-
-
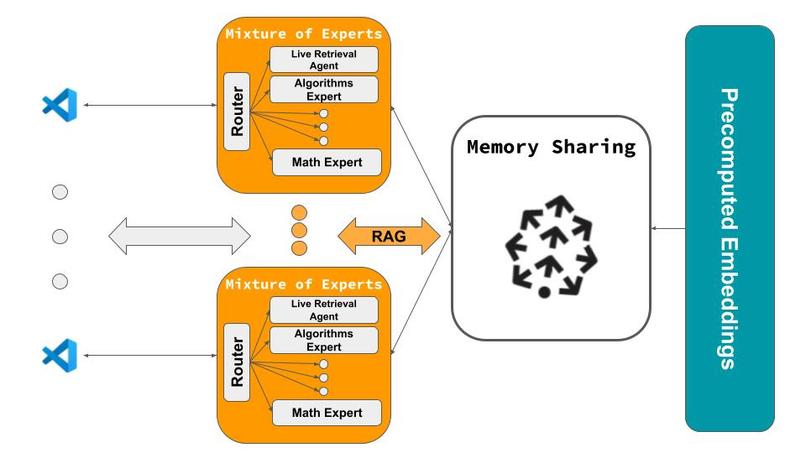
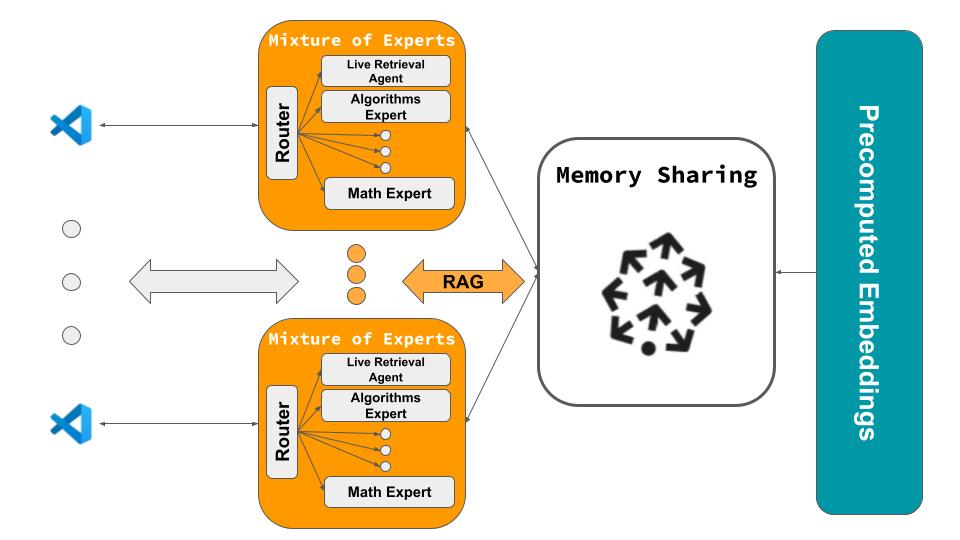
Architecture for HiveMind
-
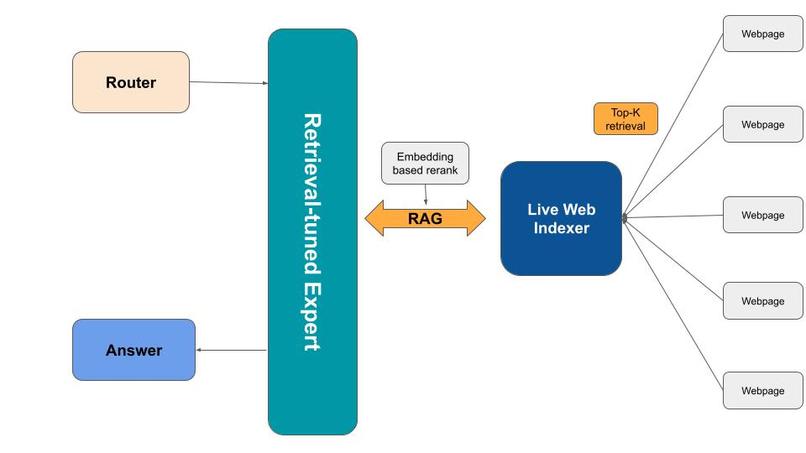
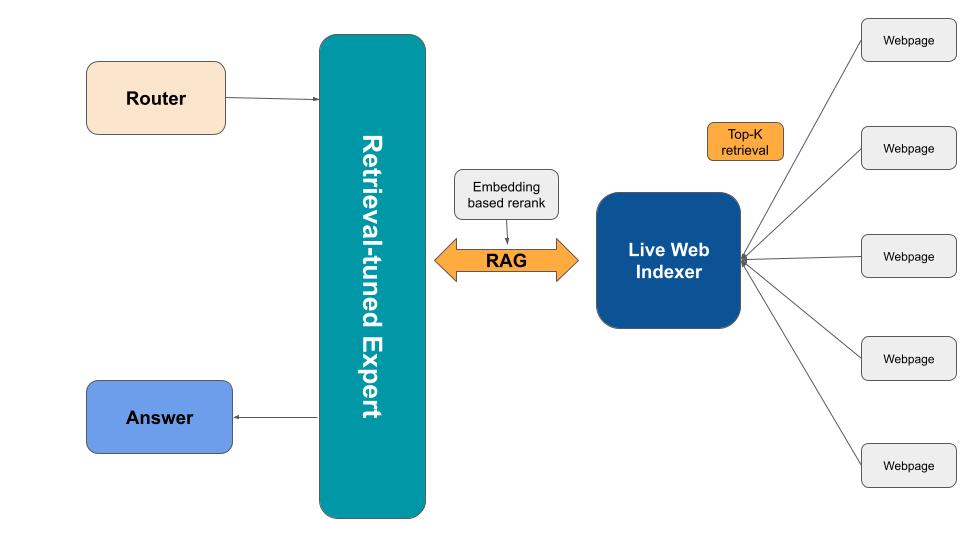
Mixture of Experts Framework in HiveMind with OpenAI swarm
-
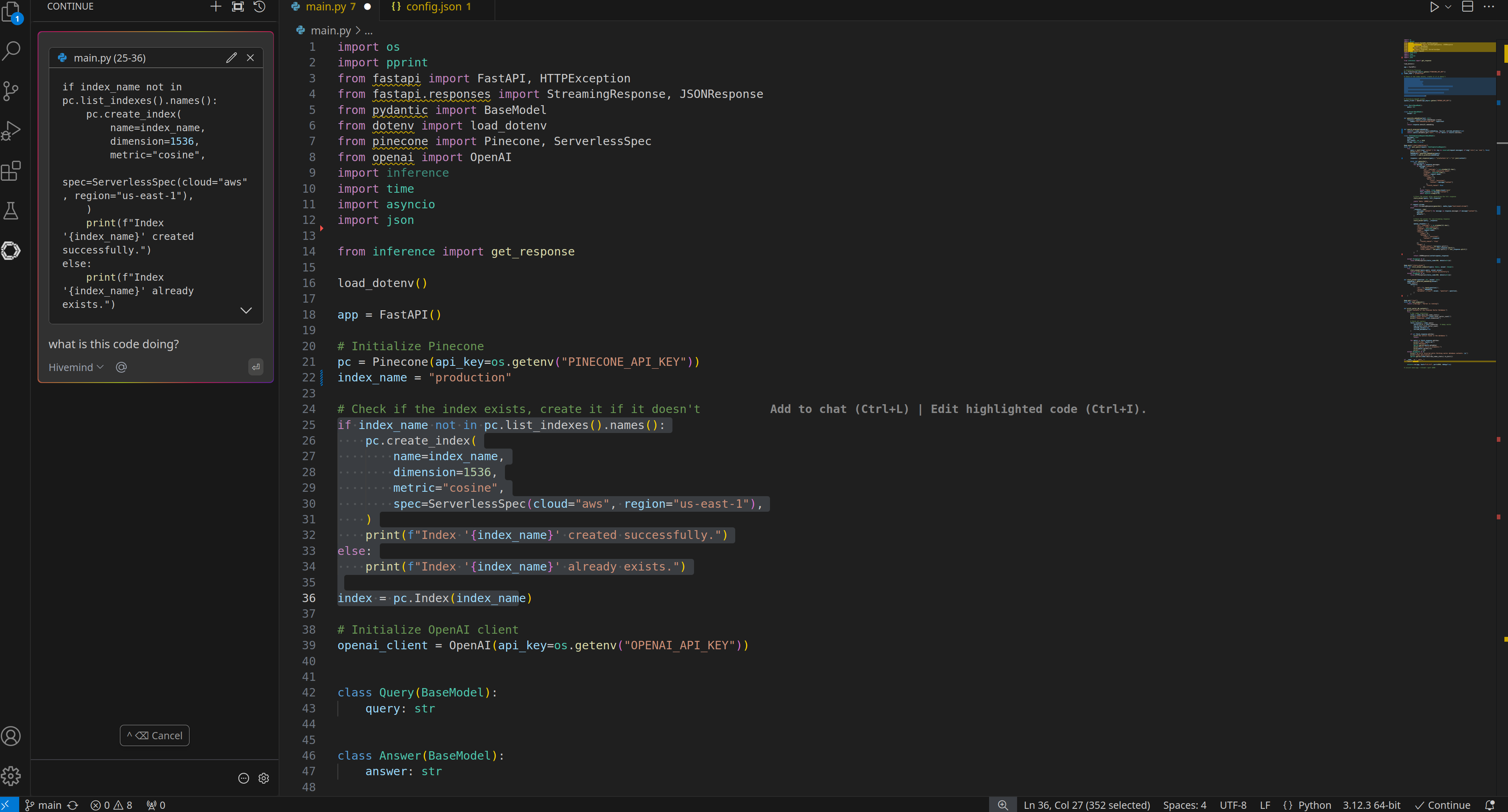
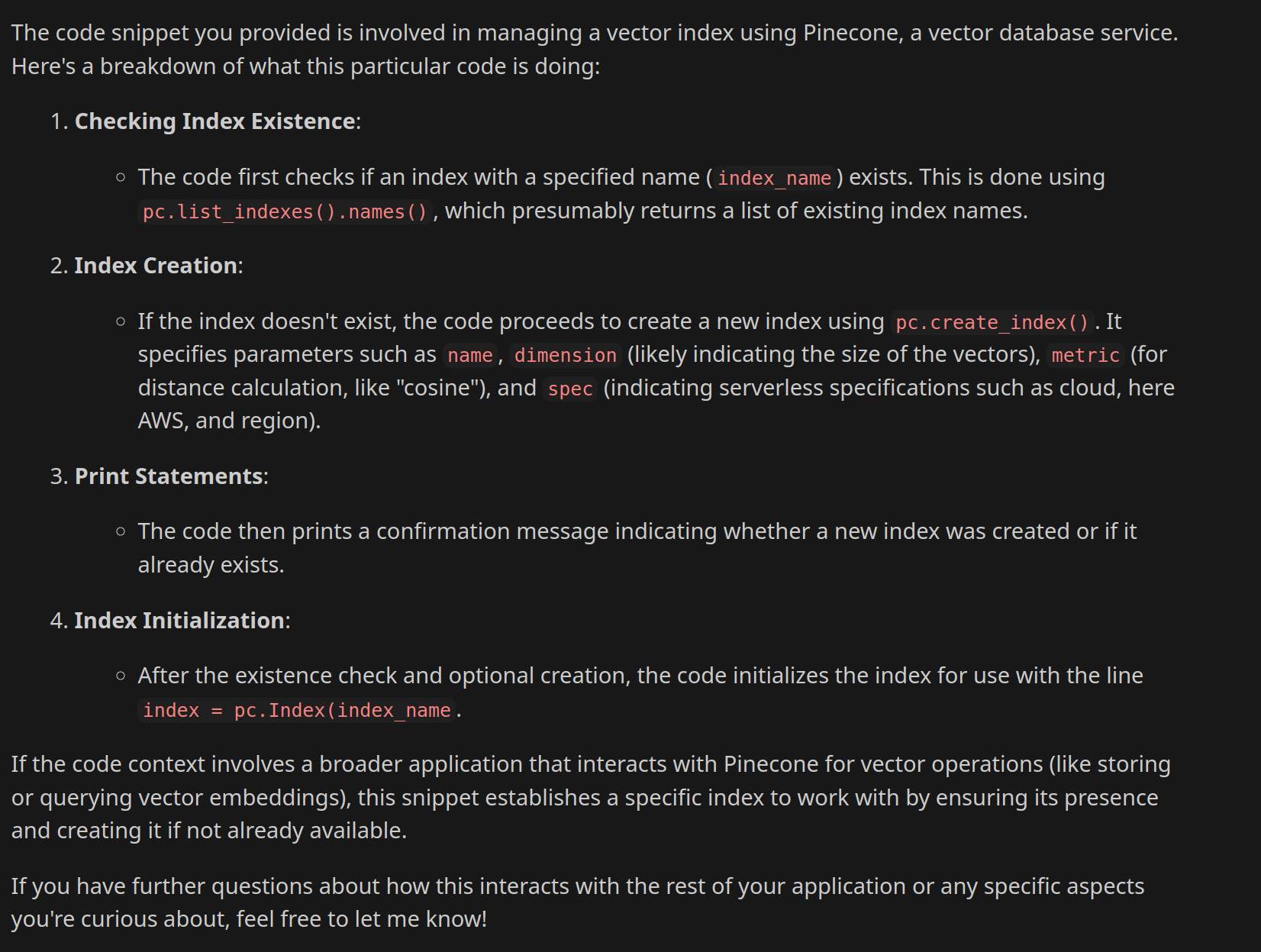
Question asked about Pinecone vector database to HiveMind
-
Output from HiveMind
AI Code Editor with Memory Sharing
Inspiration
The inspiration for this project came from the fast-paced startup environment, where quick access to insights and seamless knowledge sharing are essential. While version control tools like Git handle code management, they often miss capturing the discussions and problem-solving that happen in real-time. This gap inspired us to build an AI-driven code editor that enables users to share their interactions with AI agents across a team, helping everyone learn and solve problems faster.
