-
-
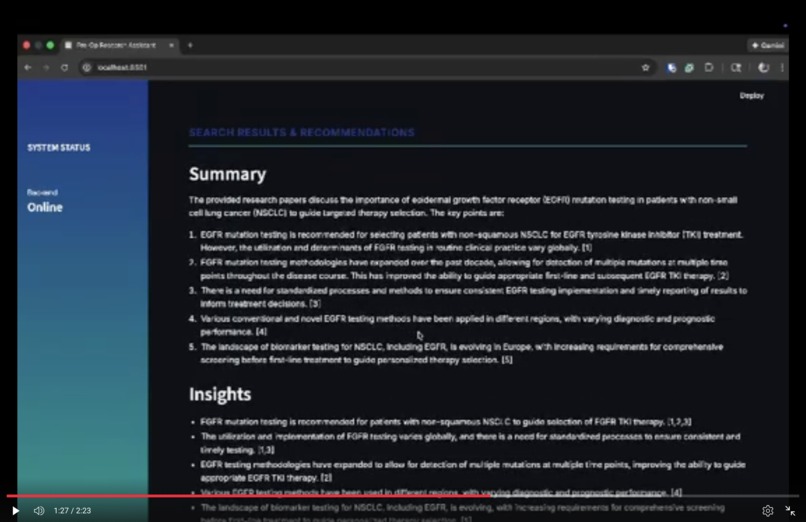
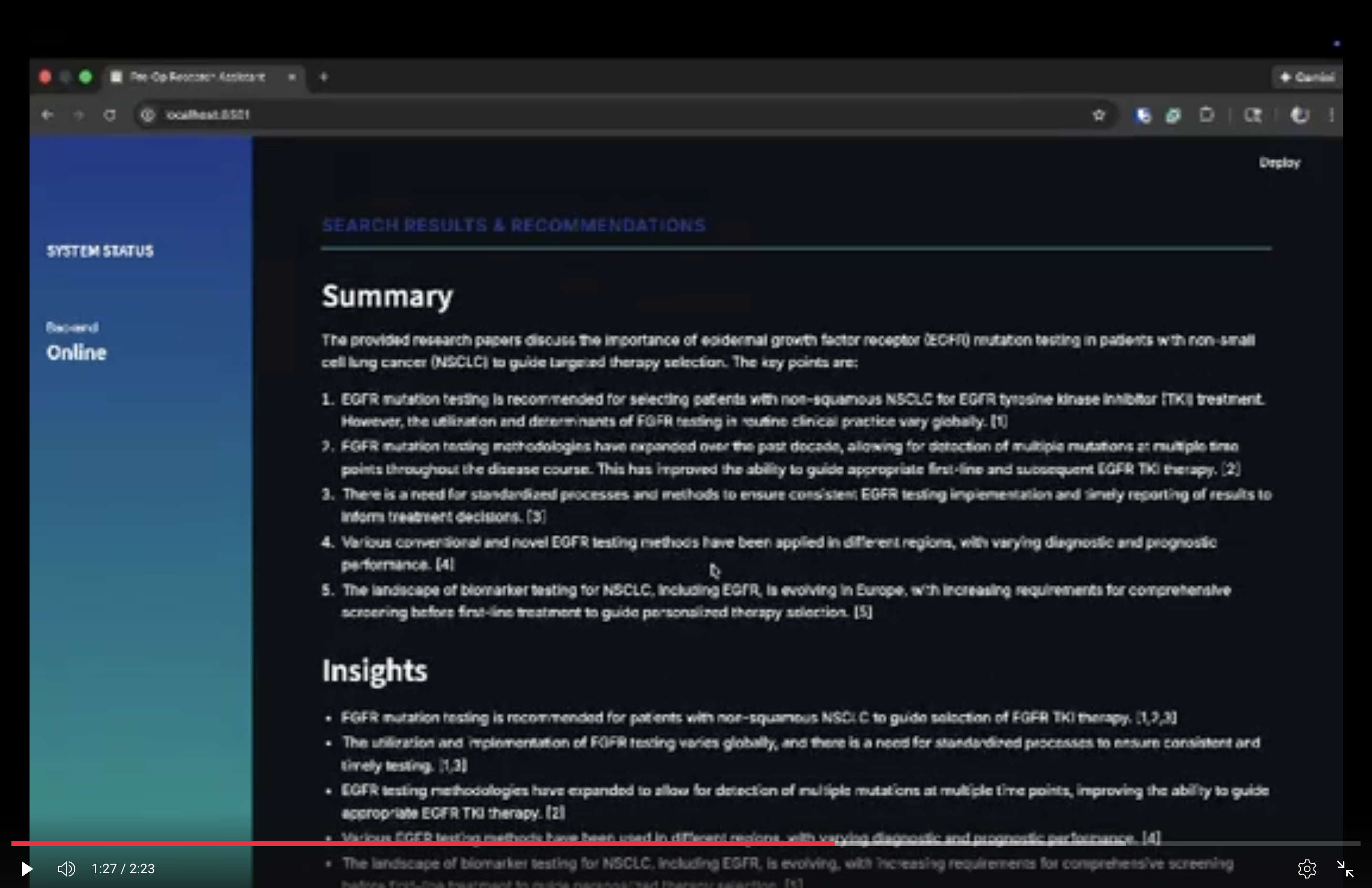
pre/post op summaries
-
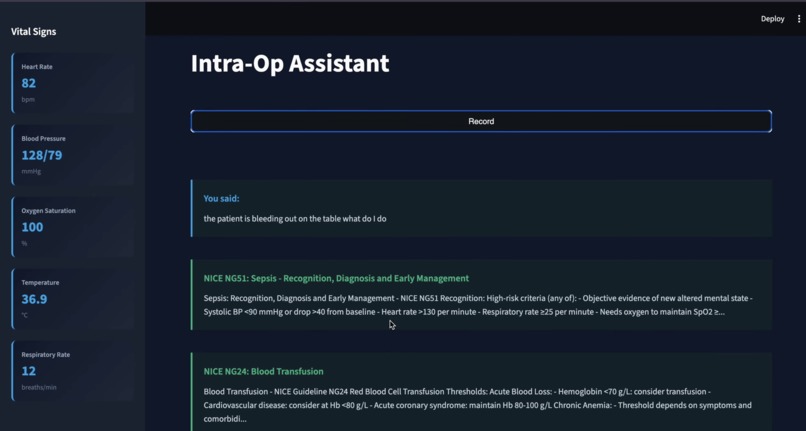
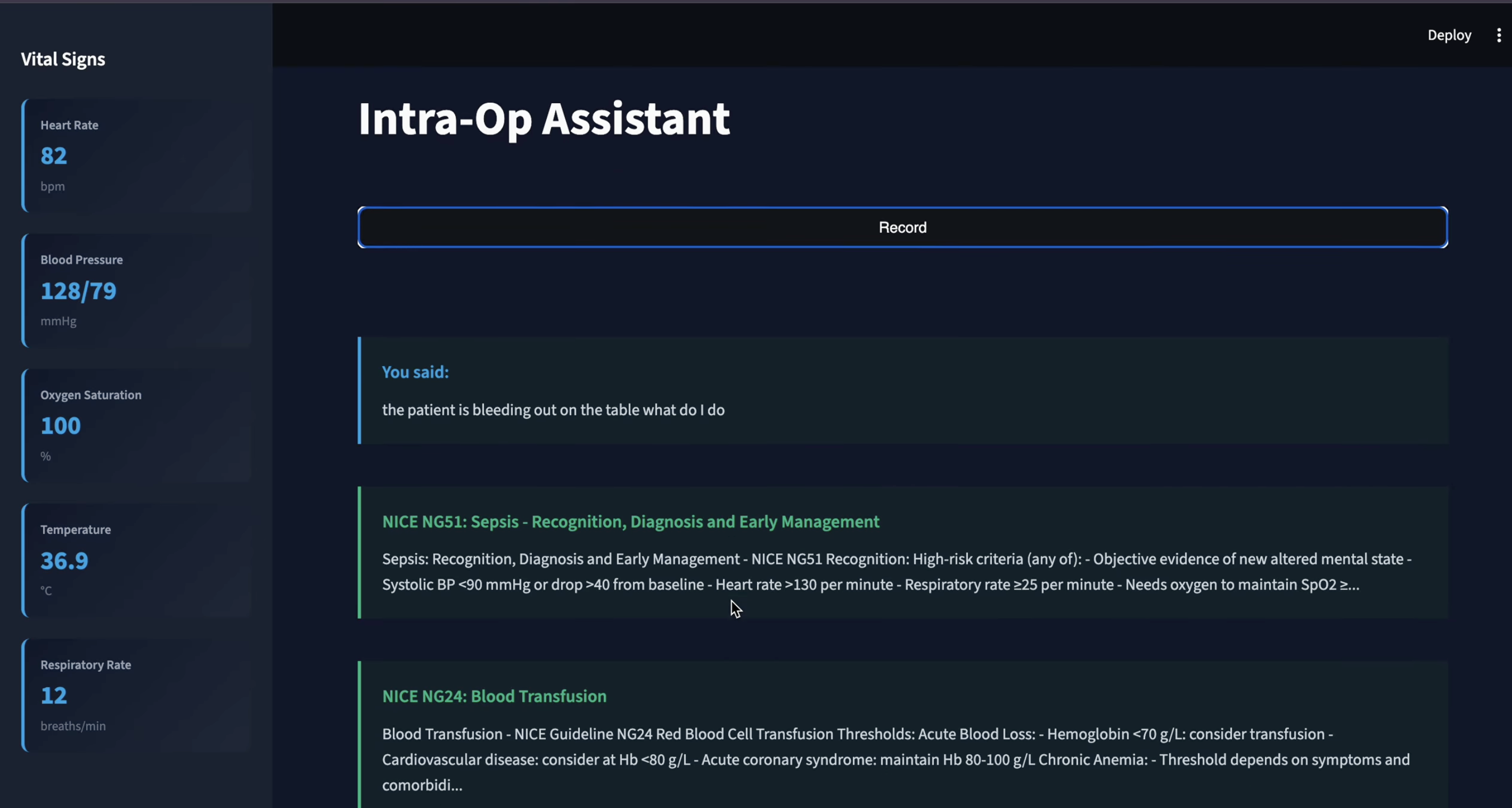
Intra-Op Guilelines
Inspiration
Currently, Surgeons spend hours and hours pre- and post-surgery combing methodically through the latest research looking for relevant papers and clinical trials to help with their surgeries. During the actual surgery, there's a lot of pressure on the surgeon to keep everything that's happening in mind and make life-saving decisions. We wanted to help ease that burden in a safe and helpful way
What it does
Pre- and post-surgery, it takes in patient data and does a search across a massive database of millions of PubMed articles and retrieves relevant ones for the surgeon to peruse. It includes direct links to the papers. During surgery, it answers questions in real-time using text-to-speech, so