-
Flow
Inspiration
Many people have strong ideas for websites but struggle to express them using traditional design tools like Figma or Adobe XD. These platforms assume a level of familiarity with design systems, components, and interfaces that can be intimidating for beginners or non-designers. We were inspired by the gap between having an idea and being able to execute it visually. Instead of forcing users to learn complex tools, we wanted to meet them where they are most comfortable: speaking and sketching. The goal was to create a system that allows anyone to naturally communicate their vision and have it translated into a functional website without needing prior design experience.
What it does
HonkTuahGoose is a real-time AI web developer that users can talk to over a phone call while sketching their ideas on a whiteboard. As the user draws and explains their thoughts, the system interprets the visual input and conversation simultaneously, building an understanding of the intended layout and functionality. It responds dynamically by asking clarifying questions, confirming assumptions, and guiding the user through the design process. While the interaction is happening, the agent is also generating the underlying website code, effectively turning rough sketches and spoken ideas into a structured, working frontend.
How we built it
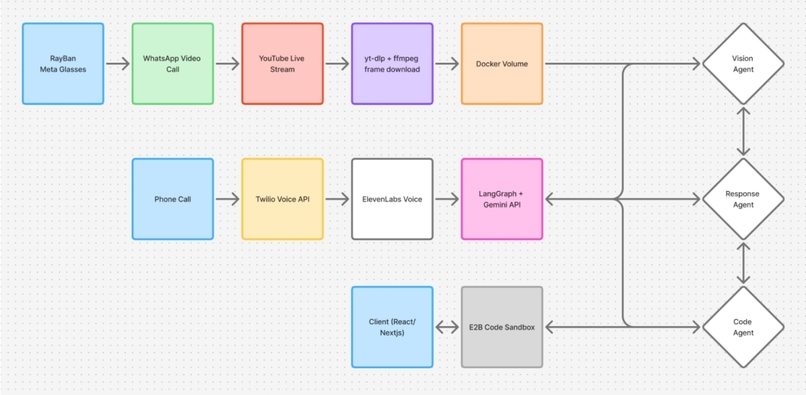
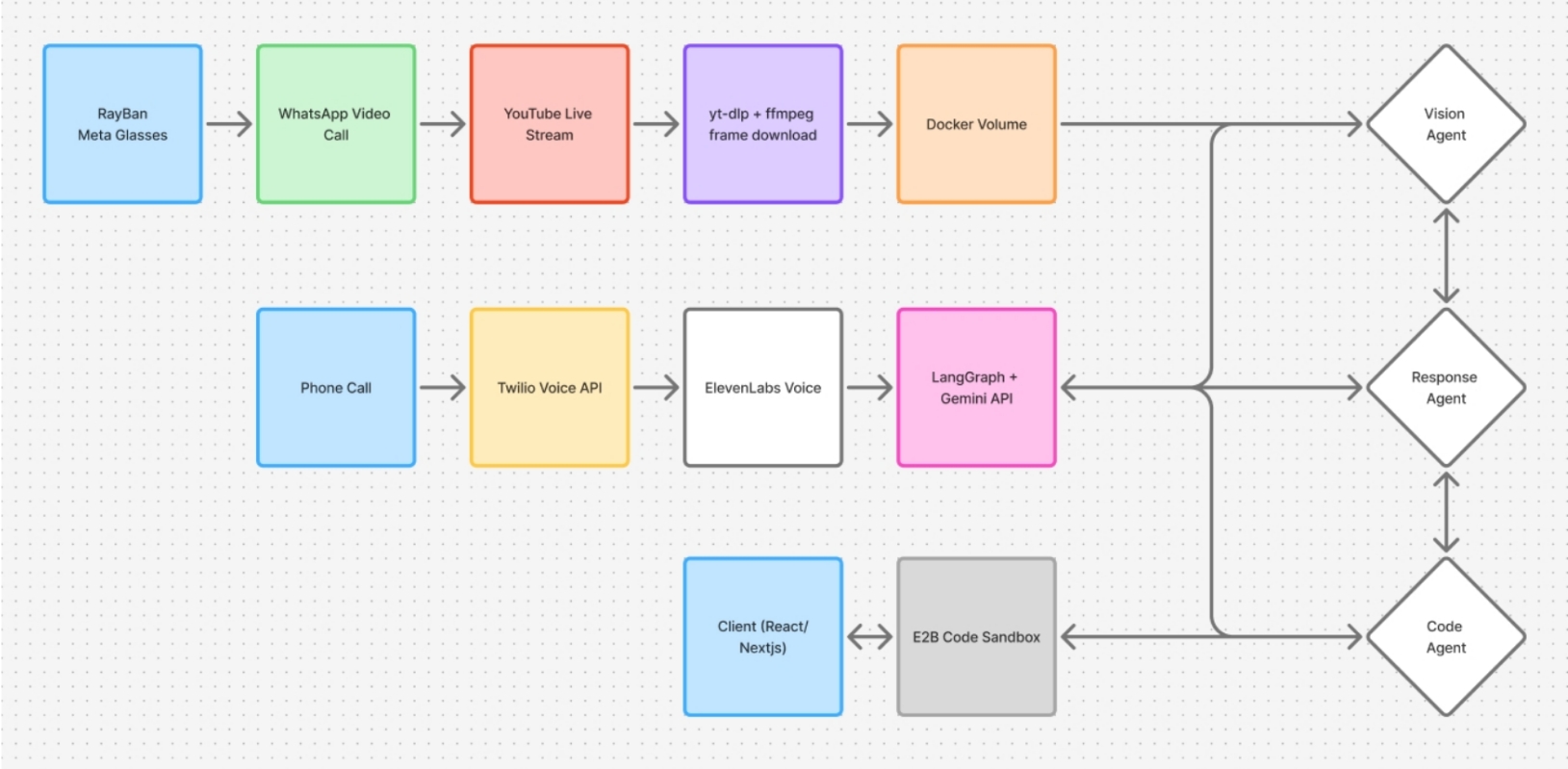
We built HonkTuahGoose as a multimodal system that connects voice, video, and code generation into a coordinated pipeline. The visual flow begins with Ray-Ban Meta Smart Glasses capturing the user’s perspective, which is streamed through a WhatsApp video call and broadcast to YouTube Live. An observer service then pulls frames from the stream using tools like yt-dlp and FFmpeg, storing them in a shared Docker volume for downstream processing. These frames are consumed by a vision agent powered by Google Gemini, which extracts layout structure, UI components, and inferred intent in near real time.
In parallel, the user interacts with the system through a phone call that serves as the primary control channel. The call is handled via Twilio, while ElevenLabs generates low-latency speech responses from the agent. The conversational layer is orchestrated using LangGraph combined with Gemini, allowing the system to maintain a structured, continuously updated representation of the design that merges both visual observations and spoken input. A response agent manages dialogue and clarification, while a separate vision agent feeds new interpretations into the shared state.
Once sufficient context is accumulated, a code agent translates the evolving design state into frontend code, generating components incrementally rather than waiting for a full specification. The code is executed and validated inside an E2B environment, and rendered through a client built with React and Next.js. This architecture allows all subsystems to operate concurrently, so the agent can continue asking questions and refining intent while code is being generated, keeping the interaction responsive and tightly aligned with the user’s evolving design.
