-
-
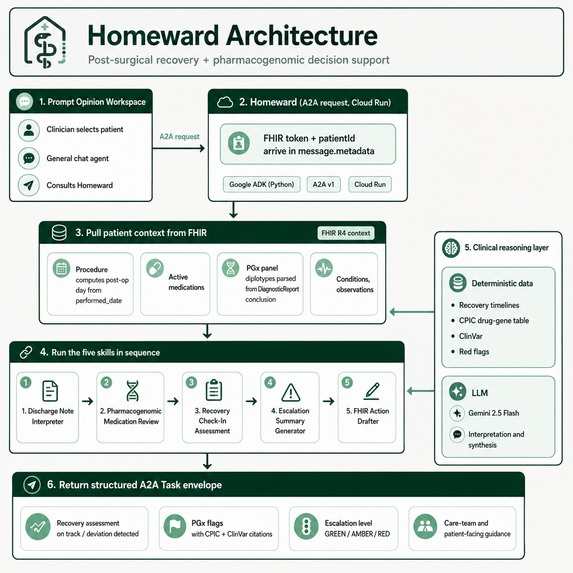
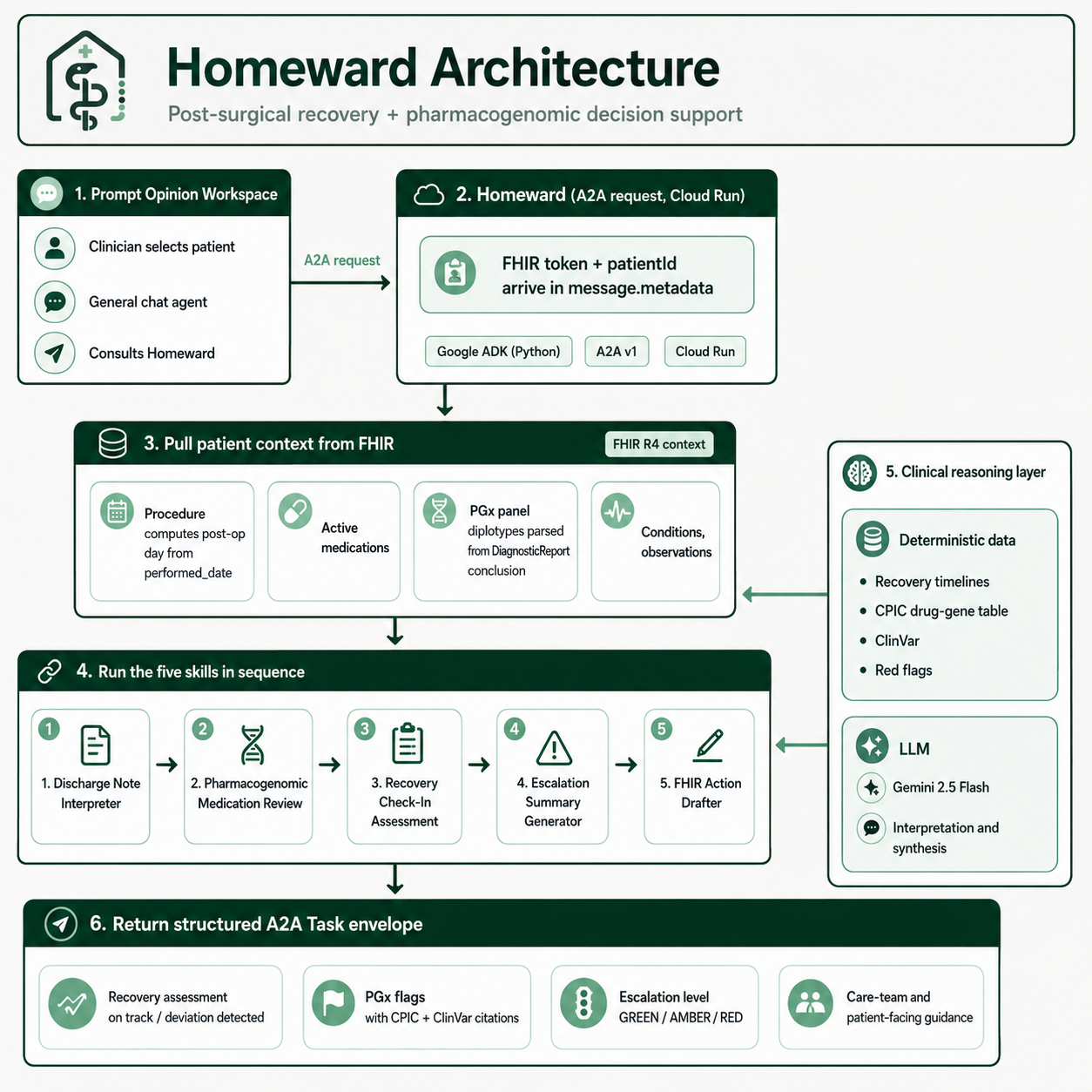
Architecture
Homeward — Post-Op Recovery Meets Pharmacogenomics
An A2A agent that monitors post-surgical recovery and flags pharmacogenomic medication risks, consultable from any clinician workspace in Prompt Opinion. Built for Agents Assemble — The Healthcare AI Endgame.
