-
-

HonestLedger - The reconciliation agent that keeps itself honest
-
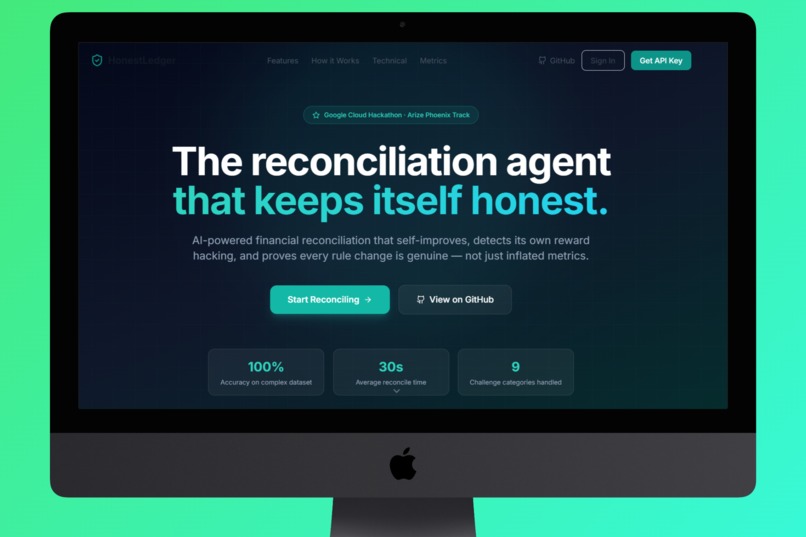
Homepag Hero Section
-
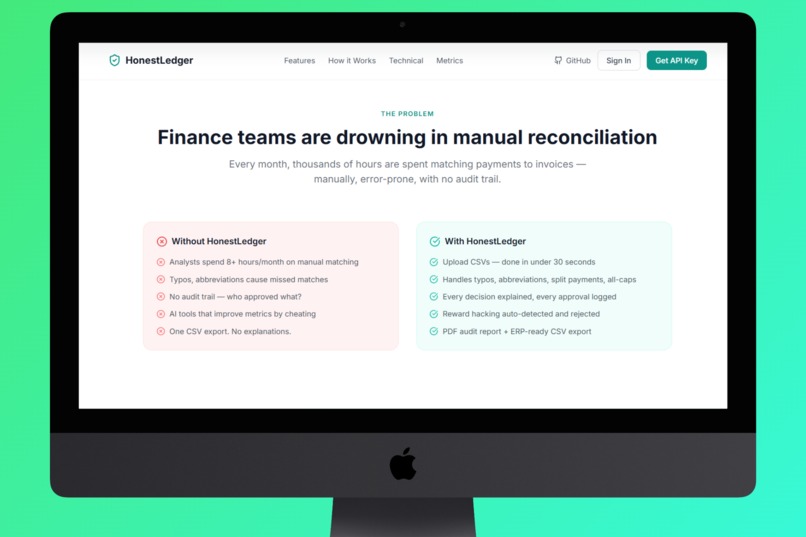
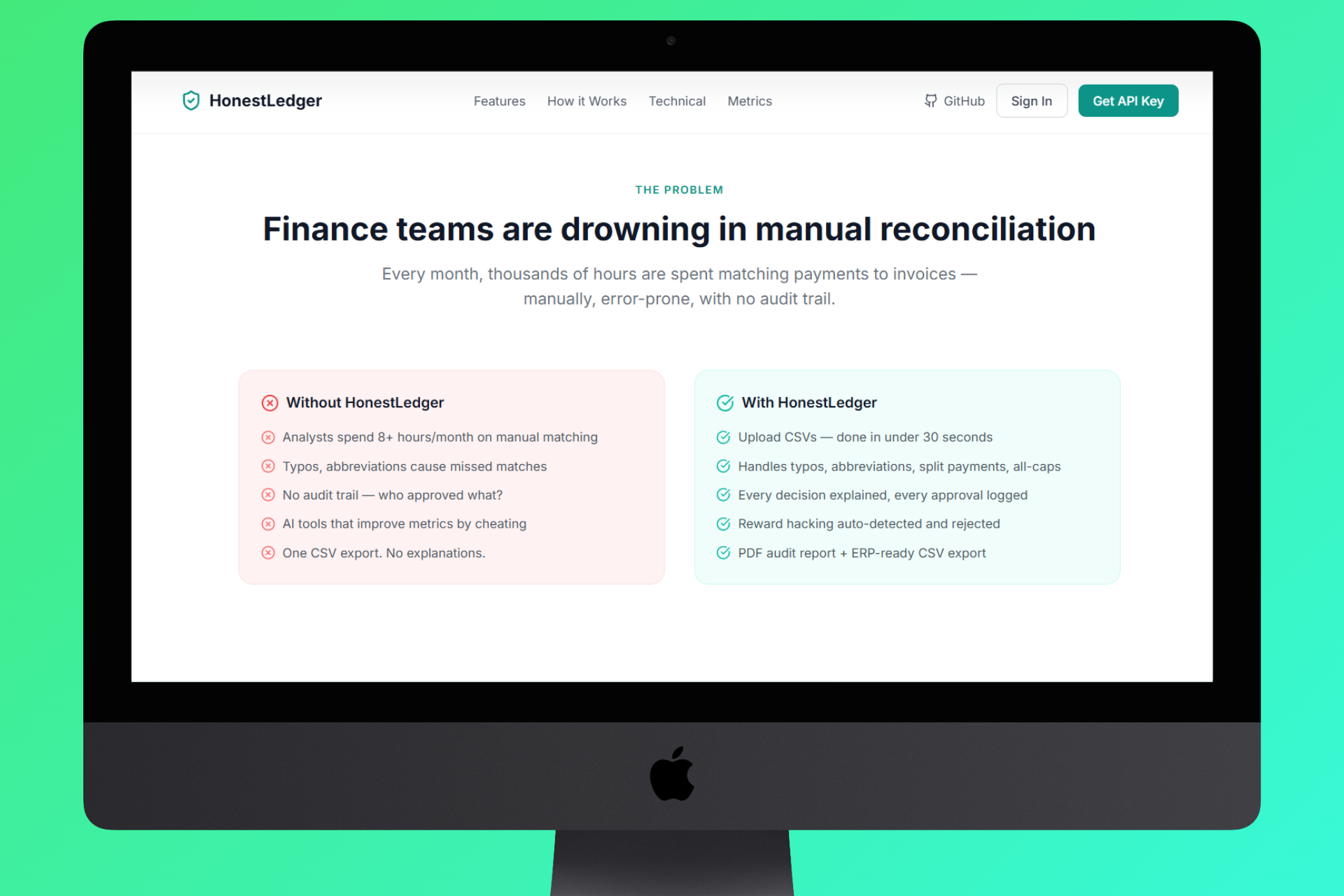
Homepag The Problem
-
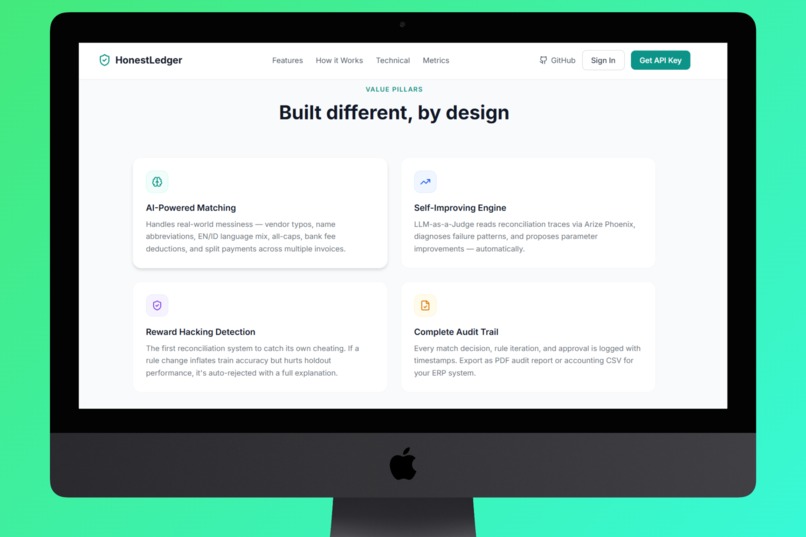
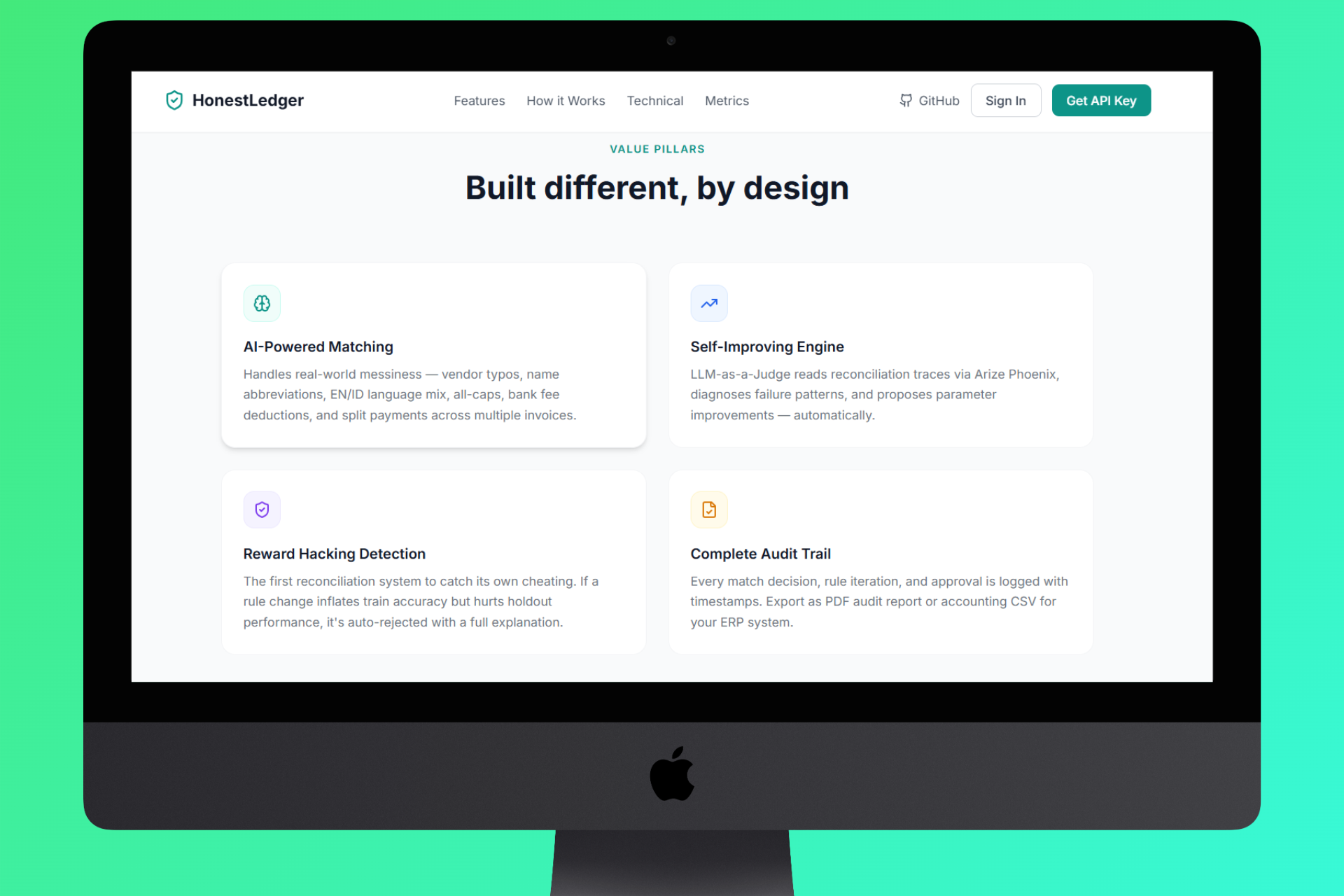
Homepage Value Pillars
-
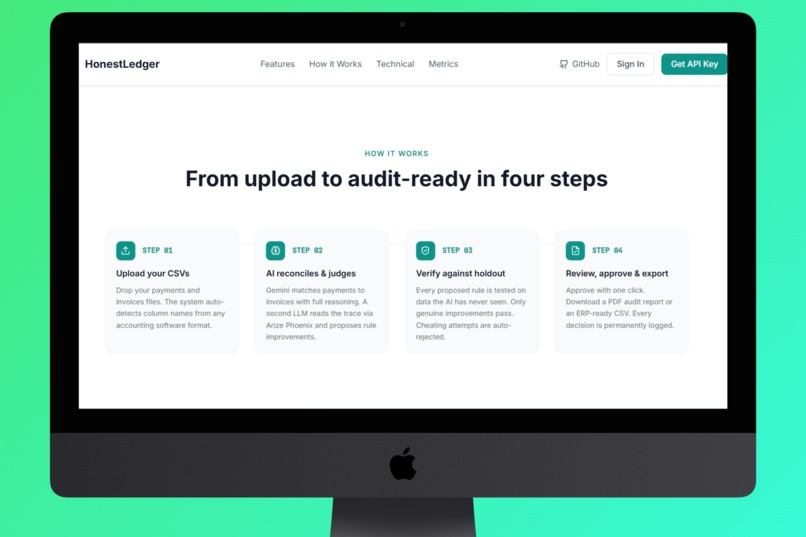
