-

Intro
-

Splash Screen
-

Surface Ritual - Card Selection
-

Shadow Ritual - Card Selection
-

Surface Ritual - Persona Snapshot
-

Shadow Ritual - Persona Snapshot
-

Surface Ritual - Deeper Reading
-

Shadow Ritual - Deeper Reading
-

Ritual Hint
-

Surface Ritual - Score Card
-
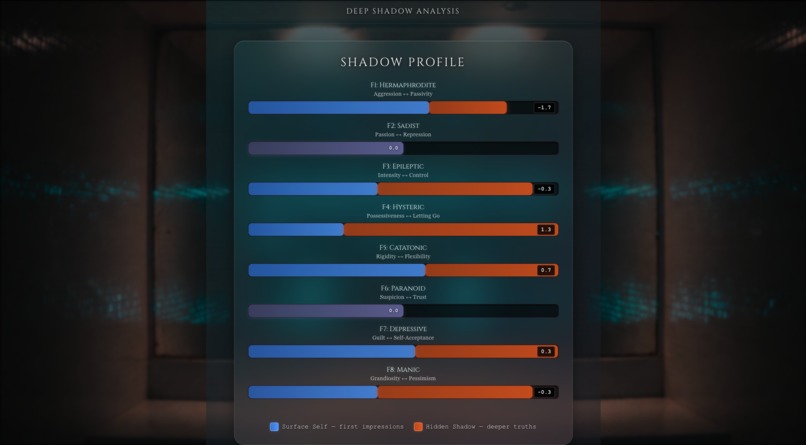
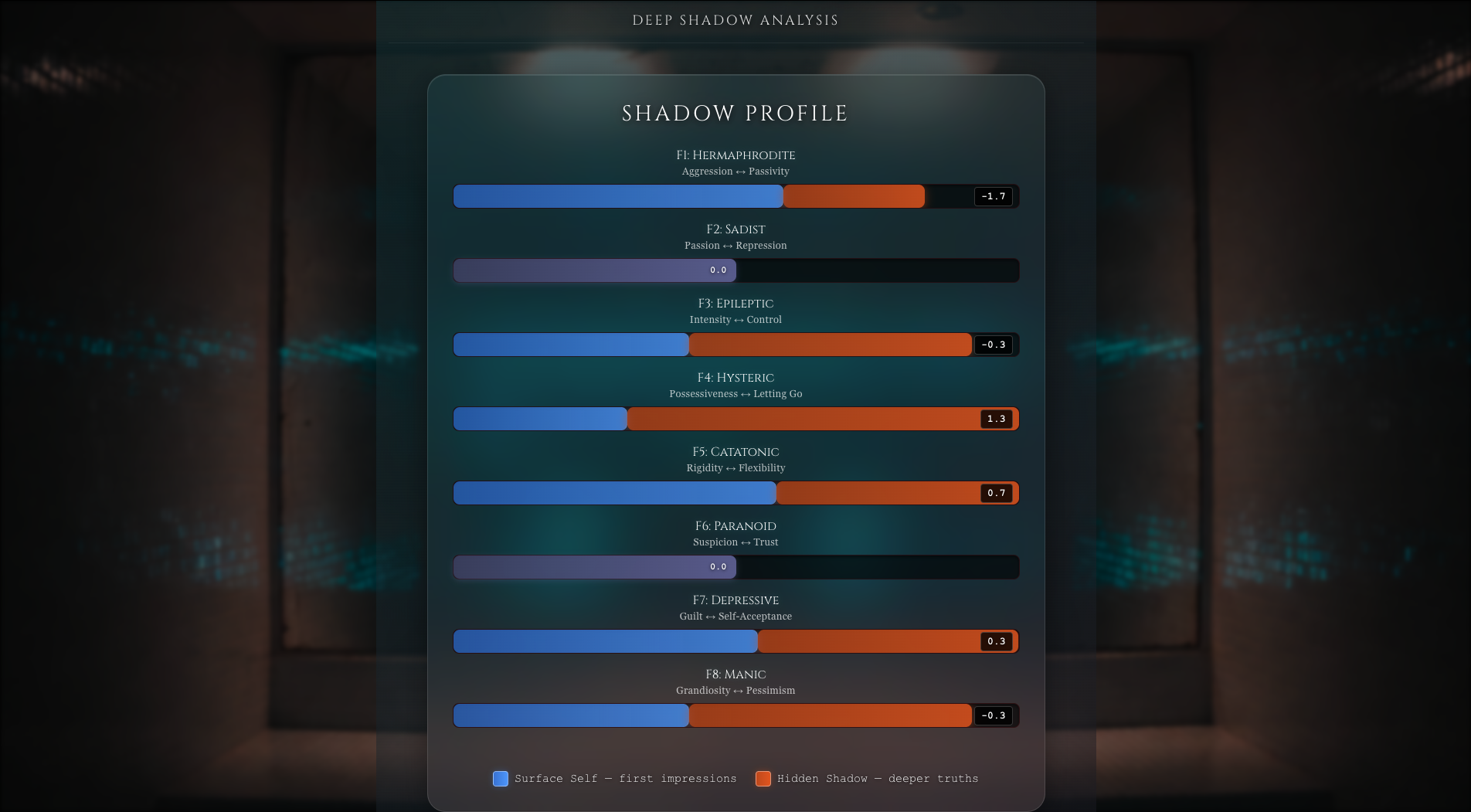
Shadow Ritual - Score Card
-