Inspiration
Two clinical blind spots collide in the 30 days after surgery, and almost nobody is connecting them.
Blind spot one: the post-discharge gap. The majority of surgery in the US is now performed in outpatient or short-stay settings [AHRQ HCUP, 2017]. Patients go home with paper discharge instructions and have no structured clinical visibility until their follow-up appointment 2–4 weeks later. Post-operative complications are the third leading cause of death worldwide [Nepogodiev et al., Lancet 2019]. Most surgeons agree the highest-risk window is exactly the period when the patient has the least clinical contact.
Blind spot two: pharmacogenomics at discharge. Roughly 99% of people carry at least one actionable pharmacogenomic variant [Van Driest et al., 2014; Swen et al. PREPARE, Lancet 2023]. Post-surgical patients are prescribed pain management (codeine, tramadol, oxycodone), anticoagulants (warfarin, clopidogrel), and antiemetics (ondansetron), all with well-characterised drug-gene interactions. A CYP2D6 poor metabolizer prescribed codeine gets no analgesic effect because they cannot convert codeine to morphine. A CYP2C19 rapid metabolizer on clopidogrel after a cardiac procedure may still form clots. These are known, preventable problems that are rarely checked at discharge.
The two belong together. If a patient reports uncontrolled pain on day 3, the clinical question is not just "is this a complication?"; it is also "is the drug working at all in this patient?". That is a fundamentally different insight than either system produces alone.
Homeward is the agent we wished a surgical team had.
What it does
Homeward is a single A2A-enabled specialist consult agent that any general agent inside Prompt Opinion can hand off to. It exposes five skills:
- Discharge Note Interpreter: reads uploaded discharge instructions and the patient's FHIR Procedure resource, and produces a structured recovery expectation: procedure-specific pain trajectory, mobility milestones, medication schedule, red-flag symptoms, follow-up dates.
- Pharmacogenomic Medication Review: pulls
MedicationRequests and the genomicsDiagnosticReportfrom the FHIR server, parses diplotypes for CYP2D6 / CYP2C19 / CYP2C9 / VKORC1 / DPYD / UGT1A1, cross-references against a CPIC-curated drug-gene table, enriches each variant with a ClinVar clinical classification, and flags interactions with risk levels and alternatives. - Recovery Check-In Assessment: compares a patient-reported symptom set against the procedure-specific expected timeline, layers in the PGx context from skill 2 (uncontrolled pain may be drug-gene, not surgical), and returns an on-track / watch / escalate classification.
- Escalation Summary Generator: produces a single GREEN / AMBER / RED clinical summary with separate care-team and patient-facing messaging, with explicit reasoning and recommended actions.
- FHIR Action Drafter: when a pharmacogenomic alternative is warranted, drafts FHIR R4 resources (MedicationRequest plus Communication) with
status="draft",intent="proposal", so the clinician can review and approve with one click. Never auto-submits, never auto-prescribes; this is the last mile, on rails.