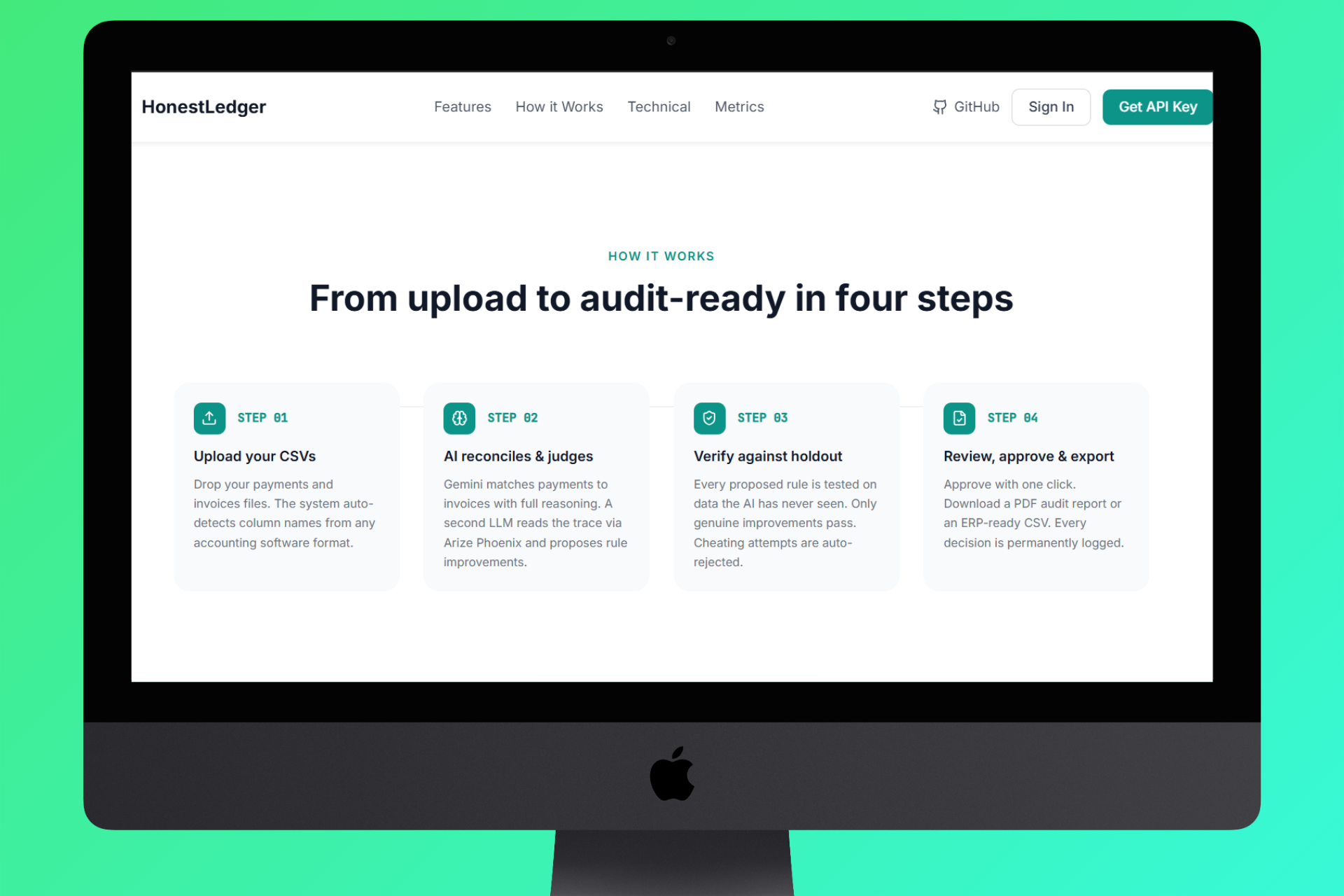
Homepage How It Work
-
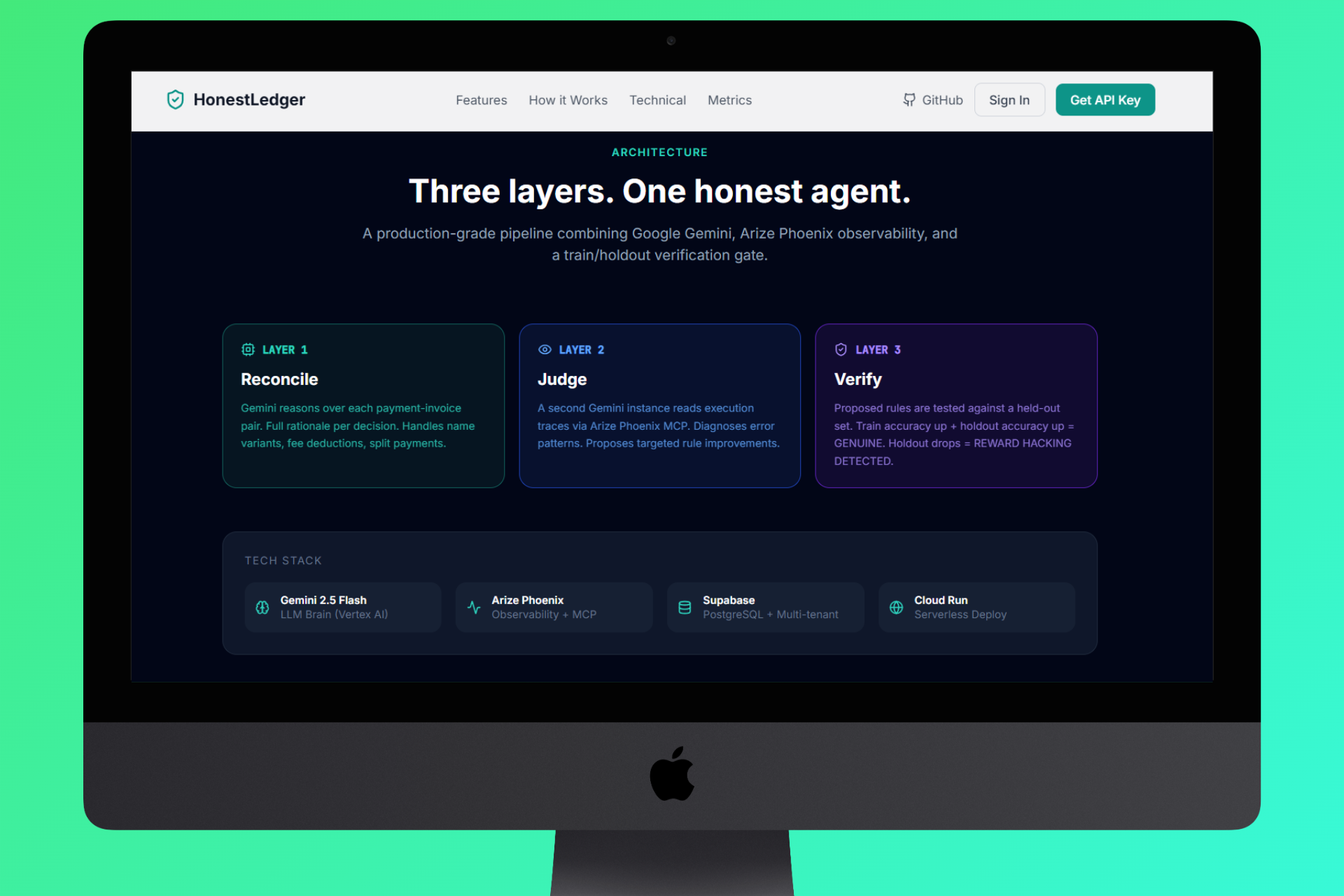
Homepage Architecture
-
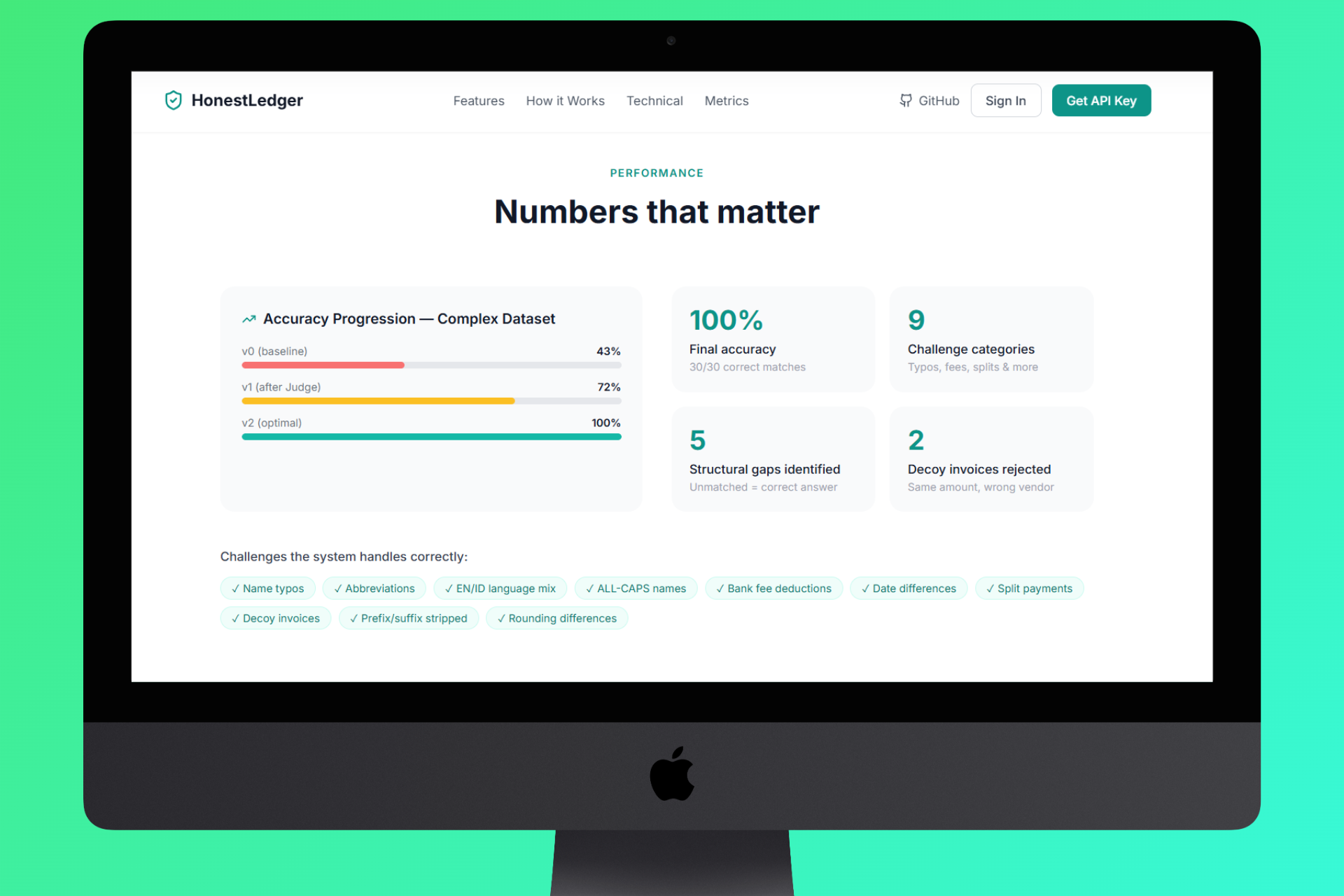
Homepage Performance
-
Homepage Footer
-
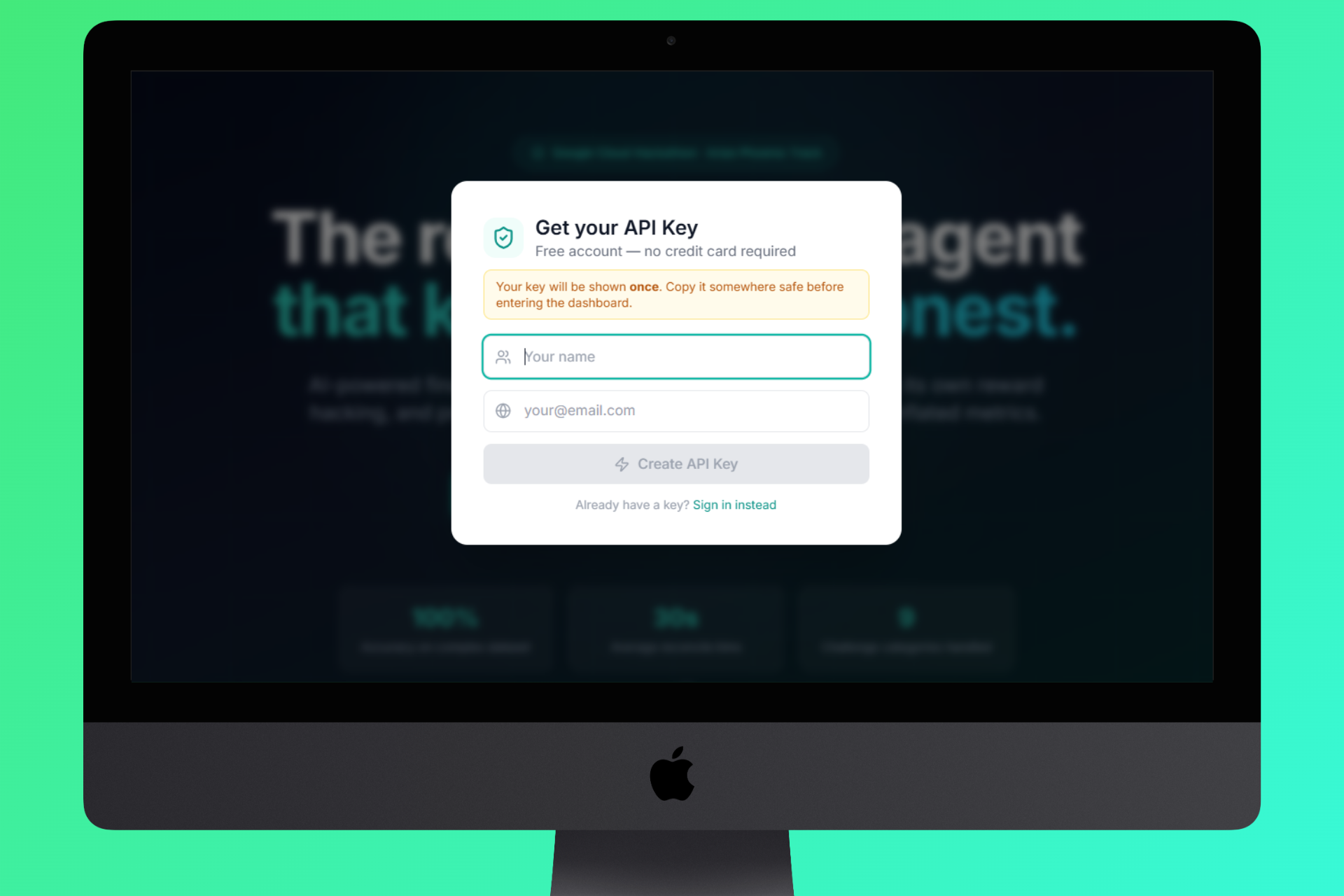
Signup For Get API Key
-
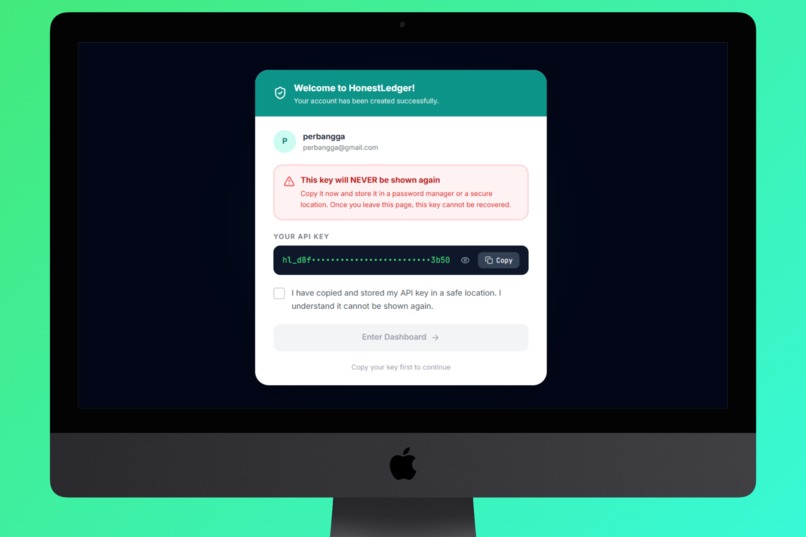
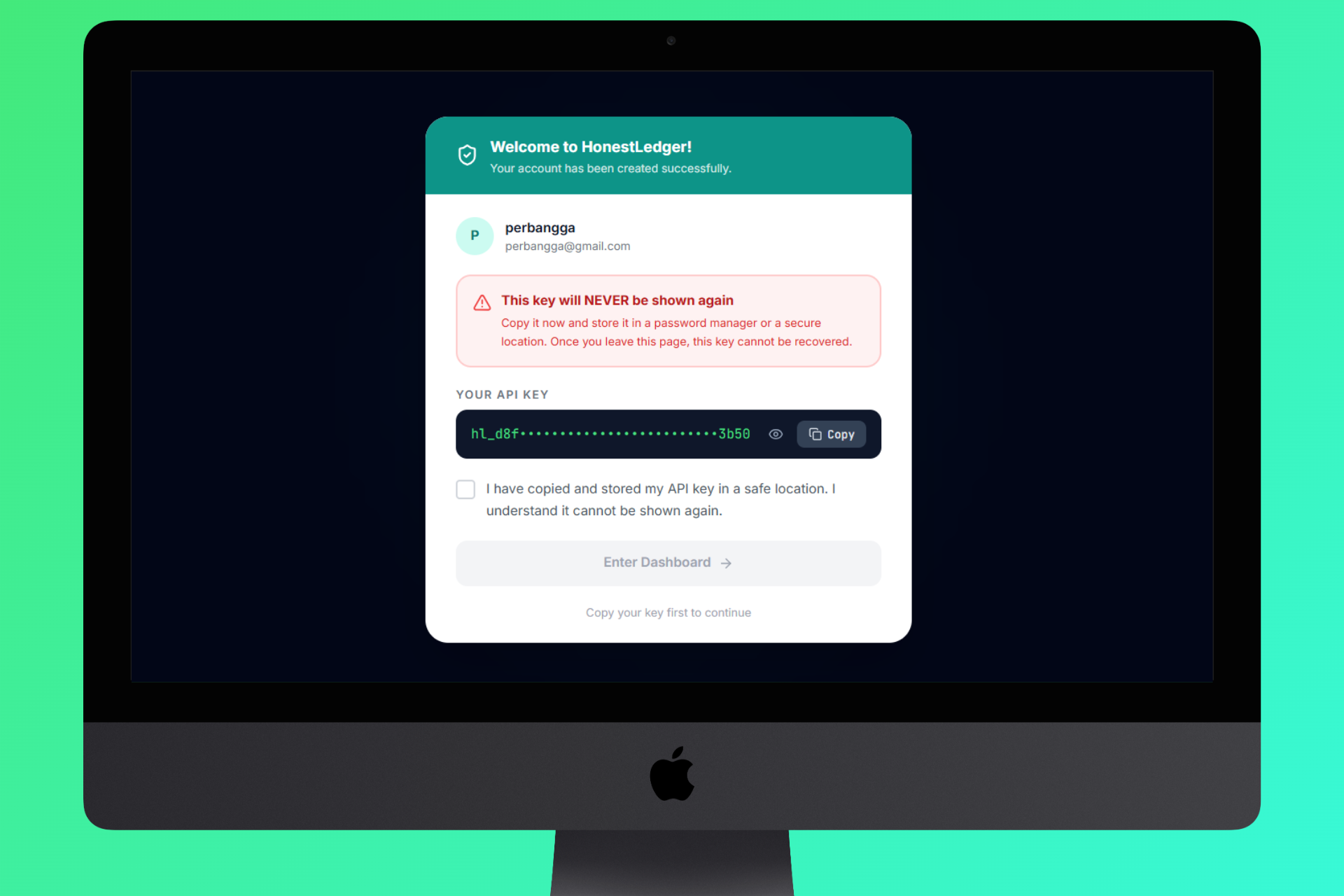
