-
-
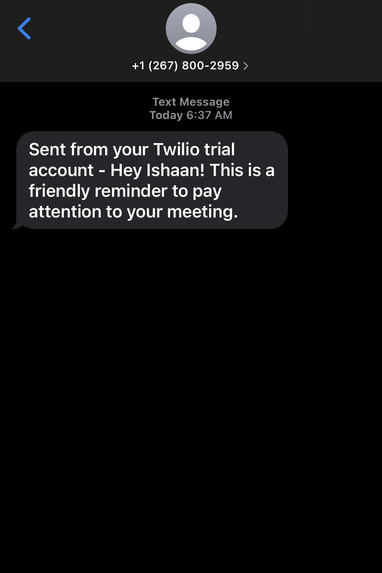
Sample text message sent to student when they are distracted from their class.
-

Customize contact information for notifications, as well as keyword selection (examples include important deadlines, projects, or exams)

Inspiration
In a survey conducted by Barnes & Nobles education, over 64% of college students expressed concern over maintaining focus and discipline while taking remote university courses. We also discussed this issue with many of our friends and peers, and noticed that a lot of students like us struggle with staying focused in their virtual classes and paying attention to important topics and content. To solve this modern-day challenge, we decided to build a desktop app that reminds students to pay attention in their classes; both when they are looking away from their screen and when their professor mentions important content (keywords) that they should be observing closely.
What it does
Honk enables college students to take charge of their education as adults by analyzing their real-time video camera and gaze direction to determine when they are distracted from their meetings. It then sends them periodic reminders that they should focus on their lecture or meeting if they repeatedly stay distracted. In addition, Honk listens to the meeting audio for the student's class and notifies them immediately if the meeting host mentions any important topics to study for, critical deadlines, or upcoming exams. The student can also customize the specific words or phrases that they would like to be notified of.
How we built it
We built the front-end of our desktop application in Electron and React. We decided to prioritize a minimalistic UI and styled our components using Chakra-UI, both due to the time constraints of the hackathon as well as the convenience aspects for the students. Students are able to start the video and audio streams and prepare to be notified of important occurrences in just two clicks, and the settings page allows them to customize their name, phone number to be notified at, and keywords that they would like our application to watch for.
Then, we needed to apply computer vision techniques in order to detect the gaze of the user and determine whether or not they were focused on their class. In order to pass the real-time video data from the front-end to our Flask back-end server, we used SocketIO. We sent the video data by capturing individual frames, or images, at a certain rate and sending those images live to our back-end. For the purposes of our demonstration, we decided to use 5 frames per second to feed to our computer vision model. We were able to send the images as base64 encoded strings, and we decoded them on the Python side so we could process them in our computer vision model. In the future, we plan to work on a way to scale and optimize our model's predictions such that they will have less latency and work more efficiently even at higher FPS rates.
Next, we used OpenCV with Python as well as a gaze detection library in order to determine where the user's gaze was pointed. We developed an algorithm to determine at what point we should let the user know that they are distracted and should pay attention to their meeting. We also had to take into account cases in which we had just notified the user, since we needed a cool off time to ensure that we weren't spamming the user's phone with excessive messages.
Finally, we utilized the SMS API from Twilio along with its helper library in Python in order to send text messages to the students who provided their phone numbers in settings. Messages were sent out either once we determined the user was distracted from their meeting, or when we processed a specific keyword in the audio using the Google Cloud Speech-to-Text API.
Challenges we ran into
Since we had never used SocketIO previously, we found the real-time streaming of the video data to be quite challenging and time-consuming. In addition, working with the image encodings proved to be more challenging than we had thought.
Although we fully implemented the video feature, we weren't able to implement the audio-based feature within the time constraints. We did a lot of research on how we could pass the device's audio through SocketIO and send it in real-time through Google Cloud's Speech to Text API, in the end we wanted to prioritize that we had our minimum viable product (MVP) working with the video feature and that we had a presentable UI and timely machine learning predictions. Since we were working with computer vision, ensuring that our model was able to handle the frame rate and process the distraction predictions correctly also took quite a bit of time.
Accomplishments that we're proud of
We are so proud that we were able to pass the video data in real time and process it! We had never worked with a real-time webcam stream before, and combining that with computer vision to predict whether someone was paying attention to their meeting was definitely very exciting!! In addition, this was the first desktop application any of us had ever built, and we were super happy that we could present a finished product before the hackathon deadline.
We also believe in the potential of our idea, and think that college students across the world would benefit from these notifications. This idea and the small application we were able to build inspired us to continue working on this project and we plan to expand on it and add a more extensive feature suite in the future.
What we learned
We learned a lot about the work that goes into taking raw data and making it ready for computer vision models, as well as creating algorithms based on those predictions. We also learned about how the client and server can talk to each other in real time and send information back and forth in a more interactive and responsive way than we were used to.
We spent a lot of time looking at image vectors in different dimensions, and gained a more low level understanding of how images are processed and modified across types and even languages. We were able to utilize this new found knowledge to develop an algorithm that makes decisions based on the outputs of those image vectors, and send the appropriate notifications to users.
What's next for Honk, the Virtual Meeting Assistant
In the future, we plan to expand Honk by adding a slew of features. The first would be fully implementing the audio feature regarding notifying users if their professor mentions an important topic or keyword. We would create sample keyword groups that are commonly used by a lot of students, so that students could reuse sets of keywords for multiple meetings that may have been created by other students or even themselves.
In addition, we plan to extend our model to analyze the audio itself after a certain keyword. We could save, for example, the information that a professor relayed for 15 seconds after mentioning the keyword "exam", and send that to the student in an email after their meeting was over with any other pertinent keyword information. This would enable the student, if they weren't able to pay attention to their meeting in time, to get a TL;DR, or a rundown of the important messages they might have missed while zoned out.
We feel that these future feature sets as well as the existing could be leveraged in addition to some UI improvements in order to create a desktop application that could be widely used as a meeting assistant of sorts to Zoom meetings or other virtual lecture formats. It would serve as both a reminder and productivity tool for distracted students, as well as a pathway to providing concise and direct details to students regarding their classes and other vital meetings.







Log in or sign up for Devpost to join the conversation.