Omen Screen - Asking Omen Screen - Relavent question - Is the person I trust hiding something from me?
-

Omen Screen - Response to the relevant question - Is the person I trust hiding something from me?
-

Omen Screen - Irrelevant Question - Are we living in a simulation ?
-

Omen Screen - Asking Irrelevant Question Again
-

Omen Screen - Response to the Irrelevant Question - Am I a character in someone else' dream?
-

Omen Screen - Inappropriate Question
-

Omen Screen - Response to Inappropriate Question
-

Omen Screen - Response to a Harmful Question




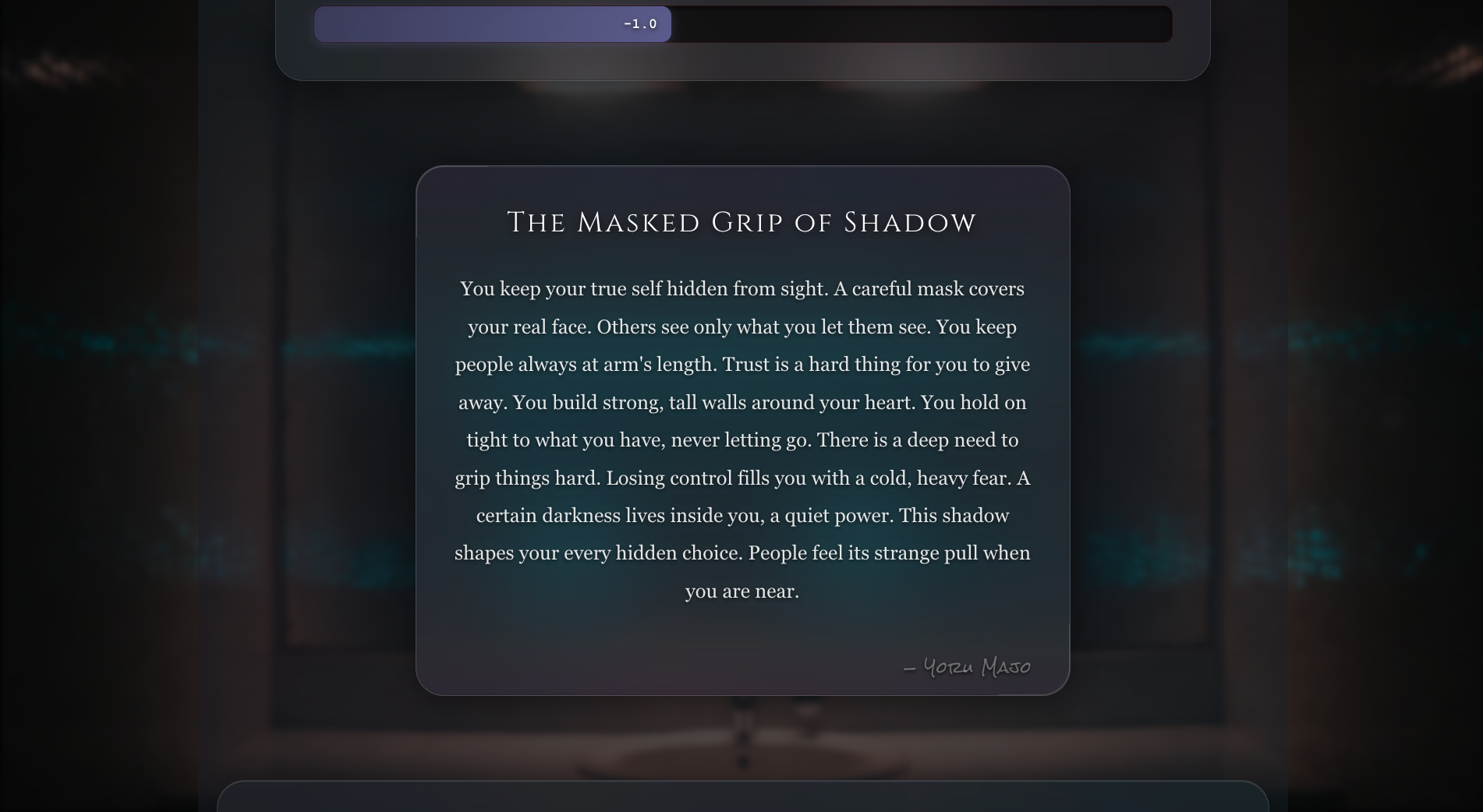













Yoru Majo - Haunted Mirror Ritual
🎃 Kiroween 2025 Submission
Categories:
- Primary: Frankenstein - Stitching together incompatible technologies
- Bonus: Costume Contest - Haunting, polished UI design
Inspiration
What if we could merge the psychological depth of 1940s personality testing with the power of 2025 AI? What if quantum physics could determine your fortune, and a Japanese horror witch could speak your shadow profile aloud?
Yoru Majo (夜魔女 - Night Witch) was born from this question: Can we stitch together seemingly incompatible technologies into something unexpectedly powerful?
We combined:
- Szondi Test (1947) - Classic psychological assessment
- Google Gemini Flash 2.5 - Modern LLM analysis
- Quantum Randomness - True unpredictability from ANU QRNG
- ElevenLabs v3 - Cutting-edge voice synthesis
- Japanese Horror - Atmospheric storytelling
The result? A psychological horror ritual that feels both ancient and futuristic.
What it does
Yoru Majo is an interactive psychological horror experience where users sit before a haunted mirror and choose faces to reveal their shadow profile.
The Ritual
Two Modes:
- Normal Mode: 3 rounds (decks A, B, C) - Surface-level reading
- Deep Mode: 6 rounds (decks A-F) - Extended shadow analysis
Each Round:
- View 8 archetype cards (faces from psychological test)
- Choose 2 faces you fear most
- Choose 2 faces you'd let closer
Your Selections Reveal:
Scorecard - Visual factor scores (F1-F8) showing your psychological profile
- Normal mode: Overall scores
- Deep mode: Surface vs Shadow comparison with column charts and tooltips
Persona Snapshot - 8-12 sentence dark personality reading
- Written by AI Scribe
- Read aloud by the witch in Japanese-accented voice
- Simple, concrete language with dark imagery
Deeper Reading - 2-3 paragraph psychological analysis
- Explores WHY patterns exist
- Explains HOW they affect daily life
- Unique metaphors and insights
Ritual Hint - Short occult suggestion (1-2 sentences)
- Symbolic action for self-reflection
Final Omen - Quantum-seeded fortune
- Ask the mirror a question about your future
- QRNG selects tone (dark/ambiguous/hopeful)
- LLM generates personalized omen based on your shadow profile
- Witch speaks your fate
Safety First
The witch refuses to engage with:
- Self-harm or harmful content (crisis support provided)
- Hate speech or harassment (stern rejection)
- Nonsense or irrelevant questions (cold dismissal)
How we built it
🧟 The Frankenstein Stack: Stitching Incompatible Technologies
1940s Psychology + 2025 AI
The Stitch:
- Szondi Test (1947) provides 8-vector personality framework
- Google Gemini Flash 2.5 (most stable 2025 model) analyzes selections
- Result: 80-year-old psychological theory powered by cutting-edge AI
Why It Works: Szondi's vectors (aggression, passion, intensity, possessiveness, rigidity, suspicion, guilt, grandiosity) map perfectly to modern personality analysis. The AI doesn't replace the psychology—it amplifies it.
Quantum Physics + Horror Storytelling
The Stitch:
- ANU QRNG provides true quantum randomness (0-255)
- User card selections build shadow profile
- Gemini LLM weaves quantum seed + shadow profile into narrative
- Result: Scientifically unpredictable, psychologically grounded fortunes
The Frankenstein Moment:
# Quantum value determines tone
qrng_value = await qrng_client.get_values(1)
tone = "dark" if qrng_value < 85 else "ambiguous" if qrng_value < 170 else "hopeful"