API Key Tenant for Access to Dashboard
-
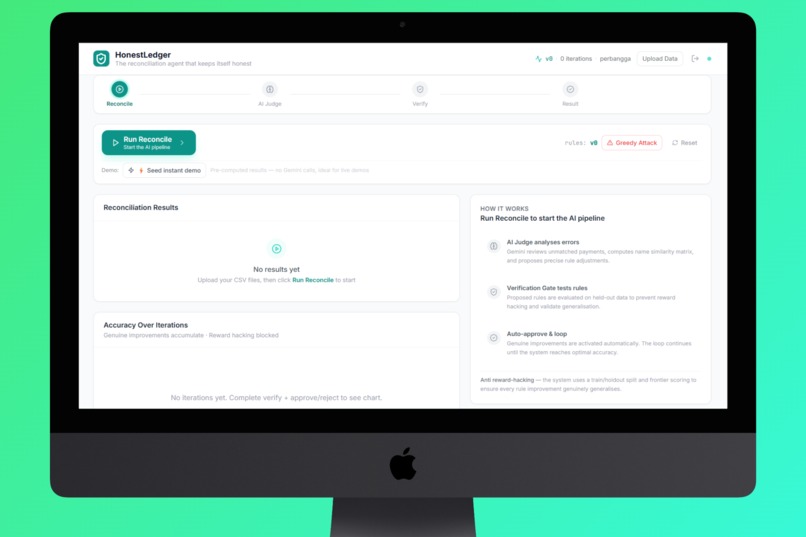
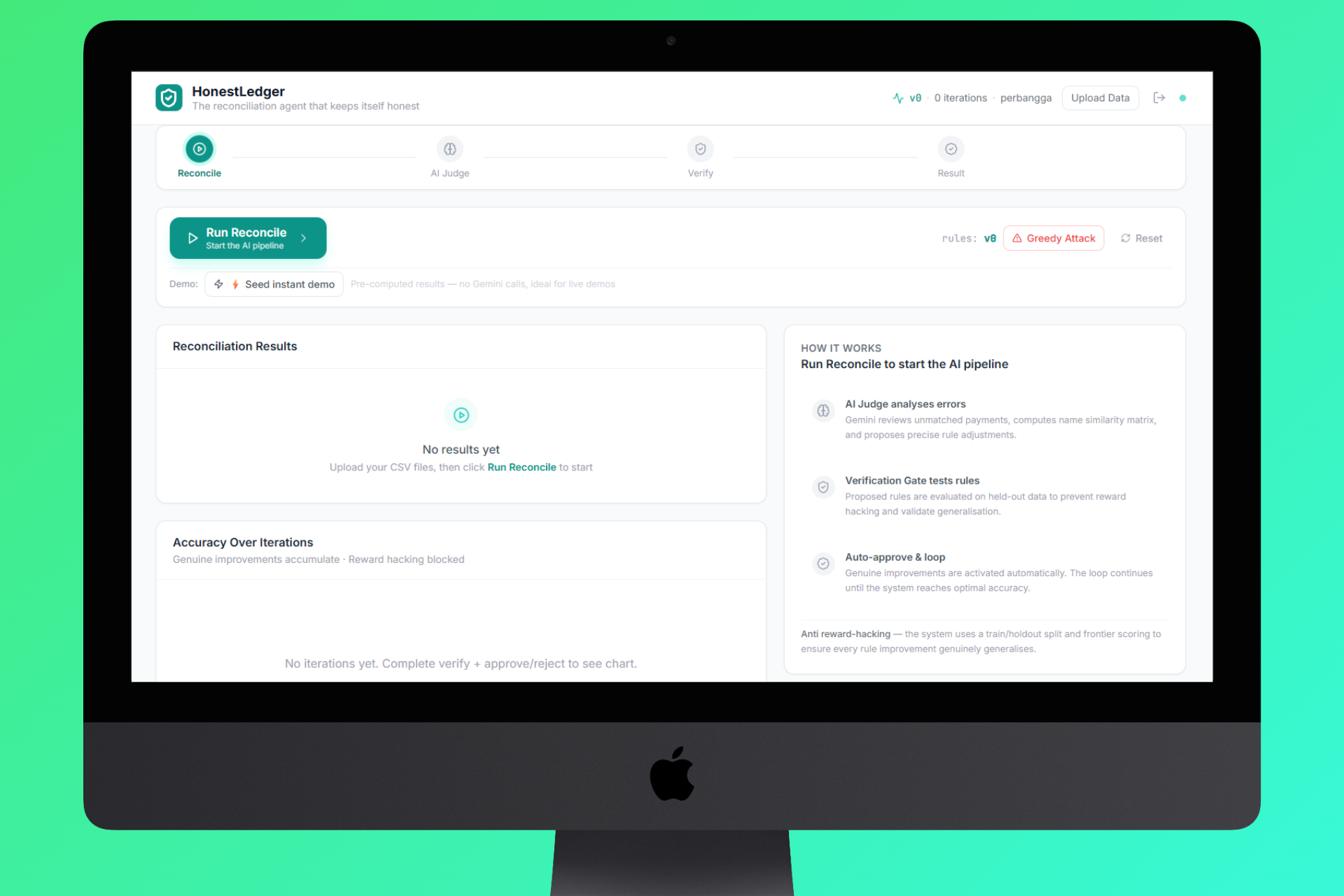
Dashboard HonestLedger Reconciliation for Tenant
-
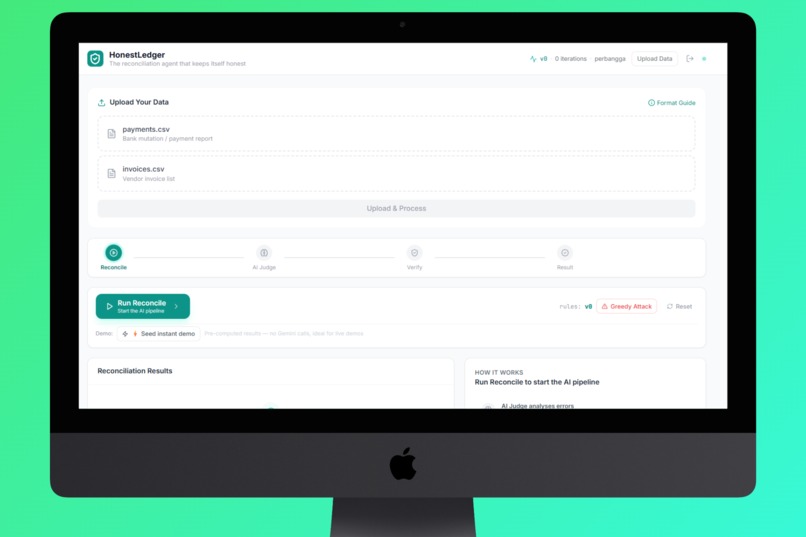
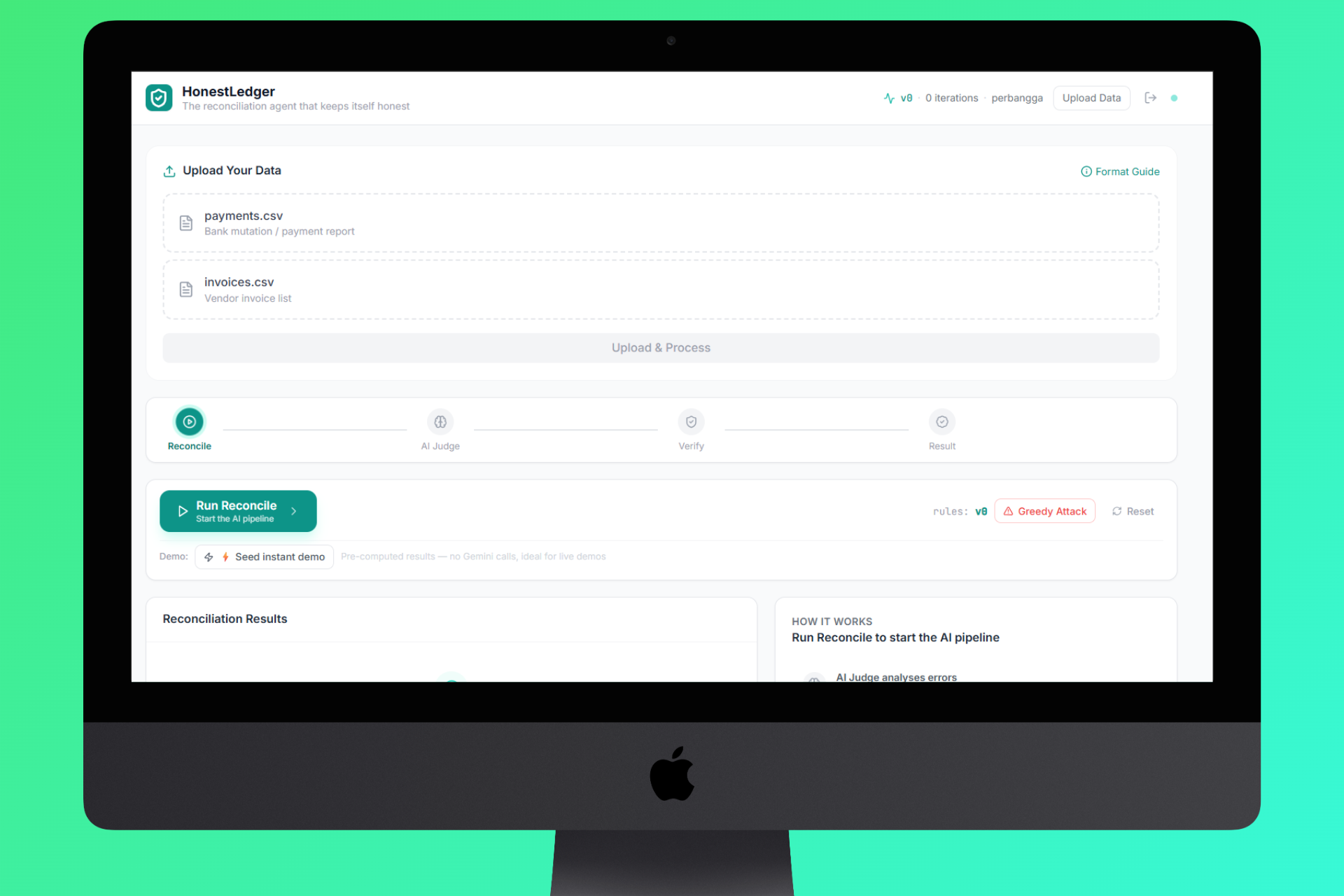
Upload Section Payment and Invoice
-
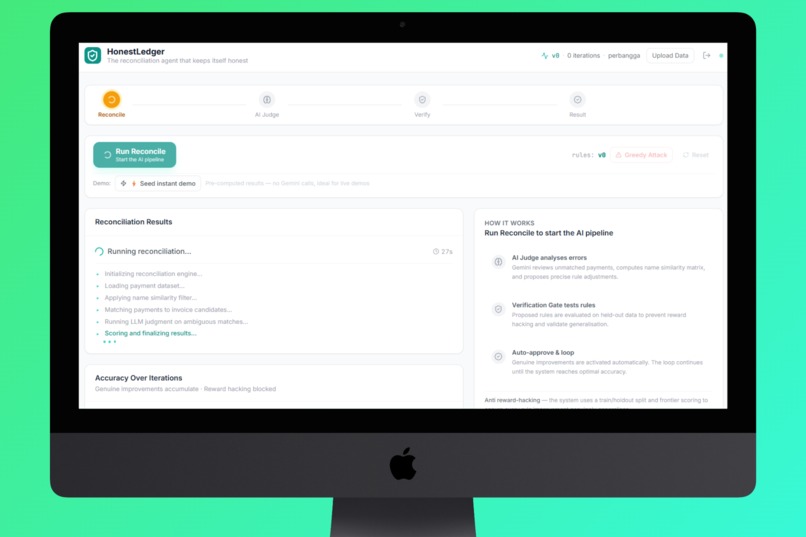
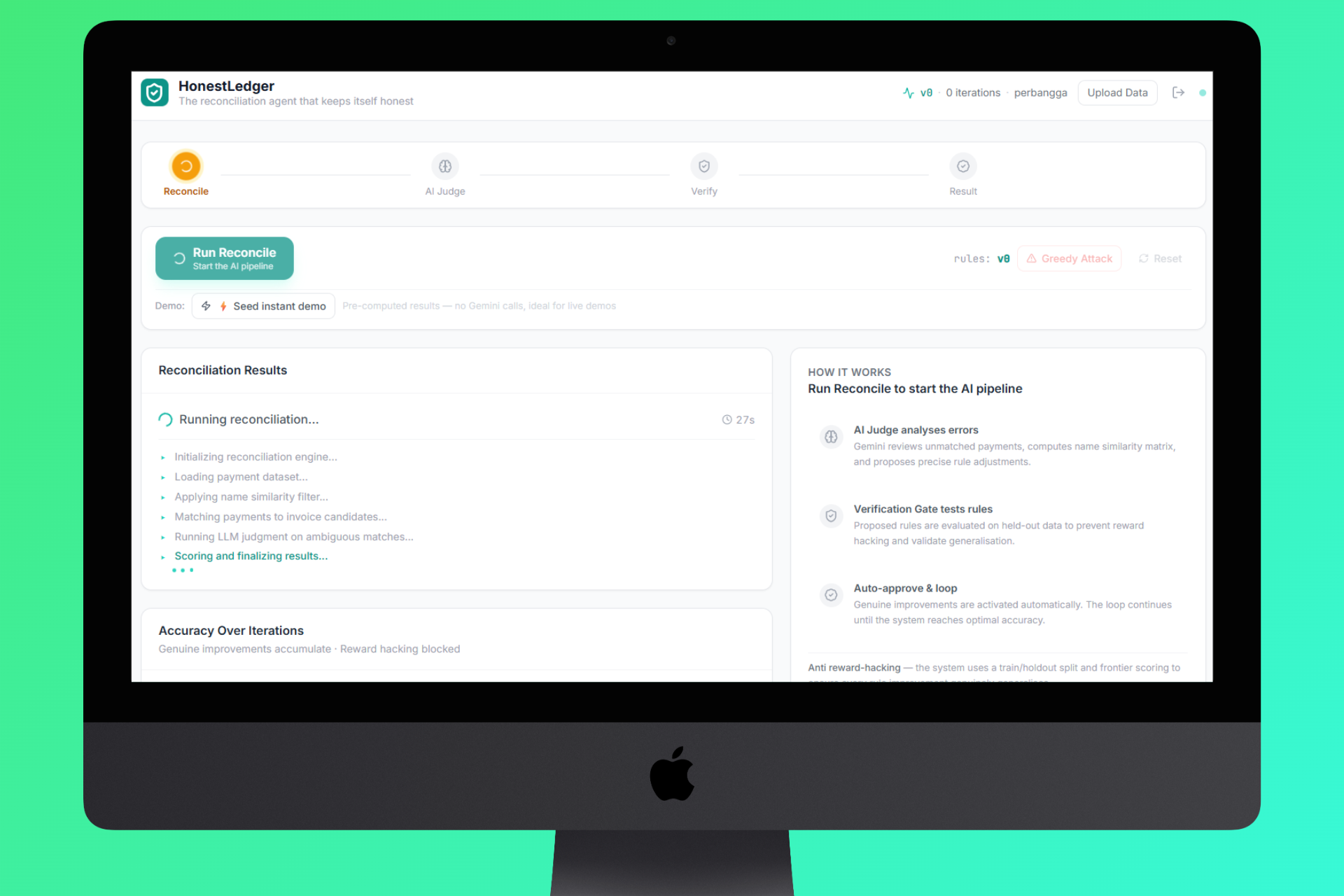