The signature scenario: a post-prostatectomy patient on day 4 reports pain 7/10. Generic recovery agents flag this for escalation. Homeward reads the patient's FHIR genomics panel — fetched directly via SHARP-on-MCP or passed inline by the consulting agent — parses CYP2D6 *4/*4 (poor metabolizer), recognises that the prescribed codeine is biochemically inert in this patient, and returns AMBER with the actual cause and a CPIC-cited oxycodone alternative, drafted as a reviewable FHIR MedicationRequest.
How it works
Architecture
┌─────────────────────────────────────────────────────────────────┐
│ Prompt Opinion Workspace │
│ Clinician selects patient → general chat agent → consults │
│ Homeward via A2A (with SHARP-on-MCP FHIR context propagated) │
└──────────────────────┬──────────────────────────────────────────┘
│ JSON-RPC 2.0 (A2A v1)
▼
┌─────────────────────────────────────────────────────────────────┐
│ Homeward (Cloud Run, us-central1) │
│ │
│ ┌──────────────────── Translation middleware ─────────────┐ │
│ │ Method rewrite • role normalisation │ │
│ │ Agent-card patch • A2A v1 Task envelope wrapping │ │
│ │ FHIR context deep-search fallback │ │
│ └────────────────────────┬──────────────────────────────────┘ │
│ │ │
│ ┌────────────────────────▼──────────────────────────────┐ │
│ │ Google ADK agent (gemini-2.5-flash) — 5 skills, │ │
│ │ 11 tools, single process, single cold start │ │
│ └────┬─────────────┬────────────┬────────────┬──────────┘ │
│ │ │ │ │ │
│ ▼ ▼ ▼ ▼ │
│ FHIR client CPIC table ClinVar Procedure │
│ (REST, on (deterministic)classifications timelines │
│ SHARP token) cache (deterministic) │
└─────────────────────────────────────────────────────────────────┘
▲
│ FHIR R4 over Bearer token
▼
Prompt Opinion FHIR server (workspace-scoped)
Stack
| Layer | Tech |
|---|---|
| Agent framework | Google ADK (Python) |
| LLM | Gemini 2.5 Flash (Google AI Studio API) |
| Protocol | A2A v1 over JSON-RPC 2.0 |
| Context propagation | SHARP-on-MCP (fhir-context extension URI) |
| FHIR | R4 REST client, Bearer-token auth |
| Hosting | Google Cloud Run (autoscale 0→N, pinned region) |
| PGx evidence | CPIC drug-gene pairs (curated) + ClinVar variant classifications (pre-cached) |
| Recovery timelines | Hardcoded procedure-specific data (8 procedures × 3 phases) |
What only generative AI can do here
A rules engine can match codeine to CYP2D6. It cannot read a free-text discharge note and extract that "no lifting over ten pounds for two weeks" is a mobility milestone, "call if temperature exceeds 38°C" is a red flag, and "resume normal diet as tolerated" is neither. It cannot decide, given a partial FHIR record with a missing procedure code, that the surgical context can be inferred from the procedure note. And it cannot connect "day 4 pain 7/10" with "CYP2D6 *4/*4 + codeine prescribed" and produce the insight that the complication is the drug failing, not the surgery, unless every cross-product of symptom × medication × phenotype has been pre-enumerated by hand.
Homeward's generative AI layer does three things rule-based software cannot:
- Unstructured input → structured clinical state. Discharge instructions are free-text documents written by humans for humans, in wildly varying styles. Gemini extracts procedure-specific restrictions, follow-up dates, wound care instructions, medication schedules, and red-flag symptoms out of that prose into structured JSON the rest of the pipeline can reason over. A rules engine fails at heterogeneous unstructured input.
- Open-ended tool-use reasoning. The agent decides which FHIR queries to run, when to retry, when a skill is N/A for the patient at hand, when to fall back, and how to compose the output, at runtime, given the patient's actual state. A rules engine has to enumerate every branch at design time. This is why Homeward works for various patients without code changes per scenario.