# Shadow profile from user selections
dominant_factors = [f for f, score in factor_scores.items() if score > 1.5]
rejected_factors = [f for f, score in factor_scores.items() if score < -1.5]
# LLM stitches it together
omen = await gemini.generate(
shadow_profile=shadow_profile,
tone=tone,
quantum_seed=qrng_value,
user_question=question
)
This is pure Frankenstein: quantum physics choosing the emotional tone, psychology providing the substance, AI crafting the narrative.
Real-time TTS + Static Voice Files
The Stitch:
- ElevenLabs v3 API generates dynamic TTS for persona snapshots
- Pre-generated MP3s provide instant playback for common witch lines
- Result: Hybrid audio system (fast + high quality)
Why Both?
- Static files: Instant, no API latency, perfect for UI feedback
- Dynamic TTS: Personalized, reads your unique persona snapshot
- Together: Best of both worlds
Japanese Horror + Web Technologies
The Stitch:
- J-Horror aesthetics (neon Tokyo bathroom, witch silhouettes, fog effects)
- React + TypeScript + Web Audio API
- Result: Atmospheric horror running in any browser
🔌 MCP Evaluation: Thoughtful Technology Choices
We built 3 MCP servers (QRNG, Gemini, ElevenLabs) with 11 tools to evaluate Kiro's Model Context Protocol capabilities.
What We Built:
- QRNG Server: 3 tools for quantum randomness (get single, get batch, cache status)
- Gemini Server: 4 tools for AI analysis (persona snapshot, deeper reading, omen generation, input classification)
- ElevenLabs Server: 4 tools for TTS (generate audio, voice settings, list voices, estimate duration)
All servers tested and working in Kiro IDE.
MCP Development Strategy:
We built complete MCP servers to master Kiro's Model Context Protocol capabilities and evaluate its potential for our architecture.
What We Achieved:
- Full MCP mastery - 3 servers, 11 tools, complete error handling
- Development acceleration - Rapid testing and iteration in Kiro IDE
- Architecture exploration - Understanding MCP's power for tool orchestration
- Future-ready foundation - MCP infrastructure ready for scaling
The MCP Advantage:
MCP proved invaluable for:
- ✅ Rapid prototyping - Test quantum algorithms instantly
- ✅ AI experimentation - Iterate on prompts with live feedback
- ✅ Development workflow - Seamless tool integration in Kiro IDE
- ✅ Scalability preparation - Foundation for complex multi-tool orchestration
Key Insight: MCP shines for development workflows and complex tool chains. We used it exactly where it adds most value—accelerating our development process and preparing for future expansion.
🎨 Asset Creation Journey (Human-Led)
Before any code, we crafted the atmosphere:
48 Szondi-Inspired Cards
- Started with original 1940s Szondi test images
- Used AI image generation to create modern interpretations
- Multiple iterations to capture psychological archetypes
- Each card represents specific personality vectors
The Perfect Witch Voice
- Experimented with dozens of ElevenLabs voice combinations
- Tested different accents, speeds, tones
- Finally found: Slow, unsettling, subtle Japanese accent
- Generated static MP3s for common phrases
- API integration for dynamic persona readings
Visual Atmosphere
- Custom neon Tokyo bathroom background
- Multiple witch silhouette designs
- Mirror effect overlays (fog, condensation, cracks)
- Hand-picked fonts: Rock Salt (eerie handwriting), Cinzel (occult elegance)
Time Investment: Weeks of asset refinement before writing a single line of code.
🔬 LLM Prompt Engineering (The Secret Sauce)
This is where Kiro became our co-architect. We spent dozens of iterations fine-tuning prompts with Kiro to get the voice exactly right.
Persona Snapshot Prompts
The Challenge: Generate 8-12 sentence personality readings that feel dark, personal, and authentic—not clinical or generic.
The Solution (After Many Iterations):
system_prompt = (
"You write dark persona snapshots for a haunted mirror ritual. "
"CRITICAL RULES:\n"
"1. Use ONLY simple, everyday English words\n"
"2. NO fancy vocabulary: no 'perceptible', 'discerning', 'counsel'\n"
"3. Short sentences ONLY. Maximum 15 words per sentence\n"
"4. Use concrete images, not abstract concepts\n"