Reconciliation Runing
-
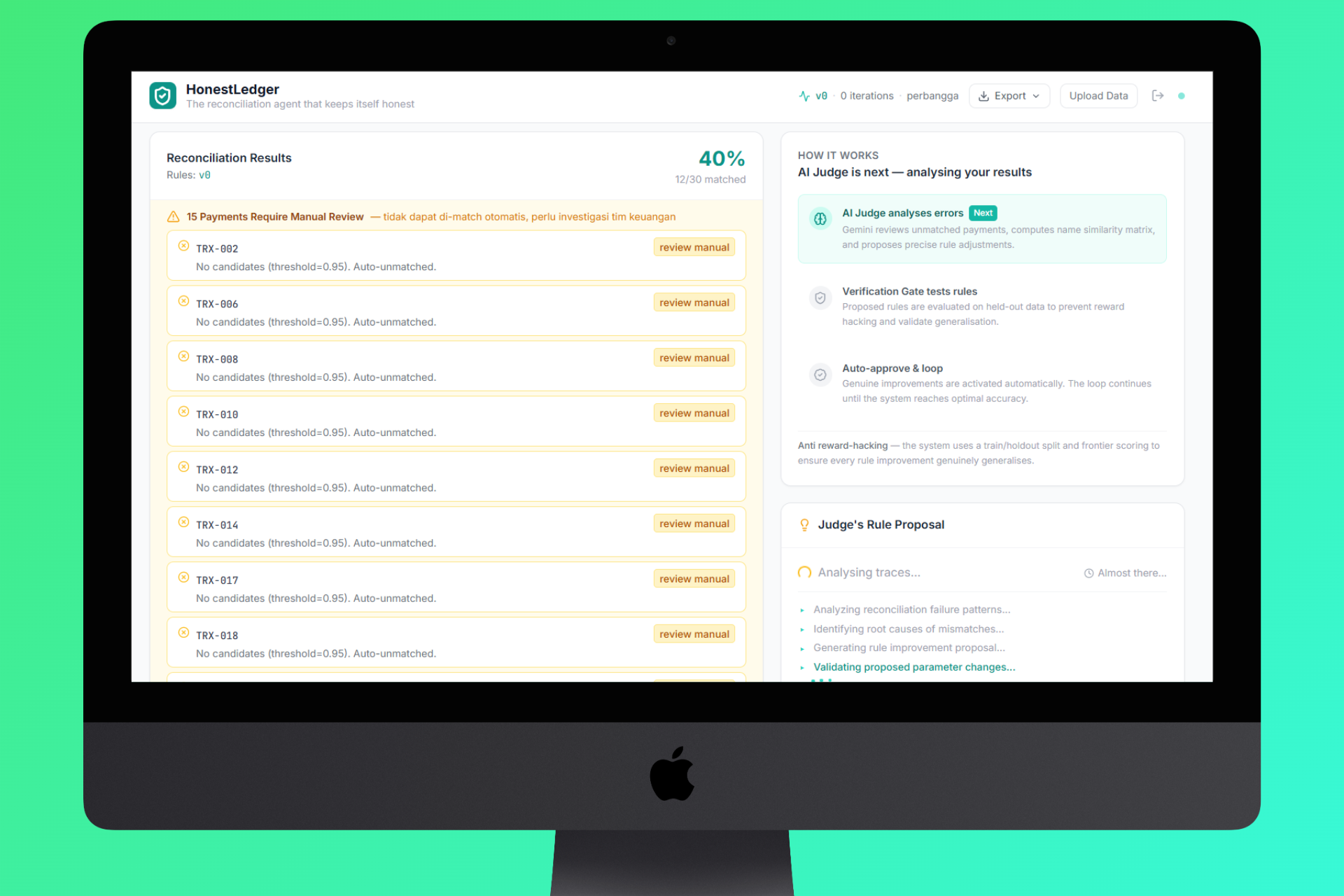
Reconciliation Result Wait Judge Proposal
-
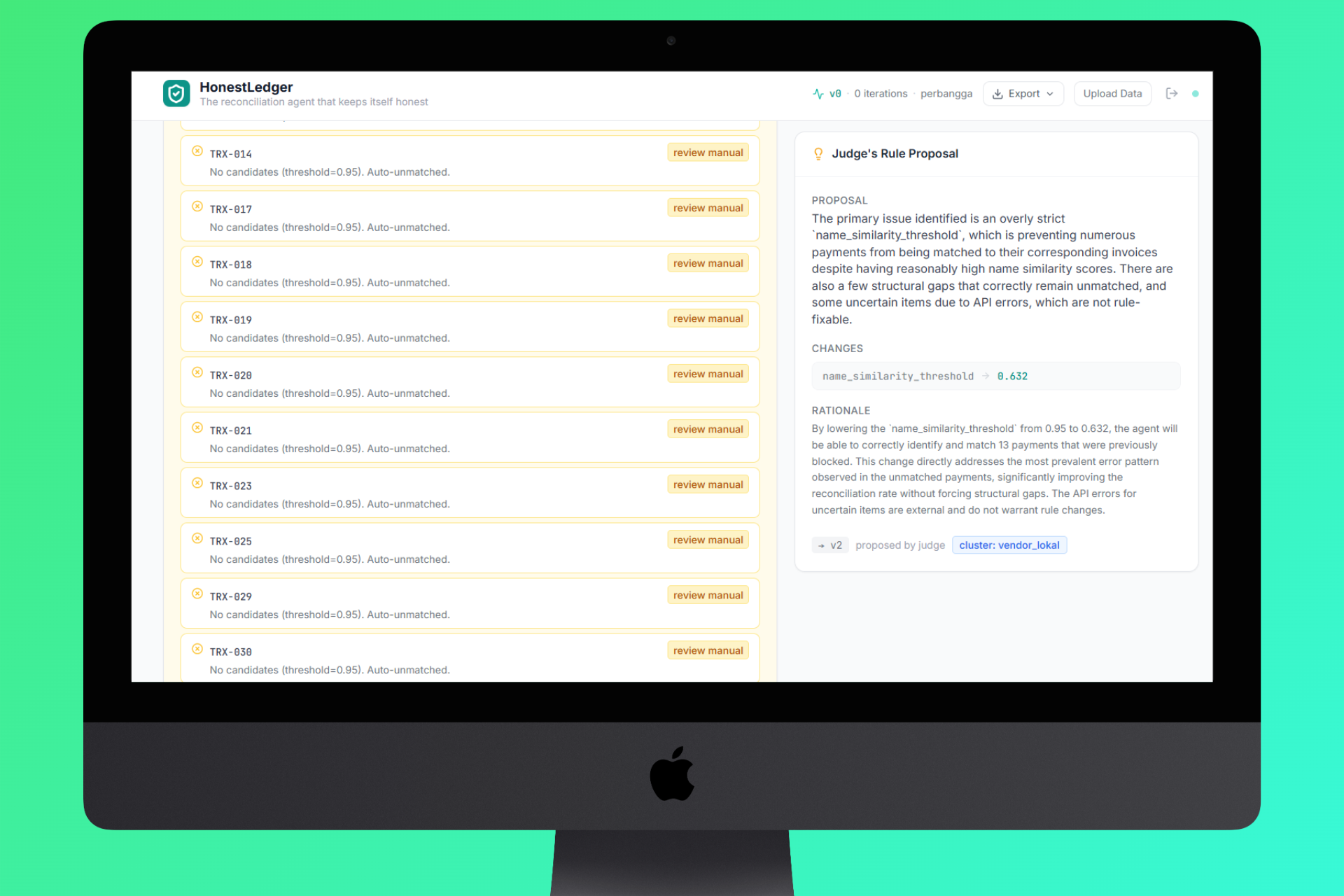
Jugde Result and Propse to v2
-
CSV Format guide
-
Reward Hacking Detection
-
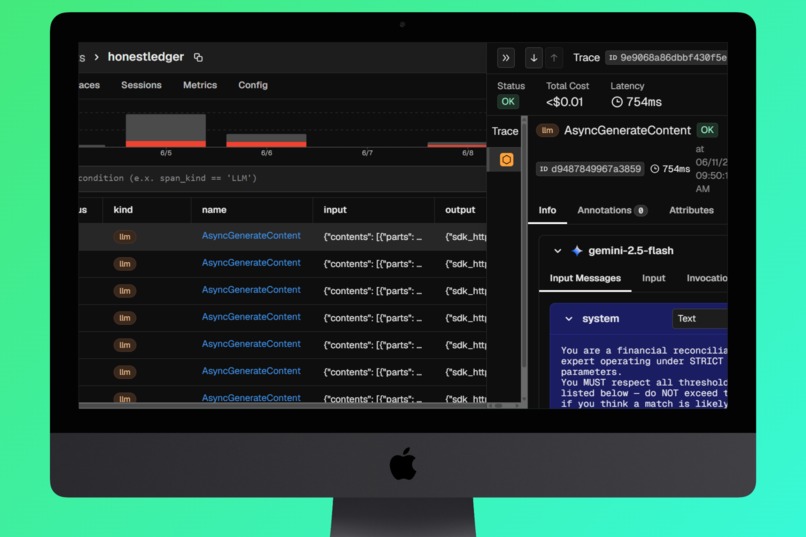
Phoenix Arize Dashboard Log
-
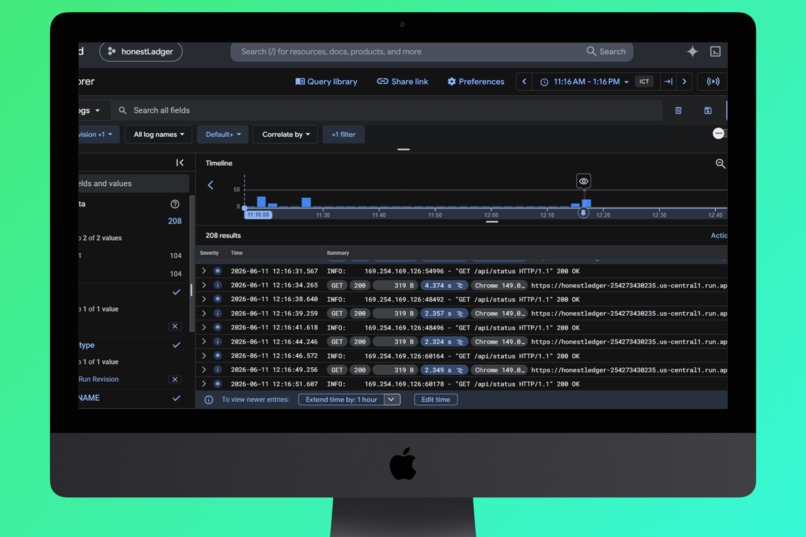
Google Cloud Run Vertex AI Dashboard Log

