-
-
Find the Best City For You Using Our Algorithm!
In order to best gauge which city suits an individual, we have created an interactive web application involving data/ML techniques to optimize which cities are most desirable from individual tastes.
Data Use
When we first looked at this problem we wanted to gauge what metrics might impact a city’s desirability. In doing so we took from the given fields (movehub_rating, purchase_power, health_care, quality_of_life, pollution, crime_rating) and crawled the internet for more information. By using web-scrawling frameworks in conjunction with data from the World Population Center, we were able to retrieve the following metrics for each of our 214 cities: population, ‘happiness’ rank, weather quality, democratic governance, and apartment price per square foot. We also used web scrapers to retrieve supplemental material for our output on our web app, such as images of every city. By merging and joining different datasets together, we were able to piece together a final dataset that we then used in our visualization. To make this process more efficient, we stored each of our CSVs in a public-access S3 bucket hosted by AWS. In doing so, we were able to work around the constraint that GitHub had regarding the file size of raw data.
Home_Finder is nothing without data. Behind the sleek StreamLit UI lies a myriad of datasets that allow our team to find your new home. By using these datasets, everything from a city's congestion to its democratic values can be factored into your next move! However, ensuring this functionality meant a serious amount of data-wrangling. Here's how our team made it happen:
POPULATION
The number of cars on the road, the chance to see breathtaking events with hundreds of people, and a moment to enjoy a silent sunset; What do these all have in common? They're deeply dependent on the population of the places we live in. Populous cities are centers of innovations, offering a rush of energy to its residents. Meanwhile, small towns promise home-seekers the quietness and peace of rural life.
Our data on population was sourced from the World Population Review. Processing this data involved web-scraping the website using BeautifulSoup to get current data on global city populations.
HAPPINESS
Happiness is the one thing that everyone chases, why not follow it to your new home? While some say happiness is hard to quantify, but the leading scholars from the World Happiness Report beg to differ.
They use a wide range of factors from GDP per capita to the generosity of a nation's citizens to determine a nation's place on the Happiness ranking. This dataset was sourced from Kaggle and required some minor data-cleaning. While the Happiness data was originally a ranking, it was easier to understand on a scale of 1 to 100. As such, we scaled the rankings to increase the readability of our statistics.
DEMOCRACY
Democratic values are often an important characteristic in determining if one wants to live or much less, visit, a new country. We used the scores for the World Democracy report to create a measure that dramatically varied between one location to another.
COST OF LIVING
The cost of living dataset was directly sourced from Numbeo, but was processed so that every single one of the "Price per Square Foot" figures, originally stored in a variety of international countries, was standardized to US$.
CITY IMAGES
To expedite building a unique look and feel to our product, the team behind Home_Finder used more Beautiful Soup web-scraping to find images for each city.