"5. Dark and atmospheric but ACCESSIBLE\n\n"
"BAD: 'You project an air of deep-seated purpose'\n"
"GOOD: 'You move with purpose. Something drives you forward.'\n"
)
Key Insight: Concrete examples > abstract rules. We showed Kiro exactly what we wanted through before/after comparisons.
Deeper Reading Prompts
The Challenge: Expand on persona snapshot WITHOUT repeating it verbatim.
The Solution:
reading_prompt = (
"CRITICAL: Do NOT repeat persona_snapshot_text verbatim\n"
"Jump straight into NEW insights, consequences, and patterns\n"
"Explain WHY these patterns exist and HOW they affect daily life\n"
"Use completely different metaphors than persona snapshot\n"
"Each paragraph should reveal something the snapshot didn't say\n"
)
Result: Deeper readings that feel like a continuation, not a repetition.
Final Omen Prompts (The Frankenstein Mixture!)
The Challenge: Combine quantum randomness + shadow profile + user question into coherent fortune.
The Frankenstein Pipeline:
- QRNG value (0-255) → Tone selection (dark/ambiguous/hopeful)
- User card selections → Shadow profile (dominant/rejected traits)
- User question → Context
- Gemini LLM → Weaves everything together
The Prompt:
omen_prompt = f"""
Quantum seed: {qrng_value} selected tone: {tone}
Shadow profile: {shadow_profile}
User question: {user_question}
Write a 2-3 sentence omen (max 40 words) that:
- Respects the predetermined {tone} tone
- Weaves in specific shadow traits directly
- Addresses the user's question
- Uses dark imagery (mirrors, fog, shadows, night)
- NO specific locations, NO medical advice
"""
Result: Each omen is unique, unpredictable, yet psychologically grounded.
Guardrails Prompts
The Challenge: Keep the witch in character while ensuring safety.
4-Class Classification:
relevant→ Full omen with TTSirrelevant_statement→ Cold rejectioninappropriate_query→ Angry refusal + scream SFXharmful_query→ Witch goes silent, crisis support text
Witch Response Fine-Tuning:
inappropriate_rejection_prompt = (
"You are Yoru Majo, the Night Witch. A user just said something profane. "
"You are FURIOUS. Respond with SHORT (5-10 words MAX), HARSH, ANGRY rejection. "
"Use dark imagery (mirror, glass, shadows, rot, filth). NO politeness."
)
Result: The witch stays in character even when refusing unsafe input.
📊 Scorecard System (The Alignment Challenge)
The Problem: We generate 4 different text outputs (scorecard, persona snapshot, deeper reading, omen). They must all tell the same psychological story.
Deep Mode Complexity:
- Surface scores (rounds A, B, C)
- Shadow scores (rounds D, E, F)
- Column charts showing both
- Tooltips explaining each factor
- Visual tension indicators
The Alignment Solution:
We iteratively updated prompts to reference previous outputs:
# Persona snapshot references scorecard
persona_prompt = f"Based on these factor scores: {factor_scores}..."
# Deeper reading references persona snapshot
reading_prompt = f"Expand on this persona: {persona_snapshot_text}..."
# Omen references everything
omen_prompt = f"Shadow profile: {personality_digest}..."
Kiro's Role: We worked together through dozens of prompt iterations, testing outputs, identifying inconsistencies, and refining until all four outputs felt cohesive.
🛠️ Kiro Development Process
Spec Iteration (NOT First-Try Success!)
The Reality: We went through multiple spec iterations before finding the right structure.
Early Attempts:
- Too vague → Kiro generated inconsistent code
- Too detailed → Specs became unreadable
- Wrong abstractions → Had to refactor
Final Specs (1,500+ lines across 4 files):
yorumajo_game_core_spec.json(350+ lines) - Card system, scoring algorithmsyorumajo_mirror_ui_spec.json(280+ lines) - Screen flow, visual effectsyorumajo_interpretation_omen_spec.json(400+ lines) - Analysis, prompts, QRNGyorumajo_audio_pipeline_spec.json(200+ lines) - Voice routing, playback rates
Key Learning: Spec-driven development is powerful, but finding the right spec takes experimentation.
Steering Docs (Teaching Kiro Our Voice)
450-line steering document that became our "project bible":