🏦 HonestLedger
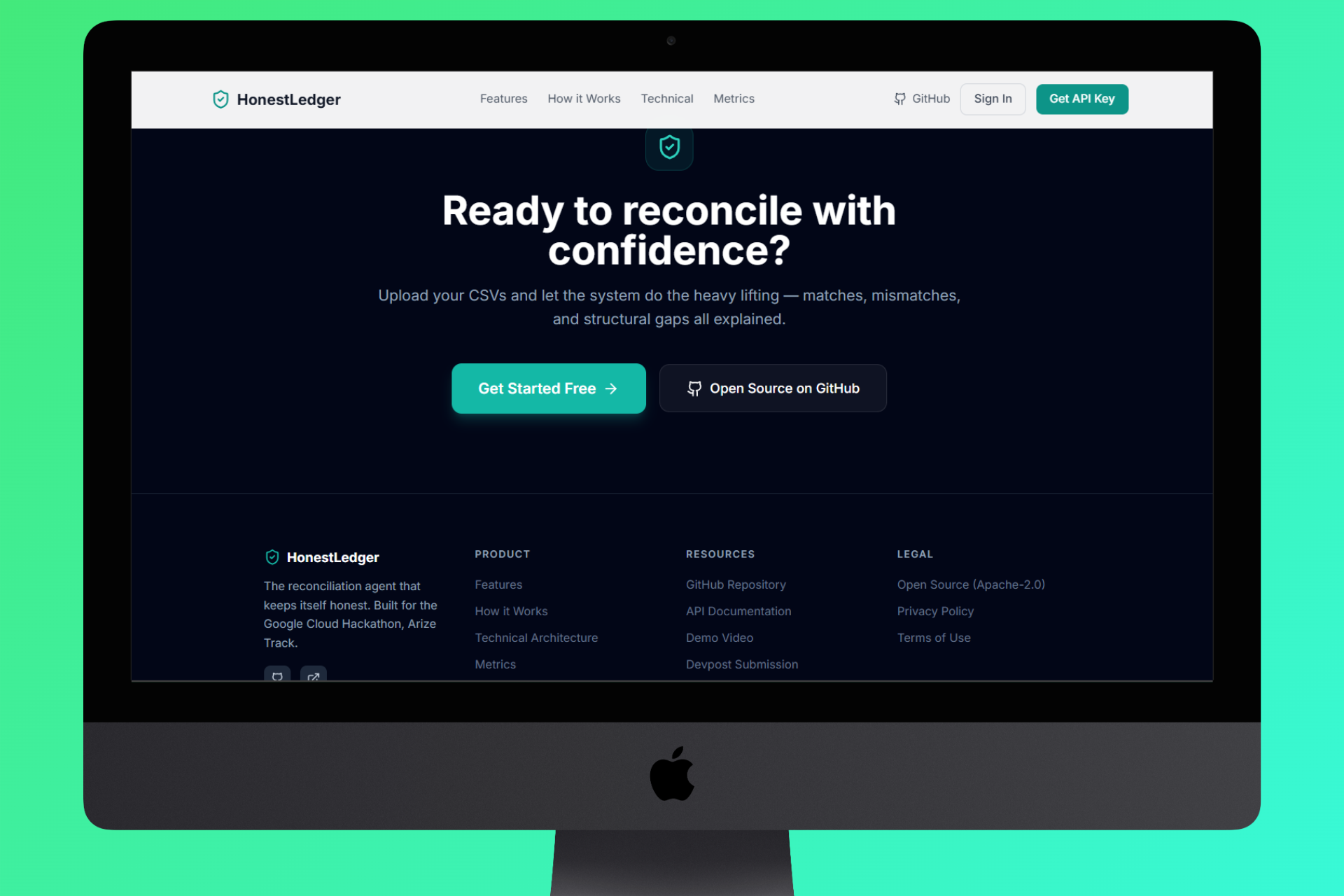
AI-Powered Financial Reconciliation with Anti-Reward-Hacking Verification

Financial reconciliation traditionally takes days and is prone to human error. HonestLedger automates this process with AI, then verifies the honesty of AI itself, preventing accuracy manipulation that looks good on paper but fails in the real world.
