-
-
-
-
-
Tech Stack visualization
-

Team Photo

Inspiration
One of our team member's fathers was struggling to find the right house to buy in Switzerland, spending hours scrolling through Flatfox, manually cross-referencing neighborhoods, commute times, and amenities. Many of our friends faced the same pain renting apartments. We realized the Swiss property search process is fundamentally broken: listings are scattered, key information is buried, and comparing properties against personal preferences requires tedious manual research. We set out to fix that with AI.
What it does
HomeMatch is an AI-powered real estate advisor for the Swiss market. It has three components:
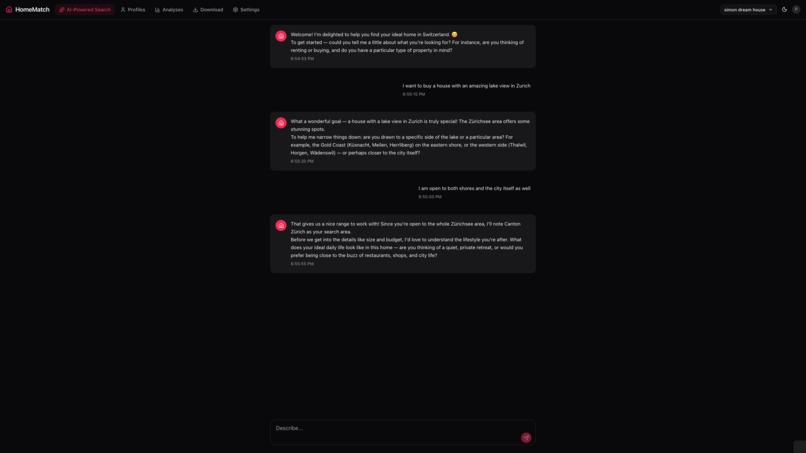
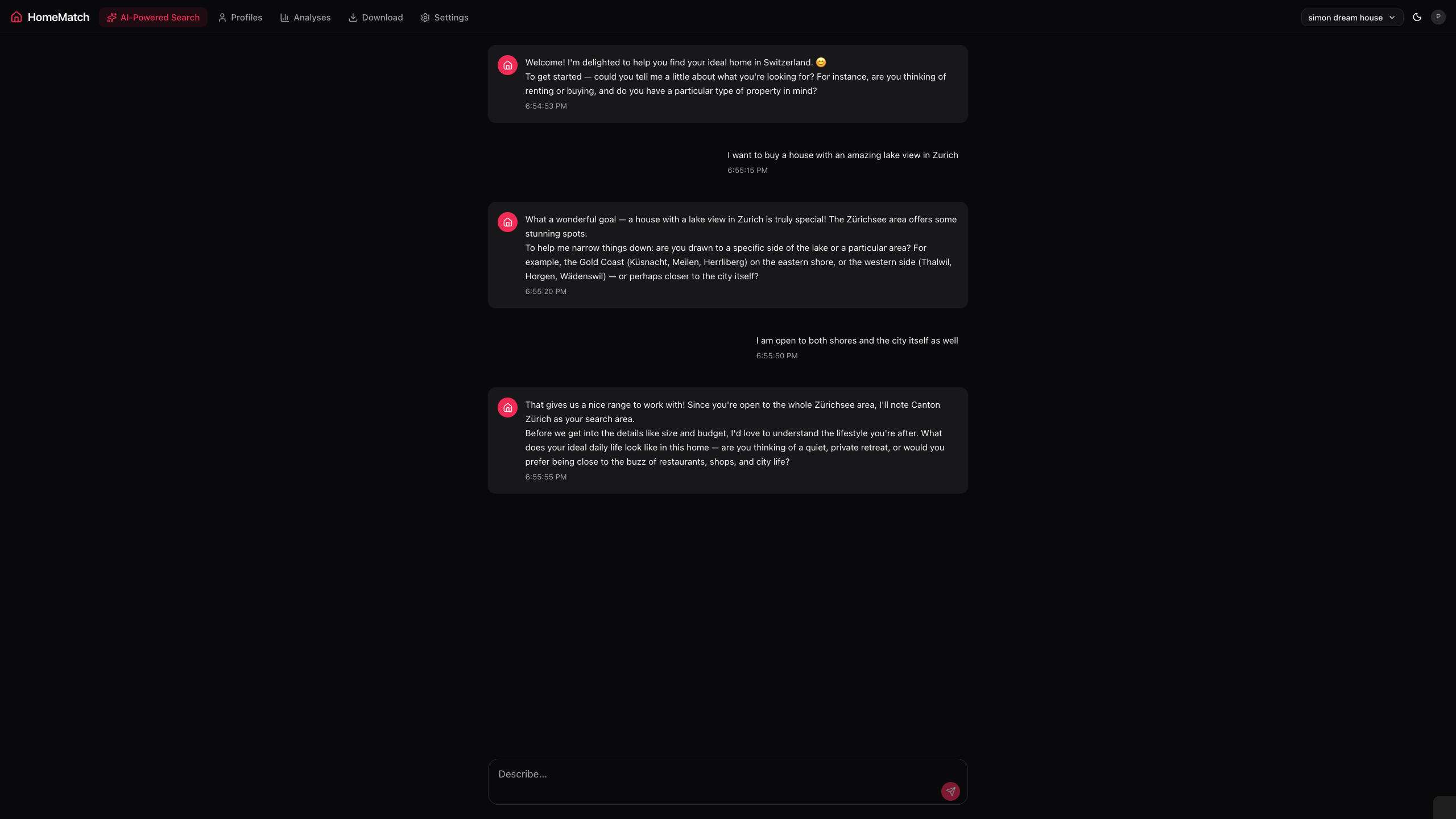
- Conversational AI onboarding: A chat interface (powered by Claude Sonnet) guides users through defining their ideal home: budget, location, dealbreakers, and lifestyle priorities. This creates structured preference profiles.
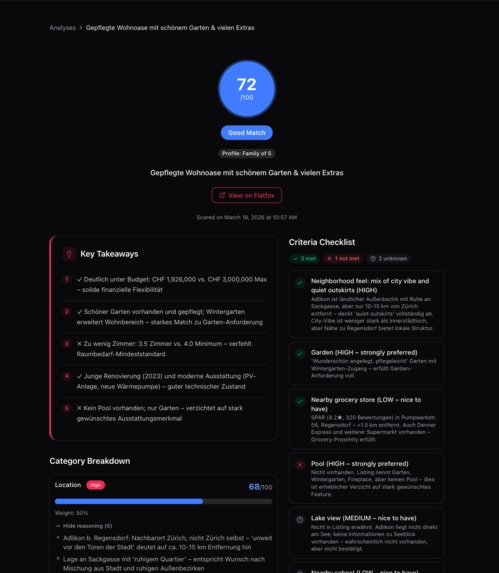
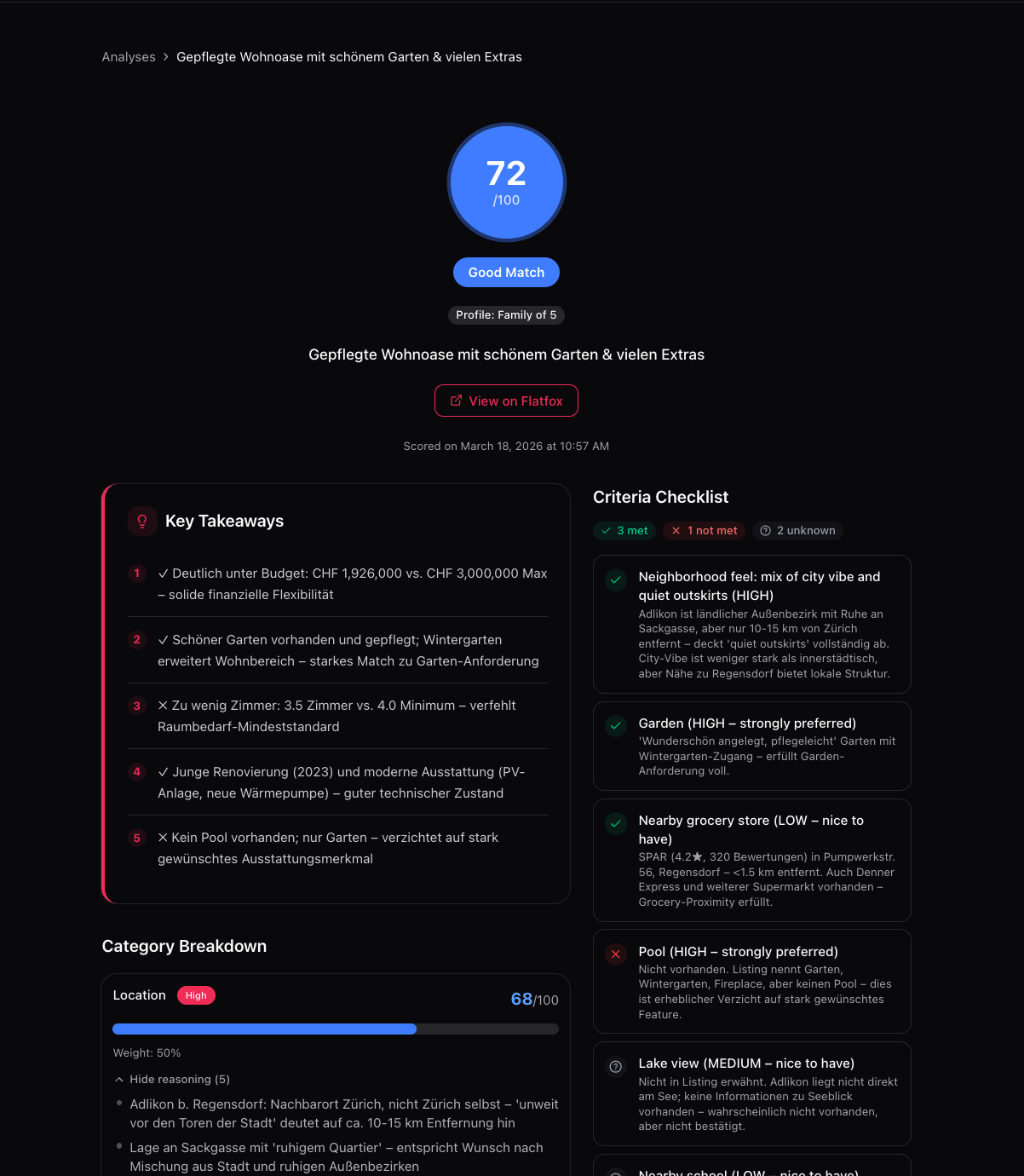
- Chrome extension: Injects directly into Flatfox listing pages, showing real-time AI scores (0-100) with color-coded tiers and category breakdowns (location, price, size, amenities, condition). Users see at a glance whether a listing is worth their time.
- Intelligent scoring engine: A 3-layer hybrid pipeline that combines deterministic formulas, pre-computed listing profiles, and LLM gap-filling to score each listing against user preferences — using vision-based photo analysis, structured Flatfox data, and a rich local dataset of 40,000+ points of interest.