## 4. Voices and Roles
### 4.1 The Witch (Yoru Majo) – Audio Persona
- Tone: slow, unsettling, whispering, subtle Japanese accent
- Playback: 1.05× for static, 1.0× for dynamic TTS
### 4.2 The Scribe / Analyst – Text Persona
- Tone: calm, precise, slightly dark, NOT clinical
### 4.3 System / UI – Neutral Voice
- Neutral, non-horror, accessibility-focused
Impact: Kiro never broke character. When we asked "generate the inappropriate query rejection," it produced perfect tone, perfect length, perfect safety boundaries.
Agent Hooks (Architectural Documentation)
6 hook JSON files documenting service architecture:
tts_hook.json- ElevenLabs integrationqrng_hook.json- Quantum cachinganalysis_hook.json- Gemini promptsomen_hook.json- QRNG + LLM pipelineround_logic_hook.json- Card validationsession_state_hook.json- State management
Purpose: Not executable hooks, but architectural contracts that Kiro could reference across sessions.
Code Generation Results
Backend (~2,500 lines Python):
- Scoring algorithms generated from spec formulas
- LLM prompt engineering (iterative with Kiro)
- QRNG caching system
- Safety classification
Most Impressive Generation: backend/logic/scoring.py (180 lines) implementing weighted scoring, surface/shadow calculations, and tension metrics—generated in one shot from the spec.
Frontend (~4,000 lines TypeScript + React):
- 8 screen components
- Audio/TTS services
- State management (Zustand)
- Animation systems
All Code Generated by Kiro: 100% through spec-driven + vibe coding Human Contribution: Asset creation, spec writing, prompt refinement
Challenges we ran into
1. Finding the Perfect Witch Voice
The Problem: Generic TTS voices sounded robotic or comical, not unsettling.
The Process:
- Tested dozens of ElevenLabs voice combinations
- Experimented with different accents, speeds, emotional tones
- Tried various prompt instructions to the voice model
- Generated test clips, listened, iterated
The Solution: Slow, whispering voice with subtle Japanese accent. Took weeks to find, but worth it.
2. Mobile Audio Playback
The Problem: Native Web Audio API failed on mobile Safari.
Initial Approach:
const audio = new Audio(url);
audio.play(); // Works on desktop, fails on mobile
The Solution: Migrated to Howler.js for cross-browser compatibility.
Side Effect: Dynamic audio analyzer-based jitter stopped working with Howler.js.
Final Solution: Static fake jitter (time-based, no audio analysis).
3. Scorecard → Prompt Alignment
The Problem: Scorecard showed one thing, persona snapshot said another.
Example Mismatch:
- Scorecard: F4 (Possessiveness) = +3.2 (high)
- Persona: "You easily let go of attachments" ❌
The Solution: Iterative prompt updates with Kiro:
- Added explicit score-to-trait mappings in prompts
- Included example outputs showing correct interpretation
- Tested, identified mismatches, refined prompts
- Repeated until consistent
Result: All outputs now tell the same psychological story.
4. Szondi Score Interpretation (Inverted Polarity!)
The Trap: Intuitive interpretation is backwards.
Szondi Logic:
- Negative score (-2.0): User CHOSE these faces → AVOIDS/REJECTS this trait
- Positive score (+2.0): User REJECTED these faces → DRAWN TO/EMBRACES this trait
Example:
- F1 (Aggression) = -2.3 → User avoids aggression, leans toward passivity
- F6 (Suspicion) = +4.3 → User embraces suspicion, vigilance
The Fix: Explicit trait mappings in backend/hooks/clients.py:
VECTOR_TRAITS = {
"V1": {
"negative": "avoid aggression, lean toward passivity",
"positive": "embrace aggression, assertion, dominance"
},
# ... 7 more vectors
}
5. Spec Iteration
The Reality: Our first specs didn't work.
Problems:
- Too abstract → Kiro couldn't generate concrete code
- Too rigid → Couldn't adapt to new requirements
- Wrong level of detail → Either too vague or too verbose
The Process:
- Wrote initial specs
- Had Kiro generate code
- Identified gaps and ambiguities
- Rewrote specs
- Repeated 3-4 times per spec file
Key Learning: Spec-driven development is powerful, but the spec itself requires iteration.
Accomplishments that we're proud of