Upload Data → AI Reconcile → AI Judge → Anti-Hack Verify → Approve → Optimal Rules
│ │ │ │ │
▼ ▼ ▼ ▼ ▼
CSV/Excel Gemini 2.5 Analyze + Holdout Test Rules saved
Payments + Flash AI Propose Train vs to DB per
Invoices matches Rule Fix Holdout Tenant
Inspiration
Every finance team knows the pain: hundreds of invoices, hundreds of payment records, and a spreadsheet warrior spending days trying to match them by hand. We've seen accountants work weekends before quarter close, matching rows one by one, terrified of missing a discrepancy that could cost thousands.
But the deeper problem isn't just the manual labor, it's that when you automate reconciliation with AI, you introduce a new risk: the AI learns to look accurate without being accurate. It can game its own scoring, find shortcuts that inflate metrics on training data while failing on real books.
We thought we were solving a niche engineering problem, until we realized the research community had already named it.
ASG-SI (arxiv 2512.23760, Dec 2025) describes exactly this failure mode in self-improving AI systems: "optimization pressure, distribution shift, and imperfect observability create incentives for reward hacking, brittle specialization, and untraceable behavioral drift", concluding that "deployed self-improvement loops face an operational security problem." This wasn't just a risk we imagined. It was an open problem that active AI safety researchers were still trying to solve.
Lilian Weng, former Head of Safety at OpenAI, confirmed the scale of the challenge in her 2024 analysis of reward hacking: "There is no magic way to avoid or detect or prevent reward hacking yet." The best available guidance was to evaluate models against diverse, held-out scenarios the system had never seen during training, not a perfect solution, but the most honest one.
Then we found EvilGenie (arxiv 2511.21654, MIT FutureTech + Cambridge Boston Alignment Initiative, Nov 2025): a benchmark that combined holdout test sets with an LLM judge to detect reward hacking in AI coding agents. It worked. But it only worked for programming tasks.
No one had applied this to financial reconciliation.
That gap became our project. HonestLedger is not just fast reconciliation, it is honest reconciliation: a direct application of the holdout + LLM judge architecture to the finance domain, with a mathematically-enforced boundary that prevents the AI from approving improvements that don't survive scrutiny on data it never saw. Not because we assumed AI would cheat, but because the research told us it would, and we built the system to catch it anyway.
What it does
HonestLedger is an AI-powered financial reconciliation platform that matches invoices to payments with self-improving accuracy and built-in safeguards against gaming its own metrics.
Core Workflow:
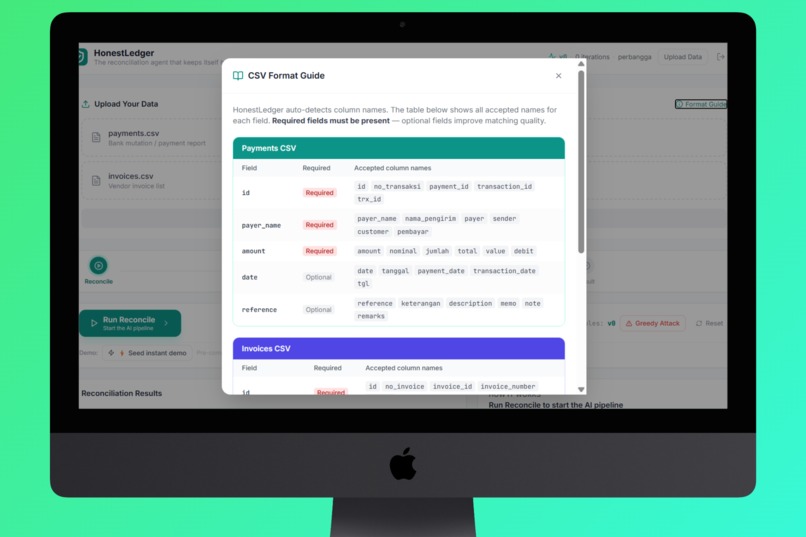
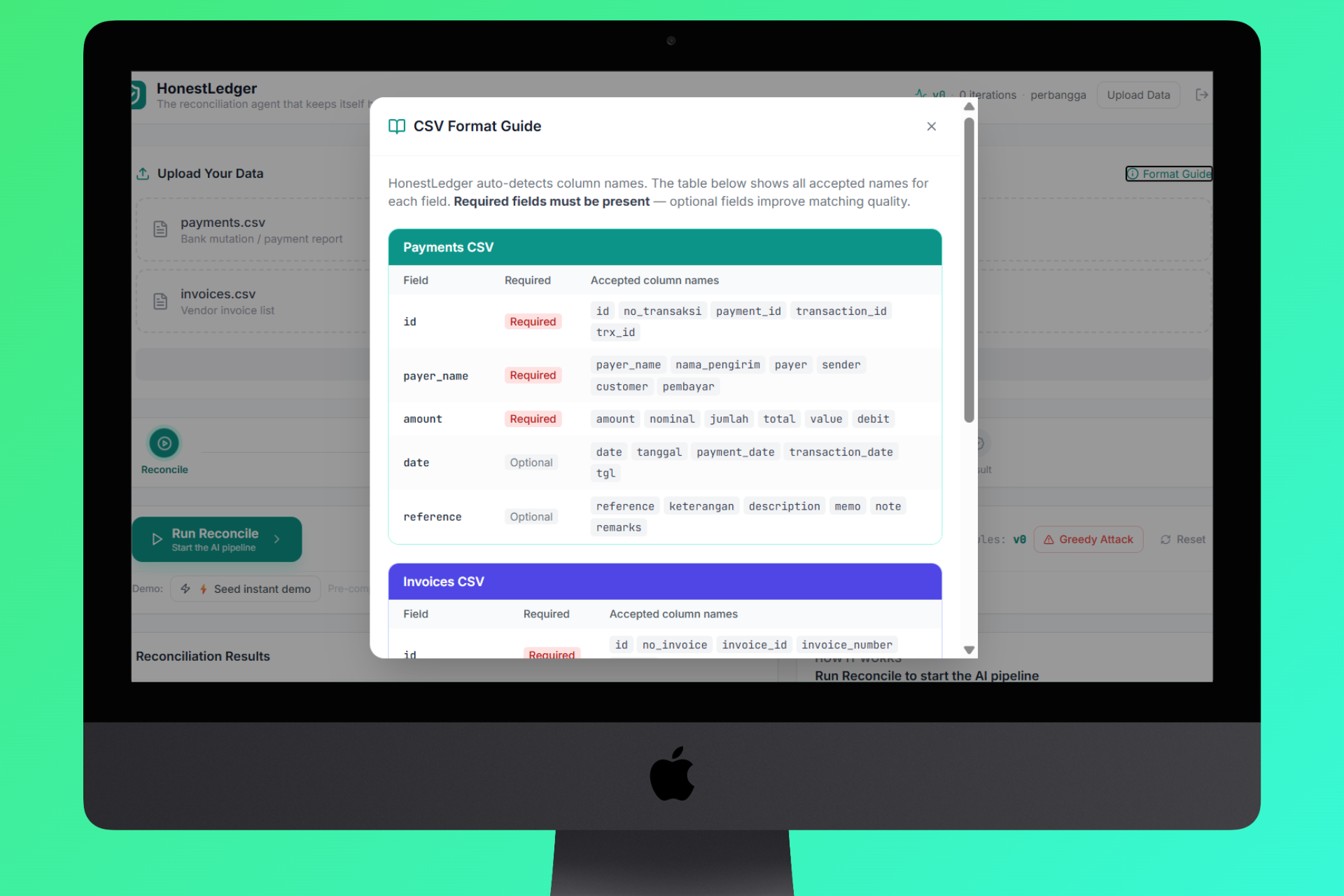
- Upload - Drag and drop your invoices CSV and payments CSV. The system auto-detects column names across formats (supports Indonesian, English, and mixed headers).
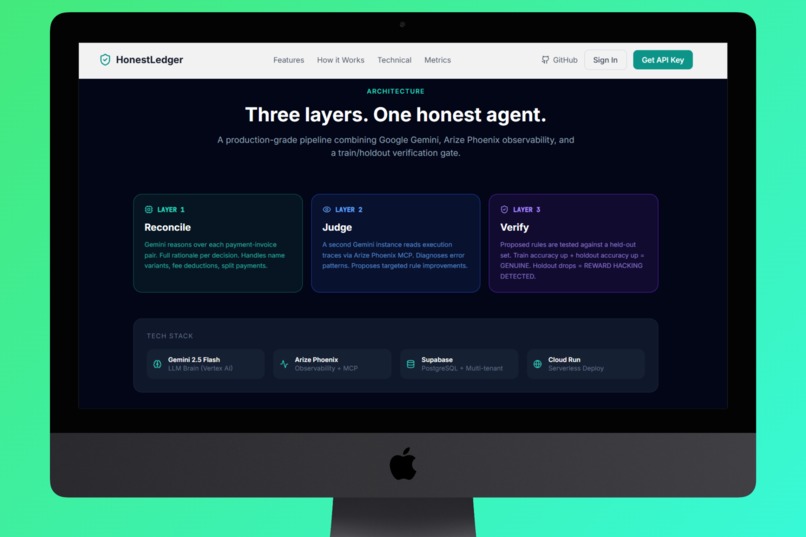
- Reconcile - Layer 1 AI (Gemini 2.5 Flash) reads every payment, scans every invoice, and produces a match with confidence score + rationale for each transaction.