The idea was to combine AI’s problem-solving capabilities with a memory-sharing system that captures the interactions, making collaboration smoother. We also saw the potential in combining multiple specialized AI models to further improve productivity.
What I Learned
Throughout this project, I learned a lot about integrating complex AI systems and managing shared memory. Key lessons include:
- RAG (Retrieval-Augmented Generation) Implementation: Leveraging Pinecone as a vector database taught me the importance of fast and relevant data retrieval. This was crucial for enhancing the LLM’s ability to provide context-aware responses.
- Orchestrating Multiple LLMs: Combining different LLMs for specialized tasks via OpenAI swarm was an exciting challenge. Each model had to be orchestrated efficiently to ensure the system worked cohesively.
- Tool Integration: One of the biggest takeaways was learning how to integrate complex AI systems into existing platforms—in this case, Continue, an open-source alternative to Cursor.
How We Built It
We built this project by integrating several advanced AI tools and platforms:
- Continue (Open-Source Cursor Alternative): We began by building on top of Continue, which provided the foundation for our AI Code Editor. This allowed us to focus on adding custom features like memory sharing and advanced AI interactions.
- LLM Inference with RAG: A new LLM inference endpoint was developed to support Retrieval-Augmented Generation (RAG). Using Pinecone as our vector database, we enhanced the AI’s ability to recall relevant information from memory, improving context-based responses.
- LLM Orchestration with OpenAI Swarm: We orchestrated multiple large language models to handle various tasks—from code completion to web scraping. Each agent was specialized for a particular role, and their outputs were combined to provide users with accurate and comprehensive results.
- Memory Sharing: The core of the project is a shared memory system that allows team members to access insights generated through interactions with AI. This system was built to be real-time, scalable, and secure.
Challenges We Faced
The biggest challenges we encountered were related to integrating our LLM inference backend into Continue. It required careful planning to ensure that the backend worked seamlessly within the existing framework while maintaining performance. Specific challenges included:
Built With
- openai
- pinecone
- python
- typescript

Log in or sign up for Devpost to join the conversation.