- Cross-domain synthesis at the patient level. The signature insight ("this is not a surgical complication; the prescribed analgesic is biochemically inert in this patient") emerges from the model joining three independent data sources (recovery trajectory, drug list, PGx phenotype) at inference time. The deterministic layer can tell you codeine + CYP2D6 PM = ineffective and pain 7/10 on day 4 is above expected. Connecting them into a single clinical narrative is reasoning, not lookup.
What's deterministic vs what's LLM
The deterministic layer exists because generative AI shouldn't invent drug interactions or CPIC guidelines. It's a feasibility and safety choice, not an absence of AI. We're explicit about the split so a clinician knows exactly where the model has authority and where it doesn't:
- Deterministic (no LLM): drug-gene matching, CPIC recommendation lookup, ClinVar classification, recovery timeline windows, red-flag rules, escalation severity templates, FHIR resource drafting.
- LLM (Gemini 2.5 Flash): discharge-note interpretation, FHIR tool-use orchestration, cross-domain clinical synthesis, plain-language explanation, severity reasoning text.
We never ask the model to invent a drug interaction, a CPIC guideline, or a FHIR resource shape. Every clinical fact has a citation in a deterministic table. The model's job is to read unstructured input, decide which tools to run, reason across the structured outputs, and write the result. A rules engine cannot do any of those at the open-ended scope this clinical workflow demands.
How a request flows
- Clinician opens Prompt Opinion, selects a patient, launches the general chat agent, types "Consult Homeward on this patient's post-op recovery."
- The general agent sends an A2A
message/sendwith the SHARPfhir-contextblock (FHIR URL + Bearer token + patient ID) in the request metadata. - Homeward's middleware extracts the FHIR context (with a deep-search fallback for ADK runtime quirks), drops it into agent state, and passes the request through.
- The agent runs FHIR queries (
get_procedures,get_active_medications,get_pgx_panel,get_recent_observations,get_active_conditions) to assemble patient state. - Skill tools run in sequence: discharge → PGx → recovery → escalation.
- If a PGx alternative is recommended, the action drafter emits draft FHIR resources.
- The response is returned wrapped in the A2A v1 task envelope (
result.task), which the platform validates and renders in the clinician's chat.
End-to-end, a single-skill consult returns in under 10 seconds; the full five-skill chain in the demo scenario completes in under one minute against the live Prompt Opinion FHIR server.
Built with
- Languages & frameworks: Python 3.12, Google ADK, FastAPI/Starlette (via the A2A SDK), Pydantic, httpx
- Protocols: A2A v1 (JSON-RPC 2.0), MCP, SHARP-on-MCP, FHIR R4
- AI: Gemini 2.5 Flash via Google AI Studio
- Cloud: Google Cloud Run, Cloud Build, Artifact Registry
- Clinical references: CPIC guidelines, ClinVar, PharmGKB
Challenges we ran into
- A2A v1 dialect mismatch. The platform's A2A v1 implementation expects the Task object wrapped under
$.result.task; the a2a-sdk we shipped emits$.resultas the Task. PO also accepts proto-style role/state enums (ROLE_USER,TASK_STATE_COMPLETED) but the SDK parses lowercase. We wrote a translation middleware that rewrites inbound method names (SendMessage→message/send), normalises role enums, patches the agent card with the v1 nested-keysecuritySchemesformat, and wraps the response Task under thetaskkey. Single biggest unblock of the project. - FHIR context lost in the ADK hook. The middleware confirmed the
fhir-contextblock was on the inbound payload, but the ADKbefore_model_callbackcouldn't find it oncallback_contextorllm_request. ADK 1.18 stores A2A request metadata in a path none of the documented sources expose. Fix: a_deep_search_for_fhirwalker that recurses object trees looking for thefhir-contextURI key, added as a fourth fallback metadata source. - FHIR transaction bundles need real UUIDv5
fullUrls. Our first bundles used friendly slugs (urn:uuid:patient-001) which the server silently rejected with "An unexpected error has occurred." Wrote a deterministic UUIDv5 generator and regenerated all four patients with matching internal references. - Cloud Run dependency drift. Container builds were resolving
a2a-sdk[http-server]>=0.3.0to a different version than local, producingModuleNotFoundError: No module named 'a2a.server.apps'at startup. Fix: pin exact versions (a2a-sdk==0.3.22,google-adk==1.18.0).