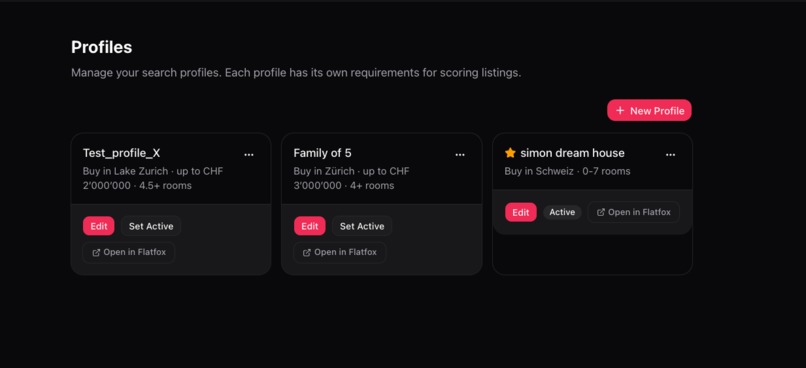
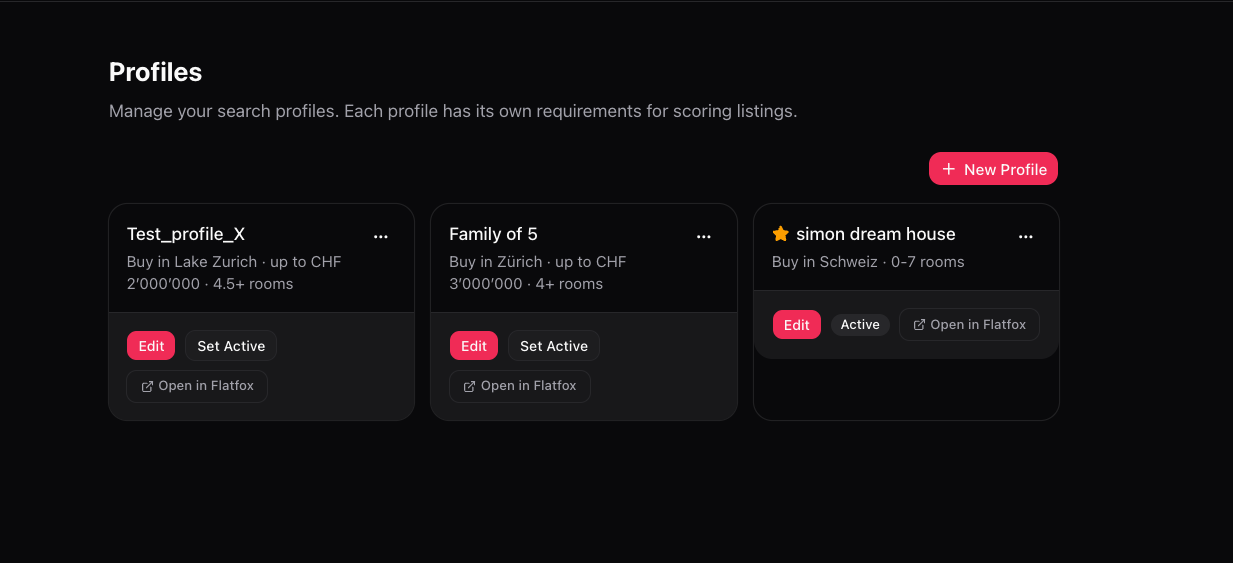
Multi-profile support lets users maintain separate searches (e.g., "downtown apartment for me" vs. "family house for my parents").