that the surgeon can use it without breaking the sterile field by touching buttons. It answers correctly based only on a fixed set of protocol documents provided to it.
How we built it
We built an end-to-end RAG pipeline from scratch. We built a vector database using FAISS, we created embeddings by quantizing PubMed paper and abstract vectors, engineered prompts, and integrated the entire pipeline to make sure the product is useful, but also reliable, given the severe consequences of hallucinations.
Challenges we ran into
Making sure the models only answered based on facts and not hallucinations. The data was very large, with millions of entries, and it was very difficult to handle on our commercial hardware. We had to rely on novel research techniques like product quantisation for storing our embeddings. Commands to build indexes took hours to run, which was tough given the time constraints. Also, with multiple stages to the project, we had to integrate a lot of different components together to make this work
Accomplishments that we're proud of
Getting it done on time. The models are reliable and perform well. They look professional and the response times are somehow pretty good, against all odds
What we learned
How difficult building an end-to-end RAG system is. We learned to appreciate why these optimization algorithms exist. We learned to leverage AI to help speed up our development. And we learned a lot of small, clever hacks to get things to work in a short timeframe
What's next for HolyGrail.ai
Scalability and performance. This could scale to larger speech times, more information in the database, etc. We could use better models, maybe finetuned for this specific use case
Built With
- claude-api
- faiss
- gcp
- openai
- python
- streamlit

Log in or sign up for Devpost to join the conversation.