Accomplishments we're proud of
- A live, production-deployed A2A agent on Cloud Run that fetches real FHIR data and returns a structured AMBER + CYP2D6 PGx flag in under 8 seconds.
- A reusable A2A v1 translation middleware that any future Python external agent on this platform can lift out (and we'd happily PR back to po-adk-python).
- Hybrid clinical reasoning that's both LLM-flexible and evidence-grounded: every drug-gene call has a CPIC citation, every variant has a ClinVar classification, no fabrication.
- A genuine last mile: when an alternative is recommended, the agent drafts the FHIR
MedicationRequestfor the clinician to approve, closing the loop from insight to actionable order.
What we learned
- Standards have dialects. A2A v1 conformance differs platform to platform. Ask the platform team early; assume nothing.
- Deterministic > generative for clinical facts. Judges and clinicians alike will spot a hallucinated drug-gene pair instantly. Hardcode the evidence.
- The model is the writer, not the doctor. We use Gemini for prose, not for prescribing logic.
- Single agent, multiple skills wins. A previous project of ours had 26 micro-agents and 15-minute latency. Homeward is one process, five skills, eight-second roundtrip.
What's next for Homeward
- Native FHIR genomics structures. We parse diplotypes from both
DiagnosticReport.conclusionand structuredObservationresources today; a production deployment should also consumeMolecularSequenceper the CPIC structured-panel format and ingest VCF-level evidence for variants outside the pre-cached panel. - Persistent recovery memory. Each consult is currently a fresh run. Real recovery monitoring should track day-over-day pain trajectory and flag trends, not point-in-time symptoms.
- Procedure depth. Eight procedures × three phases is shallow. A clinical-grade version would partner with surgical specialty societies on per-procedure recovery curves.
- Native FHIR
ServiceRequest/ referral output. Today the drafter emits MedicationRequest + Communication; a clinical-grade version would also draft ServiceRequest for follow-up imaging, Appointment for re-review, etc. - Clinical validation. A prospective study with a surgical team comparing standard discharge follow-up against Homeward-augmented follow-up on PGx-actionable cohorts.
Safety, privacy, and feasibility
- Synthetic data by design for the hackathon; production-ready for real FHIR. Demo patients are hand-built FHIR transaction bundles so the project complies with the no-PHI rule. The same agent code runs unchanged against a real institutional FHIR server: it speaks FHIR R4 over Bearer token via SHARP-on-MCP, the protocol every modern EHR exposes. Scaling from four synthetic patients to a real surgical service is a deployment configuration change, not an architecture change.
- Decision support, not autonomous prescribing. Every PGx recommendation cites a CPIC guideline. Every drafted FHIR resource is
status="draft"/intent="proposal"and carries areview_required: trueflag. A licensed clinician must approve before anything reaches the EHR. - Defers to the care team. Patient-facing language never says "change your medication." It says "contact your surgical team."
- Boundaries on scope. Homeward classifies severity and recommends actions. It does not diagnose, it does not order, it does not auto-message patients. It is a specialist consult, invoked by a clinician, scoped to a single workspace and a single patient at a time.
- Compliance posture. SHARP-on-MCP context propagation means the agent operates entirely under the workspace's existing FHIR authorisation; we never store credentials, we never persist patient data, and the FHIR token is request-scoped. That posture is HIPAA- and GDPR-compatible by construction; the agent never holds the data it reasons over.
- Cost-efficient at hackathon scale; predictable at clinical scale. A single consult uses on the order of 5–10K Gemini 2.5 Flash tokens (fractions of a US cent at current Google AI Studio pricing [Google, 2025]) plus a handful of FHIR REST calls. Cloud Run scales to zero between consults, so idle cost is nil. The hackathon demo runs on the AI Studio free tier; a production deployment would move to Vertex AI for VPC isolation and audit logging, with cost scaling linearly with consult volume rather than with patient population size.
