- easyocr
- folium
- opencv
- pytest
- python
- scikit-learn
- sqlite
- streamlit


Log in or sign up for Devpost to join the conversation.