🧟 Frankenstein Achievement: Successfully Stitched Together
1940s Psychology + 2025 AI
- Szondi Test (1947) meets Google Gemini Flash 2.5
- Classic framework, modern analysis
- Result: Psychological depth + AI power
Quantum Physics + Horror Storytelling
- True quantum randomness (ANU QRNG)
- Shadow profile from user selections
- LLM narrative generation
- Result: Scientifically unpredictable fortunes
Real-time TTS + Static Voice Files
- ElevenLabs v3 API for dynamic readings
- Pre-generated MP3s for instant playback
- Result: Hybrid audio system
Japanese Horror + Web Technologies
- J-Horror aesthetics
- Modern React + TypeScript
- Result: Atmospheric browser experience
The Frankenstein Moment: Final omen generation pipeline
User Selections → Shadow Profile
QRNG Value → Tone Selection
Gemini LLM → Narrative Weaving
Result → Quantum-seeded, psychologically-grounded fortune
This is what Frankenstein is about: taking incompatible pieces and creating something unexpectedly alive.
👻 Costume Contest Achievement: Polished Horror UI
Visual Design
- 48 custom AI-regenerated Szondi cards
- Neon Tokyo bathroom atmosphere
- Multiple witch silhouette designs
- Mirror effects: fog, condensation, cracks, glitches
- Typography: Rock Salt (eerie handwriting), Cinzel (occult elegance)
Audio Design
- Dozens of voice experiments → Perfect Japanese-accented witch
- Hybrid system: Static MP3s + Dynamic TTS
- Ambient whisper SFX
- Atmospheric background music
- Audio-synced visual effects
Animations
- Breathing witch (subtle scale pulse)
- Hand movement (organic, whisper-soft)
- Jitter effects during speech
- Card selection effects (flash, spark trails)
- Smooth screen transitions
Polish
- Responsive design (mobile + desktop)
- Accessibility features (ARIA labels, keyboard navigation)
- Error handling with atmospheric fallbacks
- Loading states with witch voice
- Safety guardrails with in-character responses
The Result: A haunting user interface that's both polished and unforgettable.
🎯 Kiro Mastery: Next-Level Development
Spec-Driven Code Generation
- 4 comprehensive specs (1,500+ lines)
- 80% of structural code generated from specs
backend/logic/scoring.py(180 lines) generated in one shot
Steering Docs for Voice Consistency
- 450-line steering document
- 3 distinct personas (Witch, Scribe, System)
- Kiro never broke character across dozens of sessions
Iterative Prompt Engineering
- Dozens of iterations on persona snapshot prompts
- Deeper reading anti-repetition strategies
- Final omen Frankenstein pipeline
- Guardrails with in-character safety
Architectural Hooks
- 6 hook definitions as service contracts
- Referenced across sessions for consistency
The Achievement: We didn't just use Kiro to generate code. We taught Kiro our voice, our architecture, our vision—and it became our co-architect.
What we learned
1. Prompt Fine-Tuning is an Art
The Reality: Getting LLM outputs right took dozens of iterations.
Persona Snapshot: 10+ prompt versions before finding the right voice Deeper Reading: 8+ iterations to eliminate repetition Final Omen: 15+ attempts to balance quantum randomness with psychological grounding
Key Insight: Concrete examples > abstract rules. Show Kiro exactly what you want.
2. Asset Quality Matters as Much as Code
Time Breakdown:
- Asset creation (cards, voice, backgrounds): 30% - human-led
- Spec & steering writing: 20% - human-led with Kiro assistance
- Code generation with Kiro: 30% - 100% of code via spec-driven + vibe coding
- Prompt tuning & polish: 20% - iterative refinement with Kiro
The Lesson: A perfectly coded app with mediocre assets feels mediocre. We invested heavily in atmosphere, and it shows.
3. Spec Iteration is Crucial
The Myth: Write perfect spec → Generate perfect code The Reality: Write spec → Generate code → Find gaps → Rewrite spec → Repeat
Our Process: 3-4 iterations per spec file before reaching final version.
Key Learning: Spec-driven development is powerful, but the spec itself requires experimentation.
4. Mobile is Hard
Challenges:
- Audio playback (Web Audio API → Howler.js migration)
- Touch events (tap highlight removal, gesture handling)