This is feasible in a real healthcare system today. The technical plumbing (FHIR R4, CPIC-curated drug-gene tables, ClinVar, SHARP-on-MCP context propagation) is production-grade and already standard at institutions with active pharmacogenomics programs (Mayo, Cleveland Clinic, Vanderbilt, St. Jude). The agent layer adds the integrative reasoning that doesn't exist between those primitives today. The path from this submission to a clinical pilot is a procurement and validation conversation, not a re-architecture.
Try it
- Live agent:
https://homeward-434257808344.us-central1.run.app - Marketplace: https://app.promptopinion.ai/marketplace/agent/019e0fb7-d3ca-7b51-9fe4-5ed324ce8b24
- Demo video: https://youtu.be/dp52AMb6-Ls
- GitHub: https://github.com/faith-ogun/Homeward
The agent is invokable from any Prompt Opinion workspace as an external A2A agent. Add the live URL as a connection, enable FHIR context, and consult on any synthetic patient with a procedure and PGx panel.
References
- [Nepogodiev et al., Lancet 2019] Nepogodiev D, Martin J, Biccard B, Makupe A, Bhangu A. Global burden of postoperative death. The Lancet. 2019;393(10170):401. https://doi.org/10.1016/S0140-6736(18)33139-8
- [Van Driest et al., 2014] Van Driest SL, Shi Y, Bowton EA, et al. Clinically actionable genotypes among 10,000 patients with preemptive pharmacogenomic testing. Clinical Pharmacology & Therapeutics. 2014;95(4):423–431. https://doi.org/10.1038/clpt.2013.229
- [Swen et al. PREPARE, Lancet 2023] Swen JJ, van der Wouden CH, Manson LE, et al. A 12-gene pharmacogenetic panel to prevent adverse drug reactions: an open-label, multicentre, controlled, cluster-randomised crossover implementation study (PREPARE). The Lancet. 2023;401(10374):347–356. https://doi.org/10.1016/S0140-6736(22)01841-4
- [AHRQ HCUP, 2017] Steiner CA, Karaca Z, Moore BJ, Imshaug MC, Pickens G. Surgeries in Hospital-Based Ambulatory Surgery and Hospital Inpatient Settings, 2014. HCUP Statistical Brief #223, Agency for Healthcare Research and Quality, May 2017. https://hcup-us.ahrq.gov/reports/statbriefs/sb223-Ambulatory-Inpatient-Surgeries-2014.jsp
- [CPIC] Clinical Pharmacogenetics Implementation Consortium guidelines. https://cpicpgx.org/guidelines/
- [ClinVar] Landrum MJ, Lee JM, Benson M, et al. ClinVar: improving access to variant interpretations and supporting evidence. Nucleic Acids Research. https://www.ncbi.nlm.nih.gov/clinvar/
- [CPIC: Crews et al., 2021] Crews KR, Monte AA, Huddart R, et al. Clinical Pharmacogenetics Implementation Consortium Guideline for CYP2D6, OPRM1, and COMT Genotypes and Select Opioid Therapy. Clinical Pharmacology & Therapeutics. 2021. https://cpicpgx.org/guidelines/cpic-guideline-for-codeine-and-cyp2d6/
- [SHARP-on-MCP] SHARP Extension Specification for Model Context Protocol. https://sharponmcp.com/
- [A2A Protocol] Agent2Agent Protocol Specification. https://a2aprotocol.ai/
- [FHIR R4] HL7 Fast Healthcare Interoperability Resources, Release 4. https://hl7.org/fhir/R4/
- [Google, 2025] Google AI Studio / Gemini API pricing. https://ai.google.dev/pricing
- Institutional PGx programs referenced: Mayo Clinic RIGHT Study; Cleveland Clinic Personalized Medication Program; Vanderbilt PREDICT; St. Jude PG4KDS.


Log in or sign up for Devpost to join the conversation.