How we built it
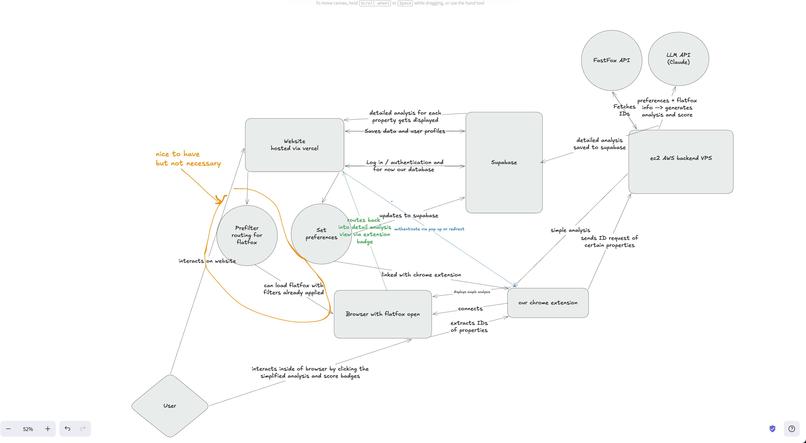
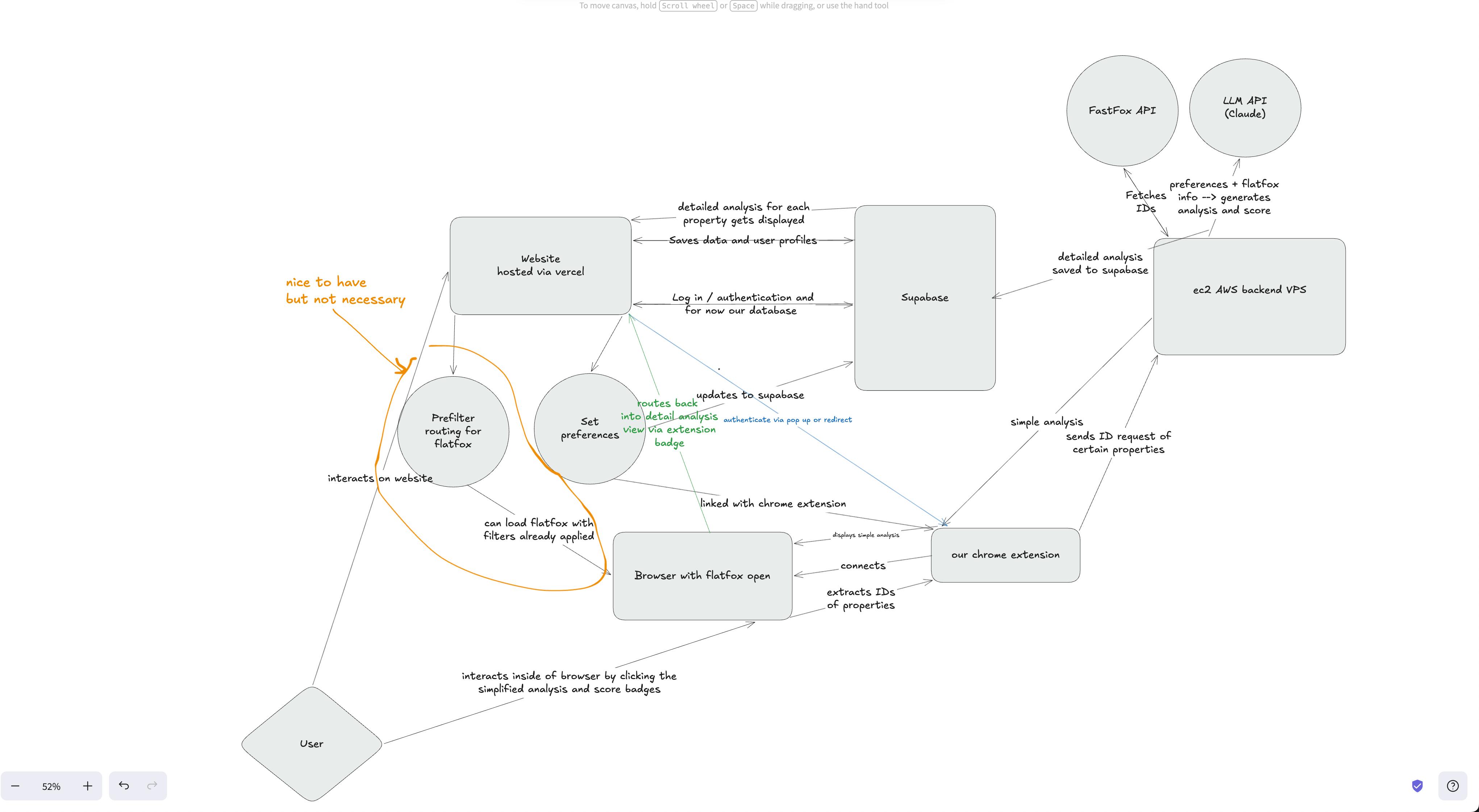
We built a multi-layered architecture over 4 focused coding sessions:
- Backend: FastAPI on AWS EC2 orchestrates scoring via a 3-layer pipeline. Layer 1 pre-computes ListingProfiles using a Claude-powered research agent that analyzes listing images (condition, lighting, kitchen/bathroom quality) and descriptions (neighborhood character, noise estimates). Layer 2 runs purely deterministic scoring — no LLM calls — using exponential decay formulas for price, distance, size, and binary feature matching across 55+ attribute aliases. Layer 3 uses OpenRouter (Gemini Flash) to cheaply fill any remaining data gaps. A Claude Haiku fallback handles listings without pre-computed profiles.