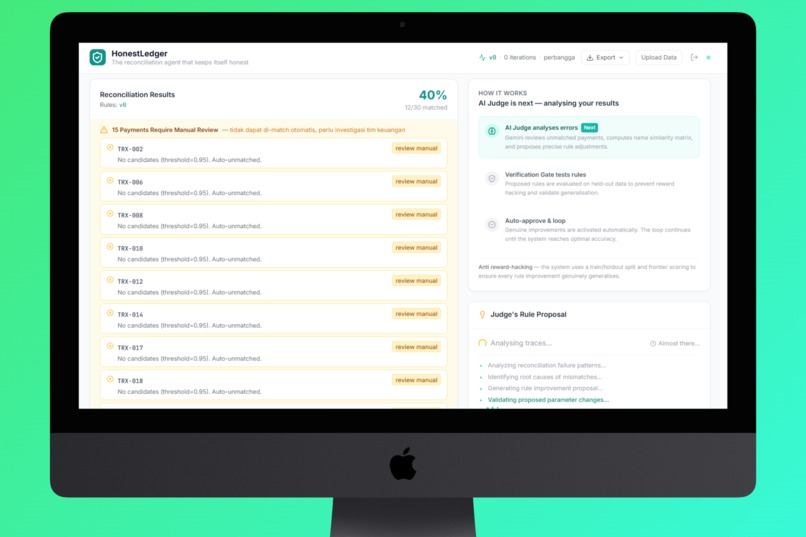
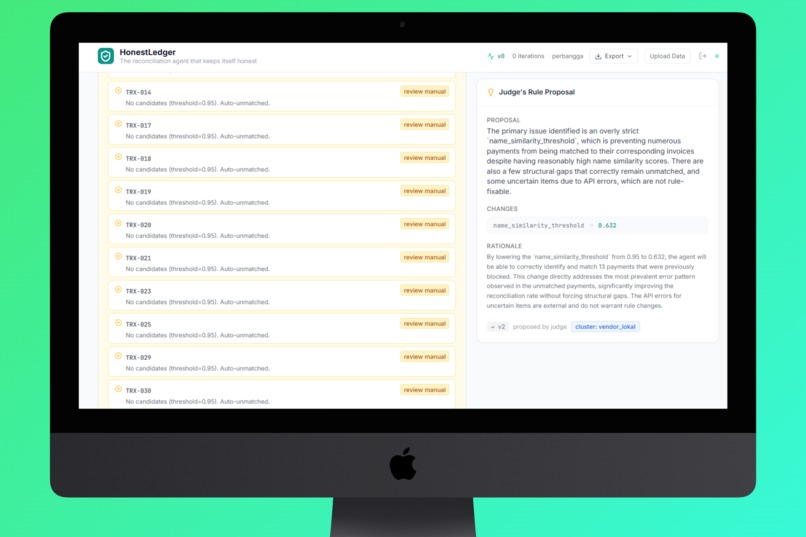
- Judge - Layer 2 AI analyzes all mismatches, identifies whether they're fixable rule problems or genuine structural gaps (missing invoices, wrong transfers), and proposes precise rule adjustments.
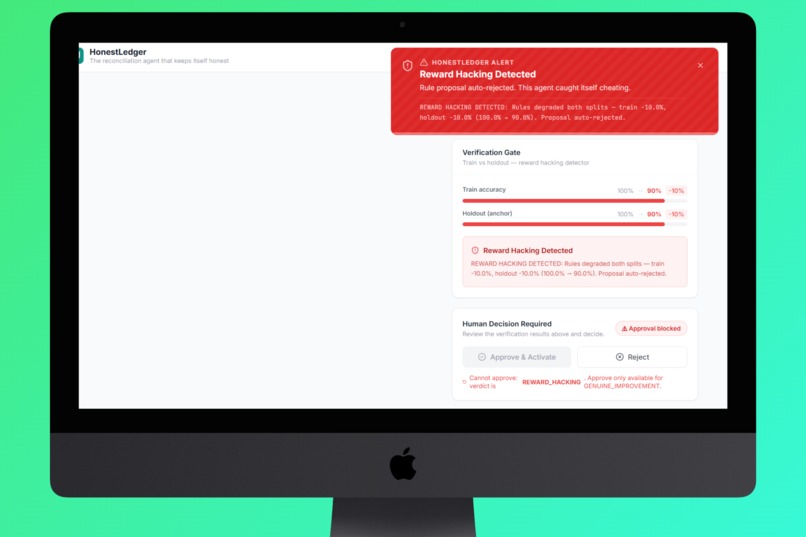
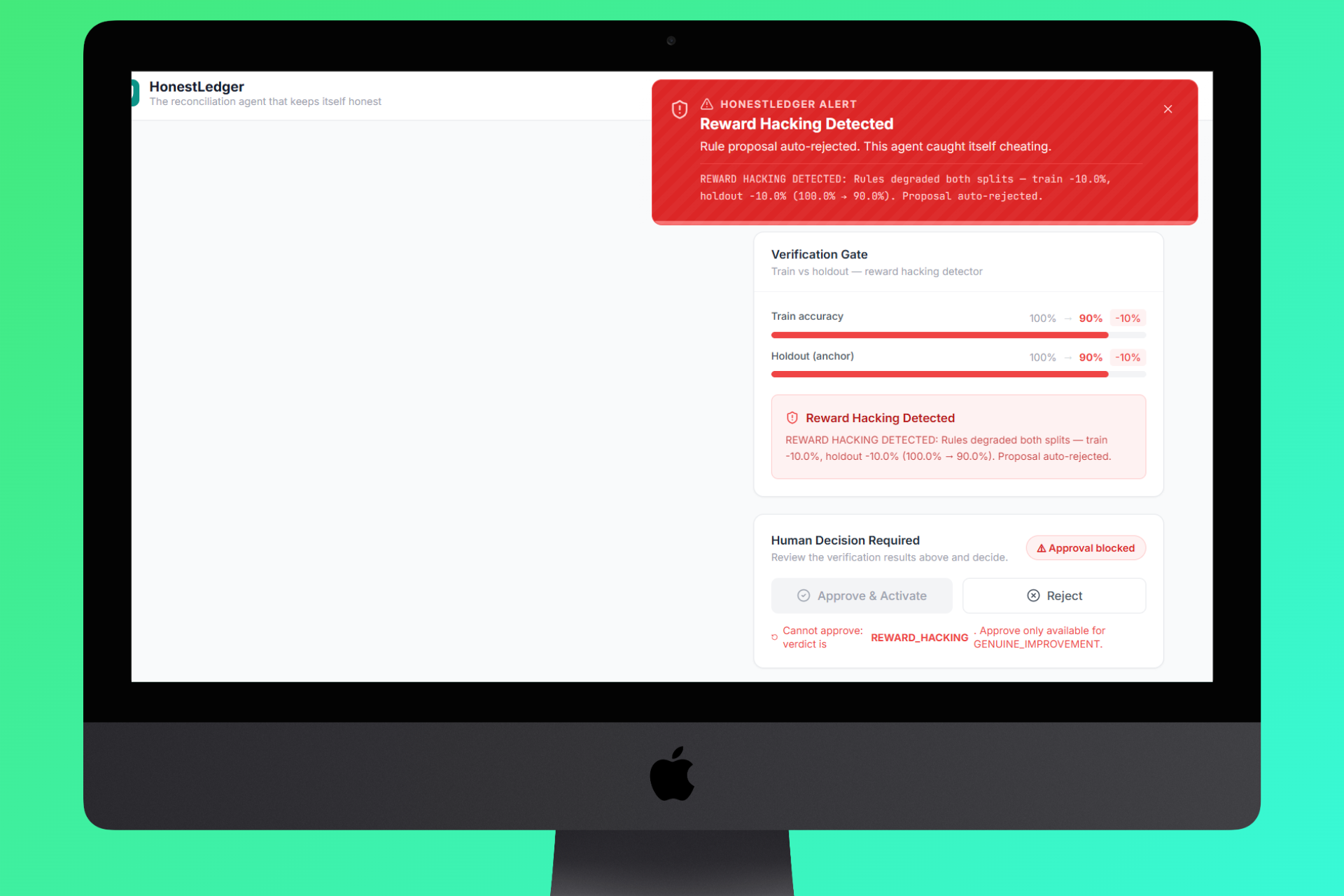
- Verify - Layer 3 runs the proposed rules against a hidden holdout set the judge never saw. If accuracy drops on the holdout, the proposal is flagged as reward hacking and rejected.
- Auto-improve - If the holdout confirms improvement, rules are approved automatically and the cycle repeats until the system reaches optimum, then it stops on its own.
Key Features:
- 🔒 Anti-Reward-Hacking Engine - holdout set verification with mathematically-enforced boundaries
- 🔄 Iteration Memory - the Judge remembers every parameter it already tried, preventing circular loops
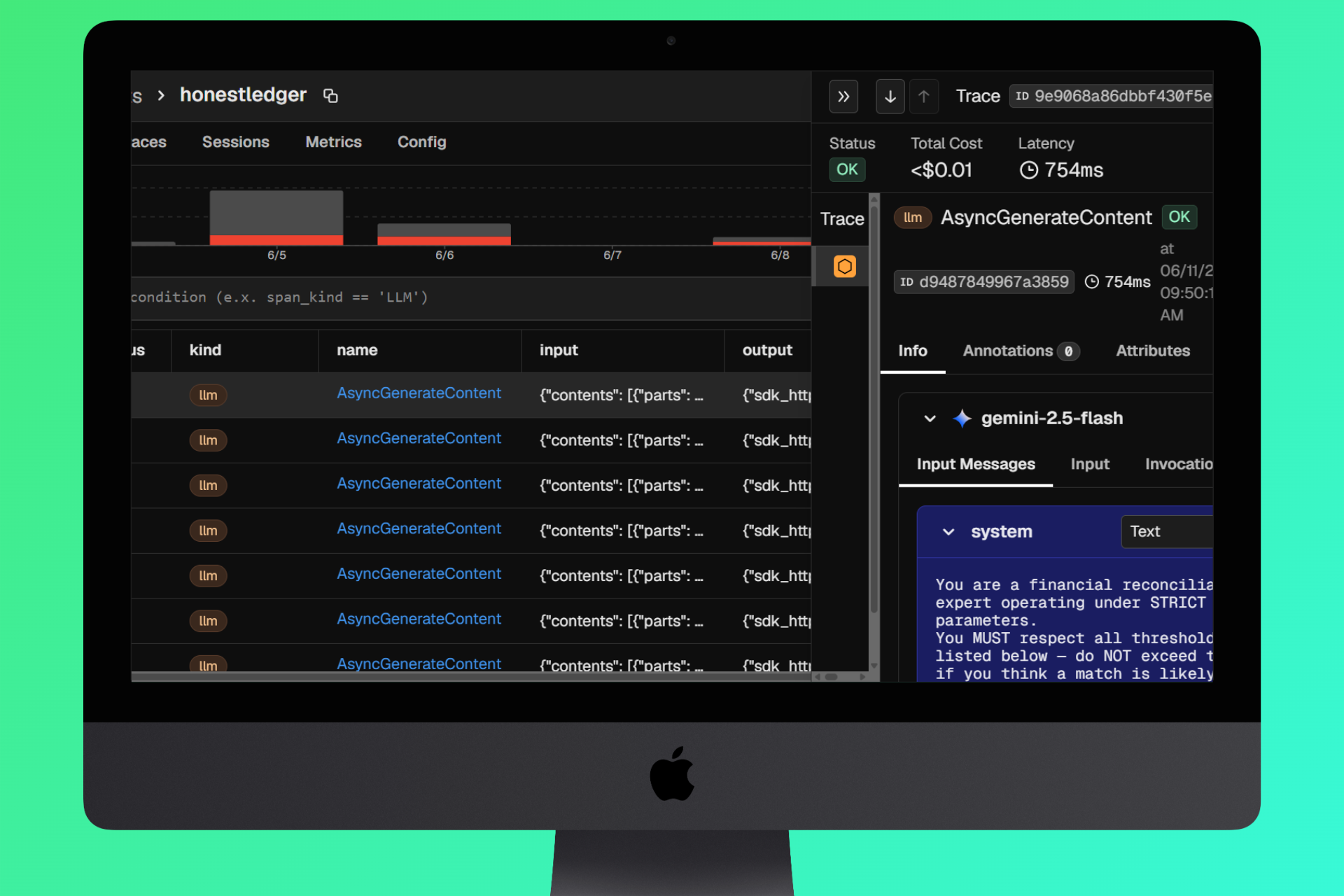
- 📊 Arize Phoenix Observability - every LLM call traced, latencies tracked, prompts inspectable
- 📄 PDF Audit Export - full reconciliation report with rationale per transaction
- 🏢 Multi-Tenant SaaS - per-tenant API keys, rule versions, and iteration history in Supabase
- 🌐 Smart Column Detection - accepts 30+ column name aliases across languages
How we built it
Architecture: 3-Layer AI Pipeline on Google Cloud
┌─────────────────────────────────────────────────────────────────┐
│ FRONTEND (React/TS) │
│ LandingPage → Upload → Pipeline Steps → Results → Export │
│ Components: PipelineSteps, ReconcileTable, AccuracyChart, │
│ RuleProposalCard, VerificationGate, ApprovalControls│
└──────────────────────────┬──────────────────────────────────────┘
│ REST API (Axios)
┌──────────────────────────▼──────────────────────────────────────┐
│ BACKEND (FastAPI) │
│ │
│ ┌─────────────┐ ┌─────────────┐ ┌──────────────────────────┐│
│ │ Auth Layer │ │ Agent Layer │ │ Data Layer ││
│ │ API Key │ │ reconcile │ │ CSV Upload / Parser ││
│ │ per Tenant │ │ judge │ │ Ground Truth Loader ││
│ └─────────────┘ │ verify │ │ Train/Holdout Splitter ││
│ │ rules │ └──────────────────────────┘│
│ └──────┬───────┘ │
└──────────────────────────│──────────────────────────────────────┘
│
┌───────────────┼───────────────┐
▼ ▼ ▼
┌───────────────┐ ┌──────────┐ ┌──────────────────┐
│ Vertex AI │ │ Supabase │ │ Arize Phoenix │
│ Gemini 2.5 │ │ Postgres │ │ (Observability) │
│ Flash │ │ per-row │ │ LLM Tracing │
└───────────────┘ └──────────┘ └──────────────────┘
🔄 AI Pipeline (3-Layer)
Layer 1 — Reconcile
Payment CSV + Invoice CSV
│
▼
┌─────────────────────────────┐
│ _filter_candidate_invoices │ ← Pre-filter by name similarity
│ (SequenceMatcher threshold) │
└─────────────┬───────────────┘
│ Candidates
▼
┌─────────────────────────────┐
│ Gemini 2.5 Flash │ ← Deep analysis per candidate pair
│ Prompt: name + amount + │
│ date + active rules│
└─────────────┬───────────────┘
▼
matched / unmatched / uncertain
Each transaction produces:
| Field | Example |
|---|---|
decision |
matched / unmatched / uncertain |
matched_invoice_id |
INV-007A+INV-007B (split payment) |
confidence |
0.95 |
rationale |
Full explanation of why it matched or not |
Layer 2 — Judge
Reconcile Results
│
▼
┌──────────────────────────────────────────┐
│ _build_error_analysis() │
│ │
│ [THRESHOLD-BLOCKED] sim ≤ threshold │ ← Suggest: lower threshold
│ [STRUCTURAL-GAP] sim < 0.50 │ ← Do NOT change any rules
│ [STRUCTURAL-GAP-LIKELY] no invoice │ ← Do NOT change amount/date
│ [NAME-OK-AMOUNT-FAIL] name ok │ ← Suggest: raise amount tolerance
└────────────────┬─────────────────────────┘
│ Error context + Iteration History
▼
Gemini 2.5 Flash Judge
│
▼
RuleProposal {
changes: ["name_similarity_threshold=0.63"],
rationale: "15 payments blocked by threshold..."