Analytics
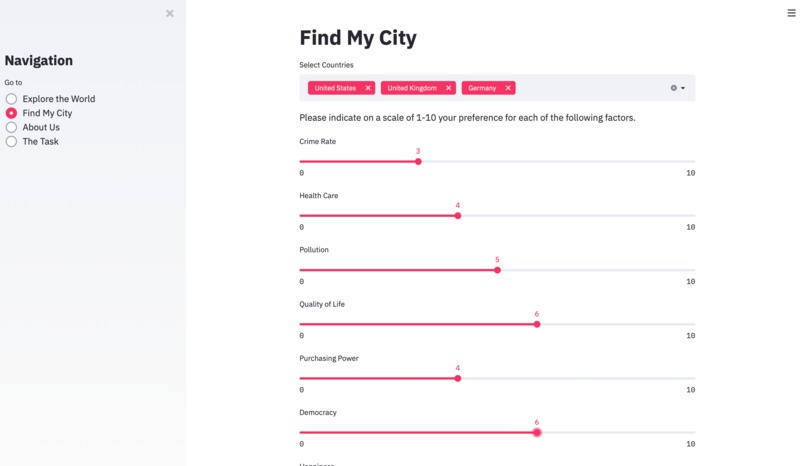
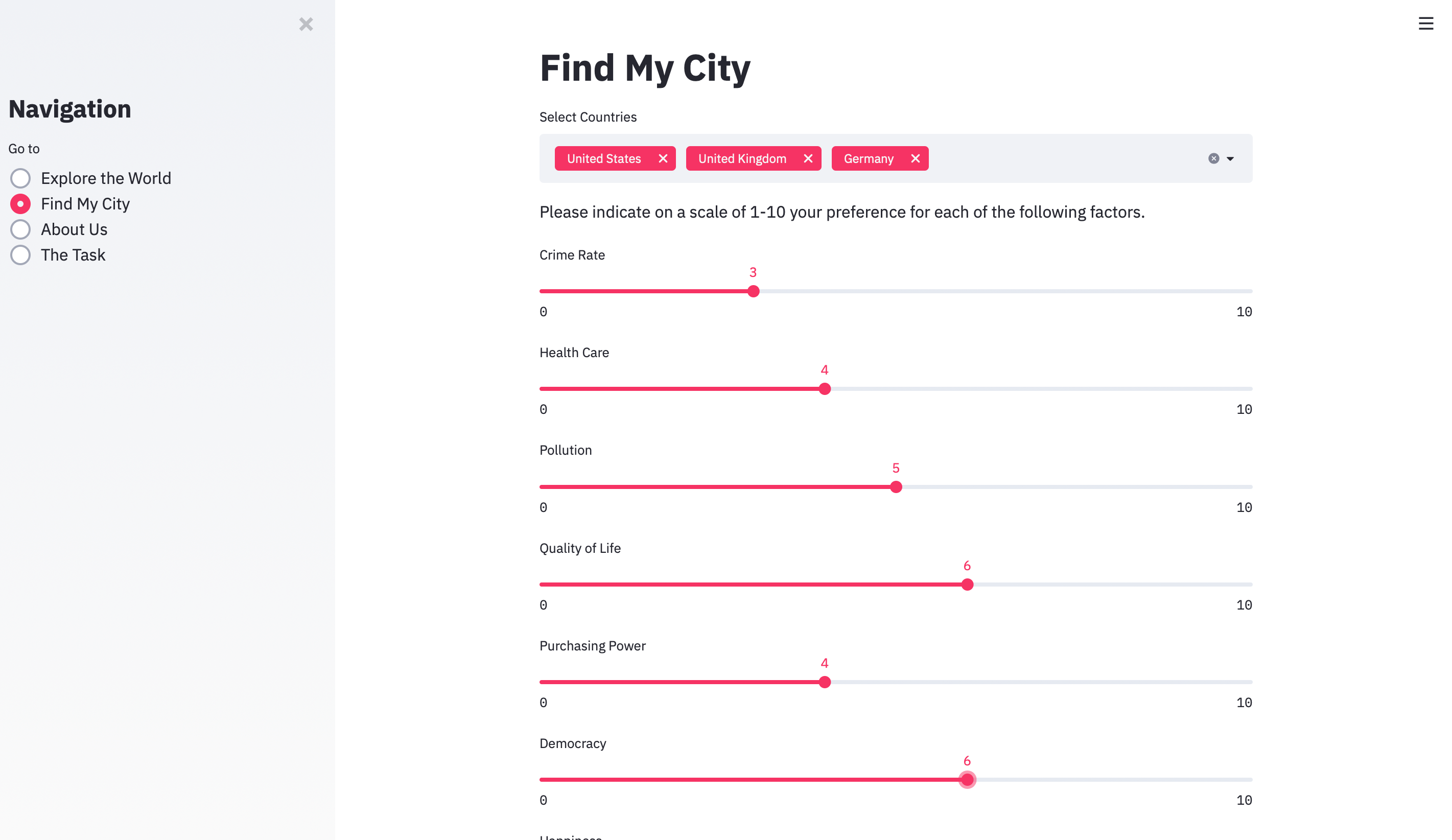
We wanted to provide an easy way for users to customize their preferences of all the features in our dataset and be provided with the top 4 best cities handpicked by a machine learning algorithm. After countless hours of experimentation, we decided to apply unsupervised machine learning by using K-Means Clustering to grouped cities from our dataset together based upon similarities in key features. We used metrics such as the Davies Bouldin (DBI) score to tune and optimize the hyperparameters in our model. With this trained machine learning model, we were able to input a user's desired living conditions, and output a cluster that best suits their needs. We then would deliver these fascinating insights from our ML model to the user by returning a snapshot of the top cities generated for them. We decided to take this one step further by allowing users to optionally specify a country they prefer. By specifying this optional input, a snapshot of the top 4 best-suited cities within the specified country would be returned. With this invaluable insight from our algorithm, we have leveraged the power of advanced analytics to help users make more informed decisions.
Visualization
One of our key goals was to display our data and in turn our visualization in such a way that a user could choose what specific countries they wanted to hone in on. Through a series of weights, we create a desirability index for each country - creating an overall score. By involving K-Means Clustering, we then successfully deduced the top 4 classes (i.e. ‘cities’) based on a user’s preferences (as dictated by a sliding bar). Using Streamlit and Heroku - a cloud Platform as a Service - we created an interactive application with which the user can see their preferences reflected in real-time. Consisting of multiple pages, we first ‘explore our world’ by looking at the desirability index of every city we are concerned about. Each city is magnified to a certain degree based on its population count (larger population in a city indicating greater circle). The desirability index was a sequential color cycle with darker color indicating a higher score and more desirable city. Then on the ‘Find my City’ page we delve deeper into the top 4 predicted cities unique to each user’s preferences. This approach is especially helpful seeing as we have different options along with their respective visualizations so a user can compare and contrast the best options available to them.
Impact
In this day and age, remote work is slowly becoming the norm. As a result, our lives are largely dictated in our places of residence and much of our time is spent in our respective communities and cities. Where we decide to do our everyday mundane tasks slowly changes our mindset, outlook and our bank accounts. By taking the time to deduce which city is the best for our future selves we are positioning ourselves up for success. Our City Searching Tool takes from a variety of metrics to create a comprehensive solution using Machine Learning. By maximizing the likelihood that you can call a new city your home we help set users up for success.
Built With
- amazon-web-services
- beautiful-soup
- boto
- country-converter
- geograpy
- github
- heroku
- jupyter
- kmeans
- numpy
- pandas
- pickle
- plotly
- python
- requests
- s3
- scikit-learn
- streamlit
- unsplash




Log in or sign up for Devpost to join the conversation.