- Frontend: Next.js web app on Vercel handles auth, profile management, and the conversational onboarding chat. Supabase provides authentication, Postgres with Row Level Security, and edge functions that act as a caching and auth proxy layer.
- Extension: Built with WXT (Manifest V3), the Chrome extension injects scoring badges directly into Flatfox pages using Shadow DOM isolation, communicating through the Supabase edge function layer.
Open Data & Enrichment Datasets
We enriched our scoring engine with multiple open-source and public datasets, all imported into Supabase for real-time spatial queries:
- OpenStreetMap via Overpass API: Bulk-imported 40,000+ POIs across Canton Zürich covering 7 category groups: amenities (restaurants, schools, pharmacies, hospitals), shops (supermarkets, convenience stores), leisure (parks, playgrounds, gyms), tourism, healthcare, public transport/railway stops, landuse, and natural features/waterways. Each POI is stored with coordinates and full OSM tags for spatial nearest-neighbor queries.
- ZVV Transit Stops: Zürich's public transit network stops with route/line metadata, imported from Canton Zürich's WFS geodata service. Used for precise public transport proximity scoring (tram, bus, S-Bahn).
- ÖV-Güteklassen (Transit Quality Classes): Canton-wide A-F transit accessibility ratings from the official Canton Zürich map service, giving every location a standardized transit quality grade.
- Population Density: Per-hectare population data across Canton Zürich, used to infer neighborhood character (urban core vs. quiet residential).
- Street Noise Data: City of Zürich's Strassenlärmkataster (street noise evaluation dataset), enabling data-backed noise level estimates rather than guesswork from listing descriptions.
- Rent Benchmarks: Official City of Zürich rent-per-sqm data by Stadtquartier, enabling our "below/at/above market" pricing assessment.
- Tax Rates (Steuerfuss): Per-municipality tax multipliers for Canton Zürich, relevant for buyers comparing total cost of ownership across communes.
- Air Quality: City of Zürich air monitoring station data (daily pollutant measurements).
- Active Construction Projects: City of Zürich's current Tiefbau (civil engineering) projects, flagging potential construction noise near listings.
- Flatfox Listings API + HTML Scraping: Flatfox's public API provides listing metadata, but returns stale prices — so we built an HTML scraping layer to extract actual displayed prices.
- Apify Google Places Crawler: Used as a fallback for amenity data outside Zürich, fetching nearby places with ratings and reviews.
All spatial datasets are queried at scoring time using bounding-box lookups with haversine distance calculations, giving sub-second amenity proximity results without any external API calls.
Challenges we ran into
- Flatfox API unreliability: We discovered the public API returns stale/incorrect prices. We had to build an HTML scraping layer to extract the actual displayed prices from listing pages.