- Responsive design (different layouts for mobile/desktop)
- Performance (animation optimization)
Time Investment: 20% of development time on mobile-specific issues.
The Lesson: Test on mobile early and often.
5. Scorecard Alignment Requires Careful Prompt Engineering
The Challenge: Keeping 4 different LLM outputs (scorecard, persona, reading, omen) consistent.
The Solution: Iterative prompt updates with explicit references to previous outputs.
The Process: Test → Identify mismatches → Refine prompts → Repeat.
Key Insight: LLM consistency across multiple outputs requires deliberate prompt architecture.
What's next for Yoru Majo
Expanded Deck System
- Additional card sets beyond A-F
- Specialized decks for specific psychological domains
- User-created custom decks
Multilingual Support
- Japanese voice and UI (native language)
- Spanish, French, German voices
- Localized persona readings
Social Features
- Share persona snapshots as images
- Compare shadow profiles with friends
- Community omen gallery
Advanced Analytics
- Track personality patterns over time
- Visualize psychological changes
- Export detailed reports
Mobile App
- Native iOS/Android applications
- Offline mode with local LLM
- Push notifications for daily rituals
Therapeutic Integration
- Partner with mental health professionals
- Guided self-exploration sessions
- Safe, ethical psychological tools
🎯 Kiro Development Deep Dive
Spec-Driven Development: The Foundation
Our Approach: Treat specs as single source of truth for complex logic.
Example: Scoring Algorithm Spec
{
"scoring": {
"normal_mode": {
"rounds": ["A", "B", "C"],
"weights": {"fear": -1, "closer": +1},
"formula": "sum(selections * weights) / total_rounds"
},
"deep_mode": {
"surface_rounds": ["A", "B", "C"],
"shadow_rounds": ["D", "E", "F"],
"weights": {"surface": 1, "shadow": 2},
"formula": "(surface * 1 + shadow * 2) / 3"
}
}
}
Kiro's Generation:
def compute_vector_scores(mode, selections):
if mode == "normal":
return sum(s.weight for s in selections) / len(rounds)
else: # deep
surface = sum(s.weight for s in surface_selections)
shadow = sum(s.weight for s in shadow_selections)
return (surface * 1 + shadow * 2) / 3
Result: 180-line scoring.py generated in one shot, production-ready.
MCP Servers: Development & Testing Infrastructure
What We Built:
We created 3 MCP servers with 11 tools to evaluate Kiro's Model Context Protocol capabilities during development:
1. QRNG MCP Server (backend/mcp_servers/qrng_server.py)
get_quantum_random- Fetch single quantum value (0-255)get_quantum_batch- Fetch batch of values (up to 100)get_cache_status- Monitor cache state (size, threshold, refill)
2. Gemini MCP Server (backend/mcp_servers/gemini_server.py)
generate_persona_snapshot- Create 8-12 sentence personality readinggenerate_deeper_reading- Generate 2-3 paragraph analysisgenerate_omen- Create quantum-seeded fortuneclassify_user_input- 4-class safety classification
3. ElevenLabs MCP Server (backend/mcp_servers/elevenlabs_server.py)
generate_tts- Convert text to speechget_voice_settings- Retrieve voice configurationlist_available_voices- Browse voice libraryestimate_duration- Calculate audio length
Development Workflow:
# Test QRNG server in Kiro IDE
> get_quantum_random(count=5)
[79, 79, 158, 250, 144] # Real quantum values!
> get_cache_status()
{"cache_size": 95, "threshold": 10, "last_refill": "2025-12-05T10:23:15Z"}
# Test Gemini server
> classify_user_input(user_text="Will I get this job?")
{"classification": "relevant", "confidence": 0.95}
> generate_omen(shadow_profile={...}, tone="dark", quantum_seed=79)
"The fog hides what you crave. Your possessiveness smudges the glass..."
MCP Development Mastery:
We built complete MCP servers to master Kiro's Model Context Protocol and accelerate our development workflow.
What We Achieved:
- ✅ Full MCP mastery - 3 servers, 11 tools, complete error handling
- ✅ Development acceleration - Rapid testing and iteration in Kiro IDE
- ✅ Architecture exploration - Deep understanding of MCP's tool orchestration power
- ✅ Future-ready foundation - MCP infrastructure ready for scaling
