-
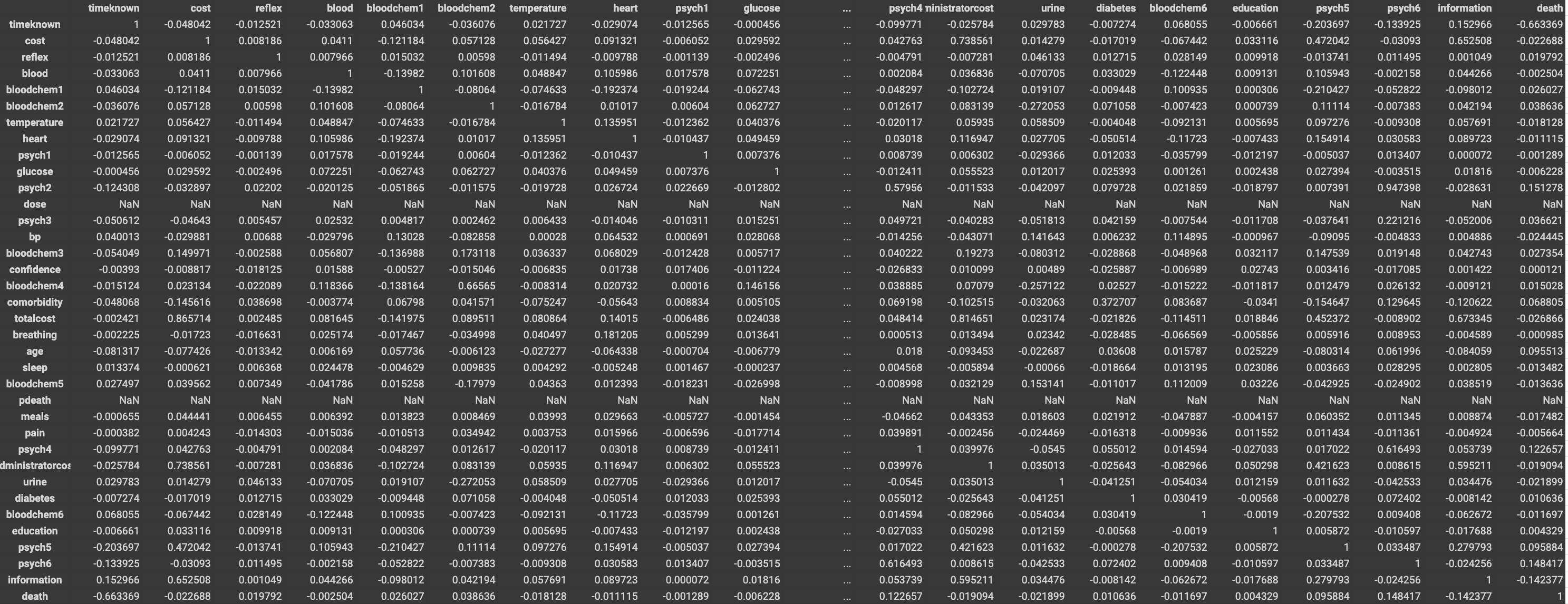
Correlation Matrix
-
Plot between variables
Inspiration
Healthcare is a broad field that impacts the lives of billions of people worldwide. This results in an enormous volume of data that has the potential to significantly improve patient care and survival rates through effective analysis. By analyzing the data to determine the most significant correlations between certain categories and patient outcomes, healthcare providers can more effectively care for their patients.
With this context, our project is a machine learning model that aims to alleviate the data crunching process and streamline the process of data integration within this industry. The primary objective of this project is to enable medical professionals to make better-informed decisions to positively impact survival rates.
What it does
Our model is a random forest classifier that predicts the survival rate of patients based on provided hospital data. With the gathered patient data, the model takes specific categories into account that were determined to be the most directly correlated with the overall patient outcome (whether they survived or not). Thus, it parses through the data and automatically removes categories that do not play as impactful of a role on the survival of patients. The categories that most directly correlate with the survival or death of the patient are then used as the highest impact categories for our model.
Overall, our model is able to determine the final patient outcome based on the categories determined to be highest impact with over 90% accuracy.
How we built it
We began by analyzing the data in order to figure out which features were most important and would improve the classification model. We extracted the numerical variables and looked at the correlation matrix to see how strong/weak the relationship between the variables and death were. We selected the variables which were most correlated with death and built a simple logistic regression model to evaluate our choices. We split the data into train and test sets, with 33% in the test set and the rest for training. We also evaluated categorical variables and how they affected the models. We decided to encode some relevant categorical data. We also assessed interactions between variables to see if they could improve the model. The accuracy for these ranged between 80 to 85%. Once we selected the numerical, categorical, and interaction variables that we were going to use, we evaluated different models such as the Logistic Regression model for which we got an accuracy of about 87%, Random Forest Classifier, and the SVM model, both with accuracies around 90.8%. We attained the highest test set accuracy for the Random Forest model, so we decided to use that model for our final submission.
Challenges we ran into
Some challenges we faced were deciding which variables were best to use. We checked using the correlations between variables and then we also tried to figure out whether multiple conditions interacted with each other and had a more direct relationship with the survival rates. For example, diabetes may not correlate with the death column, and glucose may also not correlate very heavily with the death column, but glucose and diabetes together may show a much greater correlation with the data in death. However, finding these interactions was an incredible time-consuming process, so it was difficult to determine the most effective variables to use.
We struggled with submission as well considering attorney was down for the better portion of the morning, and we were unfortunately unable to submit it through there to see how well our code really worked against the test cases provided by the datathon.
Accomplishments that we're proud of
As all of us are beginners in data science, we learned a lot about classification models. On top of this, two out of the three members on our team are more hardware oriented, so for us, programming is less inherent. It seemed daunting because of these two major issues, but eventually, we were able to get our model to have over 90% accuracy, and it is something that we are very proud of ourselves for.
Additionally, we think this issue is something that healthcare professionals and patients are heavily affected by worldwide. Any solution aimed towards alleviating this largely impactful, real-life issue is something to be proud of.
What we learned
We learned a lot about data science, in general. We learned how to more effectively find correlations between variables. Additionally, we learned about different models as we started with a logistic regression model and then figured out that the random forest classifier and SVM model was more effective. We also learned about interaction terms and how those can affect correlations between multiple variables.
What's next for Hospital_challenge
We want to get our model to over 95% accuracy. Additionally, we hope to use more data to test our model and improve the categories we are using; finding the correlation of interaction terms was a difficult task due to time, so we want to incorporate more of that as well.

Log in or sign up for Devpost to join the conversation.