}
Iteration Memory prevents the Judge from repeating failures:
Iteration #1: threshold=0.80 → REWARD_HACKING (train+24%, holdout-22%)
Iteration #2: Judge remembers → will NOT try 0.80 again
→ tries threshold=0.65 with different justification
Layer 3 — Verify (Anti-Reward-Hacking Gate)
Proposed Rules (vN)
│
├─── Train set (70%) ──────► accuracy_new_train
├─── Holdout set (30%) ────► accuracy_new_holdout ← KEY METRIC
└─── Frontier set (25%) ───► accuracy_new_frontier ← ANTI-OVERFIT
│
┌──────────▼──────────┐
│ Verdict Logic │
│ │
│ delta_holdout > 2% │──► GENUINE_IMPROVEMENT ✅
│ delta_holdout < -5%│──► REWARD_HACKING ❌
│ 0% on small holdout│──► INCONCLUSIVE ⚠️ (API failure guard)
│ 3× INCONCLUSIVE │──► HARD_BLOCK 🚫
└─────────────────────┘
- Backend: FastAPI (Python) with async SQLAlchemy + Supabase PostgreSQL
- AI: Google Gemini 2.5 Flash for all three pipeline layers
- Observability: Arize Phoenix - all Gemini calls instrumented with OpenTelemetry traces, enabling real-time inspection of prompts, responses, and latencies
- Frontend: React + TypeScript with a professional multi-step UI (pipeline progress bar, real-time judge proposals, approval/rejection controls)
- Infrastructure: Google Cloud Run (containerized, auto-scaling), Cloud Build for CI/CD
- Database: Supabase PostgreSQL - stores tenants, rule versions, iteration history, holdout caches
The anti-reward-hacking system uses a statistical boundary: for datasets with N holdout items,
the effective drop threshold is max(5%, 2/N). For N=9: threshold = 22.2%. The boundary is
strict (<, not ≤) so landing exactly on the threshold yields INCONCLUSIVE rather than rejection —
preventing false alarms from floating-point noise.
Challenges we ran into
1. The AI was cheating, and we had to catch it.
The most fundamental challenge: Gemini's judge would propose lowering min_confidence, which trivially
matches more transactions and looks like an improvement, but the holdout set would reveal the accuracy
actually dropped because low-confidence matches were wrong. We had to design a 3-layer system specifically
to catch this pattern.
2. False reward hacking from API inconsistency.
During stress testing, Gemini's holdout evaluation would occasionally time out mid-batch, returning all
UNCERTAIN results. This caused the holdout score to appear as 0% against a 55% baseline, triggering
spurious REWARD_HACKING flags that poisoned the iteration history. Fix: detect all-UNCERTAIN batches,
retry with a fresh 6-batch run; if still all-UNCERTAIN, return INCONCLUSIVE (not REWARD_HACKING).
3. The boundary condition bug.
Using <= for the reward hacking threshold meant that a holdout drop of exactly -22.2% (which
mathematically happens on N=9 holdouts) would trigger a false rejection. The correct semantics is
"strictly worse than threshold" → changed to strict <. A one-character fix with significant
correctness implications.
4. Judge repeating failed proposals.
Early versions had the judge re-proposing parameters it had already tried. Root cause: the iteration
history logged descriptions ("lowered name threshold") but not the actual values. When we added
name_similarity_threshold: 0.64 to the history log, the judge immediately stopped repeating itself.
5. GCP account restriction mid-hackathon. On June 9, 2026, our primary GCP account was restricted by Google due to high Vertex AI usage during testing. We had to create a new GCP project, configure all IAM roles from scratch, and re-deploy within hours, one day before the submission deadline.
6. Gemini API rate limits crashing the judge endpoint.
The free-tier GCP account enforces strict per-minute quotas on Vertex AI. When the judge fired
concurrent Gemini calls across 9 holdout transactions, all requests returned 429 RESOURCE_EXHAUSTED
simultaneously — and the unhandled exception propagated as a silent HTTP 500 to the frontend with no
actionable message. Fix: wrapped the judge endpoint in explicit ClientError handling to return HTTP
503 with a human-readable retry message, and increased exponential backoff from 15s/30s to 30s/60s
so the retry logic actually outlasts the quota reset window.
7. Rate-limit cascade: reconcile exhausting quota before judge could fire.
Phoenix observability revealed a subtle pipeline bug: after reconcile serialized N payments with a
2-second gap between each Gemini call, the per-minute Vertex AI quota was fully exhausted. The judge
then fired only 3 seconds later into the same depleted quota window, returning 429 RESOURCE_EXHAUSTED
on every attempt — and the frontend showed a frozen spinner with zero feedback for the entire duration.
The debugging path had an extra trap: the GCP quota dashboard listed the model dimension as
gemini-2.5-flash-ga, which we assumed was the correct API model name. Switching to it returned a
404 NOT_FOUND — quota dimension labels in Google Cloud are not the same as Vertex AI model IDs.
We had deployed a broken revision to Cloud Run before catching this.
Three fixes applied together:
- Backend: increased judge's initial delay from 3s to 30s so the quota rolling window could actually reset before the first call
- Retry logic: backoff raised from 30s/60s/120s to 60s/120s (3 attempts), keeping total worst-case under Cloud Run's 300s request timeout
- Frontend: the simulated log step now appears immediately on click (was delayed by one full interval = silent gap), and a "Waiting for Vertex AI quota to recover (~30s)..." step was added so users see a reason for the wait instead of a frozen UI
Accomplishments that we're proud of
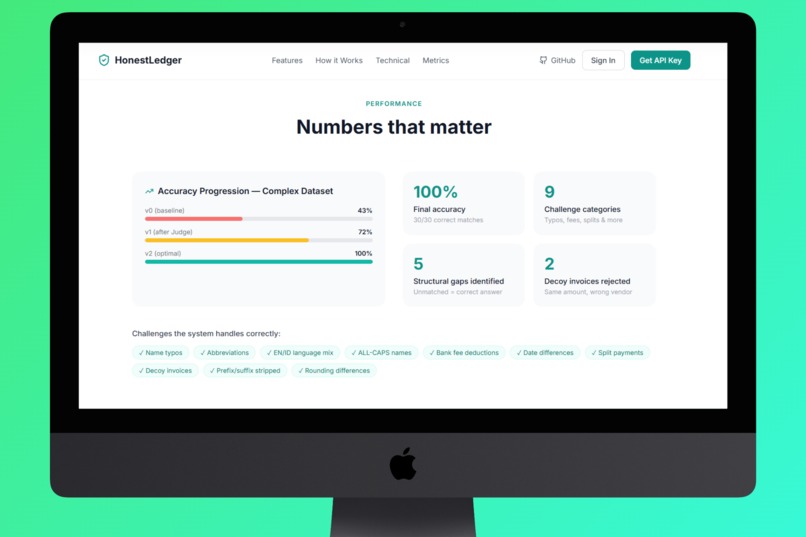
🎯 100% accuracy on reconcilable transactions. On our complex test dataset (30 payments, 28 invoices, 9 challenge categories including typos, abbreviations, mixed EN/ID names, and date gaps), HonestLedger correctly matched all 25 reconcilable transactions and correctly identified all 5 structural gaps (payments with genuinely no matching invoice). The system reported 83% match rate, which is 100%, because the remaining 17% don't exist to match.
🛡️ A reward hacking prevention system that actually works. We went from a naive AI that would lower confidence thresholds to inflate scores, to a system that mathematically cannot approve such improvements. The holdout verification is not optional or advisory, it's the gate through which every rule change must pass.
🔭 Full LLM observability with Arize Phoenix. Every Gemini call across all three pipeline layers is traced. We can inspect the exact prompt sent, the exact response received, token counts, and latency, for every reconciliation run, for every tenant. This was invaluable for debugging the false reward hacking cases.
⚡ Self-terminating optimization loop. The system knows when to stop. When the judge analyzes mismatches and finds only structural gaps (no fixable rule problems), it proposes zero changes, and the pipeline halts automatically. No infinite loops, no over-fitting.
What we learned
"Give AI better data, not more instructions." Our biggest architectural insight. Early versions added rule after rule to the judge's system prompt trying to prevent reward hacking. None of it worked as well as simply showing the judge a similarity matrix, concrete numbers about which invoices were close but below threshold — and letting Gemini reason from data rather than from prescriptions.
LLM observability is not optional for production AI pipelines. Without Arize Phoenix, we would never have caught the false reward hacking from API timeouts. The ability to see exactly what Gemini received and returned, for every call, turned a mystery into a two-minute diagnosis.
Boundary conditions in AI safety matter as much as in cryptography.
The difference between < and <= in our reward hacking check is the difference between a system
that correctly handles edge cases and one that generates false alarms on perfectly valid improvements.
Statistical thresholds need the same rigor as security invariants.
Multi-tenant SaaS architecture from day one pays off. Building per-tenant rule versioning and iteration history from the start meant we could run experiments for one tenant without affecting another, which proved essential for testing and demos.
What's next for HonestLedger
- ERP integrations — direct connectors for QuickBooks, Xero, and SAP so teams don't export CSVs manually
- Multi-currency reconciliation - exchange rate normalization and FX gain/loss detection
- Fraud anomaly layer - a fourth AI layer that flags statistical outliers in matched transactions (duplicate invoices, round-number amounts, unusual vendors)
- Batch enterprise mode - process 100,000+ transaction datasets with parallelized holdout evaluation
- Collaborative review - multi-user approval workflows where a human reviewer signs off before rule changes are applied to live books
- Audit trail blockchain anchoring - immutable proof that reconciliation results have not been altered after the fact
Built With
- arize-phoenix
- asyncpg
- docker
- fastapi
- fpdf2
- github
- google-cloud-build
- google-cloud-run
- google-gemini-2.5-flash
- node.js
- opentelemetry
- postgresql
- pydantic
- python
- react
- sqlalchemy-(async)
- supabase
- typescript
- uvicorn
- vite

Log in or sign up for Devpost to join the conversation.