The MCP Advantage:
MCP proved invaluable for:
- Rapid prototyping - Test quantum algorithms instantly
- AI experimentation - Iterate on prompts with live feedback
- Development workflow - Seamless tool integration in Kiro IDE
- Scalability preparation - Foundation for complex multi-tool orchestration
Key Insight: MCP shines for development workflows and complex tool chains. We used it exactly where it adds most value—accelerating our development process and preparing for future expansion.
MCP Configuration:
{
"mcpServers": {
"yoru-majo-qrng": {
"command": "python",
"args": ["-m", "backend.mcp_servers.qrng_server"],
"env": {"PYTHONPATH": "."}
},
"yoru-majo-gemini": {
"command": "python",
"args": ["-m", "backend.mcp_servers.gemini_server"],
"env": {
"PYTHONPATH": ".",
"GEMINI_API_KEY": "${GEMINI_API_KEY}"
}
},
"yoru-majo-elevenlabs": {
"command": "python",
"args": ["-m", "backend.mcp_servers.elevenlabs_server"],
"env": {
"PYTHONPATH": ".",
"ELEVENLABS_API_KEY": "${ELEVENLABS_API_KEY}"
}
}
}
}
Steering Docs: Teaching Kiro Our Voice
The Challenge: Maintain 3 distinct personas across dozens of sessions.
The Solution: 450-line steering document with concrete examples.
Example: Witch Voice
### 4.1 The Witch (Yoru Majo) – Audio Persona
BAD: "You project an air of deep-seated purpose"
GOOD: "You move with purpose. Something drives you forward."
BAD: "Others perceive you as discerning and measured"
GOOD: "People see someone who watches, who never quite relaxes"
Impact: Kiro generated perfect witch responses without breaking character.
Vibe Coding: Real-Time Polish
Use Cases:
- UI/UX refinement (20+ micro-adjustments per session)
- Animation tuning (witch hand movement took 10 iterations)
- Bug fixes (green flash before witch appears - fixed in 2 minutes)
Example Conversation:
Me: "The witch's hand animation is too fast"
Kiro: [Adjusts keyframes from 6s to 10s]
Me: "Make it random, not repetitive"
Kiro: [Generates 8 keyframes with irregular timing]
Me: "Too much movement, make it whisper-soft"
Kiro: [Reduces from ±6px to ±1px]
Result: Organic, subtle animation achieved through iterative conversation.
Agent Hooks: Architectural Documentation
Purpose: Define service boundaries and contracts.
Example: analysis_hook.json
{
"inputs": {
"mode": "normal | deep",
"selections": "array of round data",
"factor_scores": "F1-F8 numeric scores"
},
"outputs": {
"persona_snapshot_text": "8-12 sentences, 120-150 words",
"reading_paragraphs": "2-3 paragraphs, 200-250 words",
"ritual_hint": "1-2 sentences"
}
}
Impact: Kiro could reference hooks across sessions for consistent architecture.
📊 Results: By The Numbers
Code Generated by Kiro
- Backend: ~2,500 lines (Python)
- Frontend: ~4,000 lines (TypeScript + React)
- MCP Servers: ~800 lines (3 servers, 11 tools)
- Specs + Steering: ~1,500 lines (JSON + Markdown)
- Total: ~8,800 lines
Development Velocity
- Week 1: Specs + steering setup
- Week 2: Core logic (80% generated by Kiro)
- Week 3: UI/UX polish (vibe coding, 100+ iterations)
- Week 4: MCP servers + testing + deployment
MCP Infrastructure
- 3 servers, 11 tools: Complete MCP mastery for development acceleration
- Development workflow: Rapid prototyping, AI experimentation, tool orchestration
- Future-ready: Architecture prepared for scaling and complex integrations
- Test coverage: All tools tested and working in Kiro IDE
Asset Creation
- 48 Szondi cards: AI-regenerated from 1940s originals
- Voice experiments: Dozens of ElevenLabs tests
- Custom backgrounds: Neon Tokyo bathroom, witch silhouettes
- Static voice files: Pre-generated from ElevenLabs API
Prompt Engineering
- Persona snapshot: 10+ iterations
- Deeper reading: 8+ iterations
- Final omen: 15+ iterations
- Guardrails: 5+ iterations per class
Built With
- anu
- artificial-intelligence
- css3
- docker
- elevenlabs
- fastapi
- firebase
- gemini
- git
- google-cloud
- howler.js
- html5
- javascript
- kiro
- machine-learning
- npm
- python
- qrng
- quantum-computing
- react
- rest-api
- typescript
- uvicorn
- vite
- web-audio
- zustand

Log in or sign up for Devpost to join the conversation.