Challenges we ran into
One of the main challenges was balancing the time it takes to generate code with the need to keep the conversation active. The system cannot remain silent for too long, so we had to design a way for it to stay engaged while still making meaningful progress in the background. Another difficulty came from interpreting rough and often ambiguous sketches, which required the agent to ask the right questions without overwhelming the user. Maintaining a consistent understanding of the design as it evolved over time also proved complex, especially when new inputs contradicted earlier assumptions. Coordinating multiple real-time systems, including video processing, voice interaction, and code generation, added another layer of difficulty, as everything needed to remain synchronized without introducing noticeable lag.
Accomplishments that we're proud of
We are most proud of creating an experience that feels natural and conversational rather than technical. The system successfully turns informal inputs like sketches and spoken descriptions into structured code, which represents a significant step toward making web development more accessible. We also built a solution that transforms a technical limitation, such as the need for continuous voice input, into an opportunity for deeper engagement through intelligent questioning and feedback. The result is an agent that behaves more like a collaborative partner than a passive tool.
What we learned
Through building HonkTuahGoose, we learned that the biggest challenge in design is not generating code but understanding intent. Users often refine their ideas as they express them, which makes continuous interaction essential for accurate results. We also found that multimodal systems are most effective when they actively involve the user rather than simply processing input in the background. Small interaction patterns, such as asking quick confirmation questions, can significantly improve both user experience and output quality. Ultimately, building real-time AI systems requires careful orchestration between components rather than relying solely on model performance.
What's next for HonkTuahGoose
Looking ahead, we want to make the system feel even more immediate and interactive by introducing live previews that update as the user speaks and draws. We are also interested in expanding beyond frontend generation to support full-stack development, including backend logic and data integration. Another direction is enabling collaborative sessions where multiple users can contribute to the same design in real time. We also see strong potential in accessibility applications, particularly for users who cannot easily interact with traditional design tools. Our long-term goal is to turn HonkTuahGoose into a complete platform where anyone can go from idea to deployed product using only natural communication.

Log in or sign up for Devpost to join the conversation.