- Mixed content blocking: The HTTPS web app couldn't call our HTTP backend directly. We solved this with a Next.js API proxy route.
- Making three independent systems work together: The Chrome extension, web app, and backend each work independently, but orchestrating auth, caching, and real-time scoring across all three was the hardest integration challenge.
- Scaling forced a complete architectural rethink: Our original architecture called Claude for every single listing score — fine for 10 listings, impossible for 1,800+. We had to throw out the initial approach and rebuild from scratch: pre-computed listing profiles (Layer 1, batch-analyzed once), deterministic formula scoring (Layer 2, no LLM at all), and cheap LLM gap-fill only where needed (Layer 3, Gemini Flash via OpenRouter). This cut per-score cost by ~95% and latency from 15-20 seconds to under 2 seconds, but it meant rewriting the entire scoring pipeline mid-hackathon.
- Open data wrangling: Swiss open data comes in a mix of WFS services, CSVs, and Overpass XML, each with different coordinate systems, encodings, and quirks. We built a unified import pipeline that normalizes everything into a single spatial-queryable table.
- Rapidly evolving requirements: Partner feedback and changing priorities meant our tech stack kept evolving day by day. What started as a simple Claude-per-request scorer became a 3-layer hybrid pipeline with 10+ open datasets, because each conversation with real estate professionals surfaced new must-have data dimensions. We had to architect for change from the start — modular services, swappable data sources, and a scoring engine that could absorb new signals without rewriting the core.
Accomplishments we're proud of
- Real-world validation: We connected with Vera Lee Caflisch, a real estate agent with 7 years of experience, who piloted HomeMatch with her junior agent. In early testing, they reported a 40% increase in relevant properties identified in the first day. This is based on a small sample size and we are actively collecting more data to validate this further. We are in discussions to pilot with Bellevia Immobilien in the coming days.
- Production-ready system: This isn't a demo. It's a live, fully hosted product with auth, caching, multi-profile support, and a real Chrome extension.
- 40,000+ POI dataset: We built a comprehensive local amenity database from OpenStreetMap, Swiss transit data, noise maps, rent benchmarks, and tax rates — enabling rich scoring without per-request API costs.
- 3-layer hybrid scoring: Our deterministic + LLM pipeline scores listings in under 2 seconds with pre-computed profiles, down from 15-20 seconds with the original all-Claude approach.
What we learned
- That LLM tool-use (Claude calling Apify mid-scoring) creates a fundamentally better UX than pre-fetching all data. The AI decides what context it needs.
- That real users (like Vera) care most about reducing time-to-decision, not just accuracy.
- That building for a real market (Swiss real estate) forces you to handle messy, unreliable data sources, and that's where the real value is.
- That open data is incredibly powerful when properly normalized. Swiss cantons and cities publish rich geodata — transit quality maps, noise surveys, rent statistics — but it's scattered across dozens of WFS endpoints and CSV files. The engineering effort to unify it pays off massively at scoring time.
What's next
- Featherless AI vision analysis: Using sponsored open-source multimodal models (Qwen3.5-27B) to run deep apartment photo analysis — lighting quality, interior condition, room layout — at zero marginal cost across all 1,800+ Zürich listings.
- Expanding beyond Flatfox to other Swiss platforms (Homegate, ImmoScout24)
- Deeper open data integration: commute time modeling from ZVV timetables, school quality ratings, historical rent trends
- Formal pilot with Bellevia Immobilien and data collection for scoring accuracy benchmarks
Built With
- anthropic-claude-api-(haiku-4.5
- anthropicapi
- apify-(google-places-crawler)
- aws-ec2
- fastapi
- flatfox
- next.js
- nominatim
- python
- react
- sonnet-4.6)
- supabase-(auth-+-postgres-+-edge-functions)
- tailwind-css
- typescript
- vercel
- wxt-(chrome-extension)

Log in or sign up for Devpost to join the conversation.