Inspiration
AI agents reach production faster than anyone can govern them. One loop left alone can burn a budget overnight. One bad write can wipe a database. A long task can fail with no record of why. So teams either babysit their agents or keep them out of production. We wanted the opposite. A swarm you can trust to run, because you can see everything it does, stop it mid-run, and check exactly why it acted. The idea that started HIVE was simple. If the database is the message bus, then an agent writing its result is the broadcast. So the thing that runs the swarm and the thing that shows it to you can be the same thing.
What it does
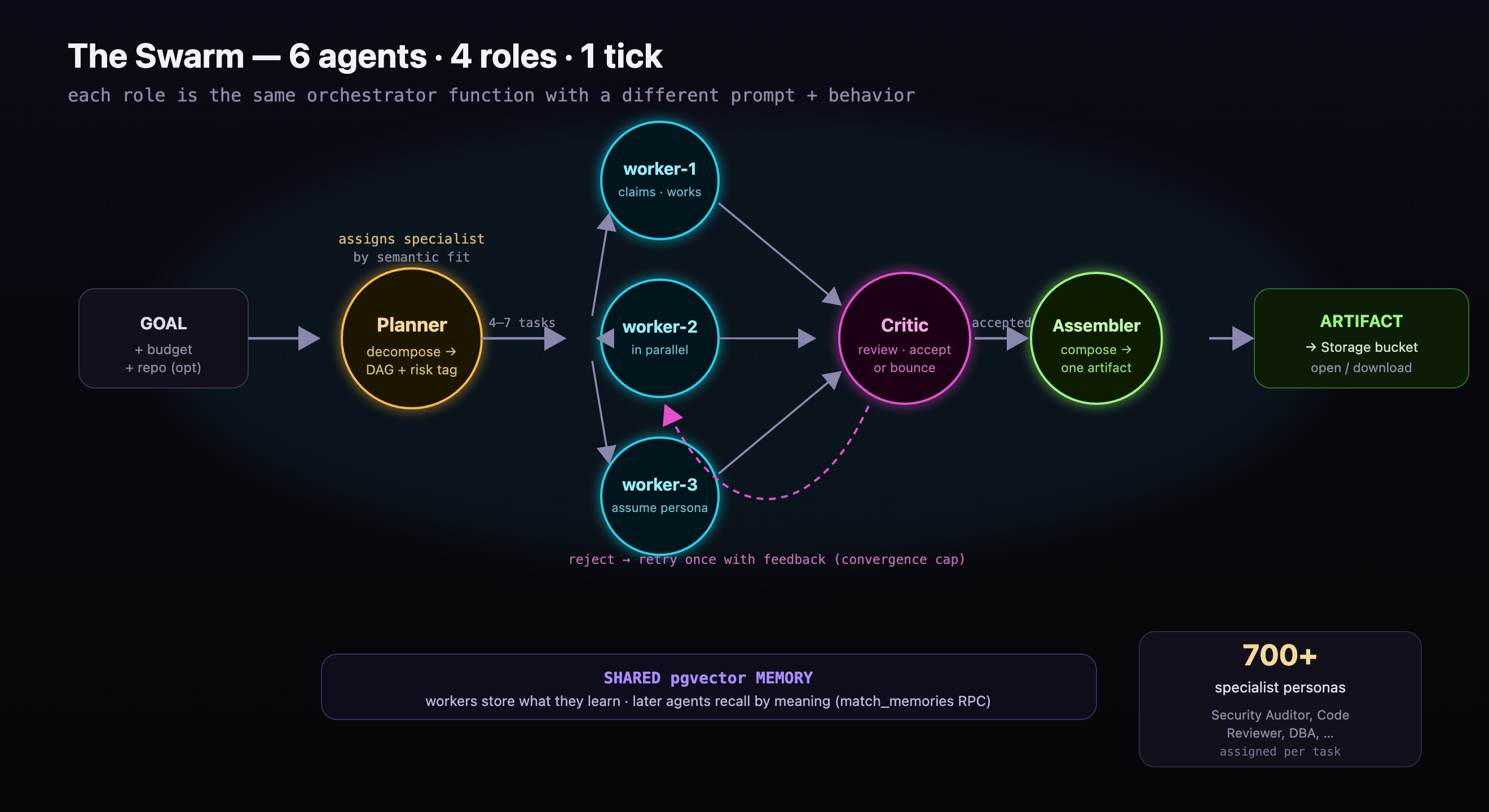
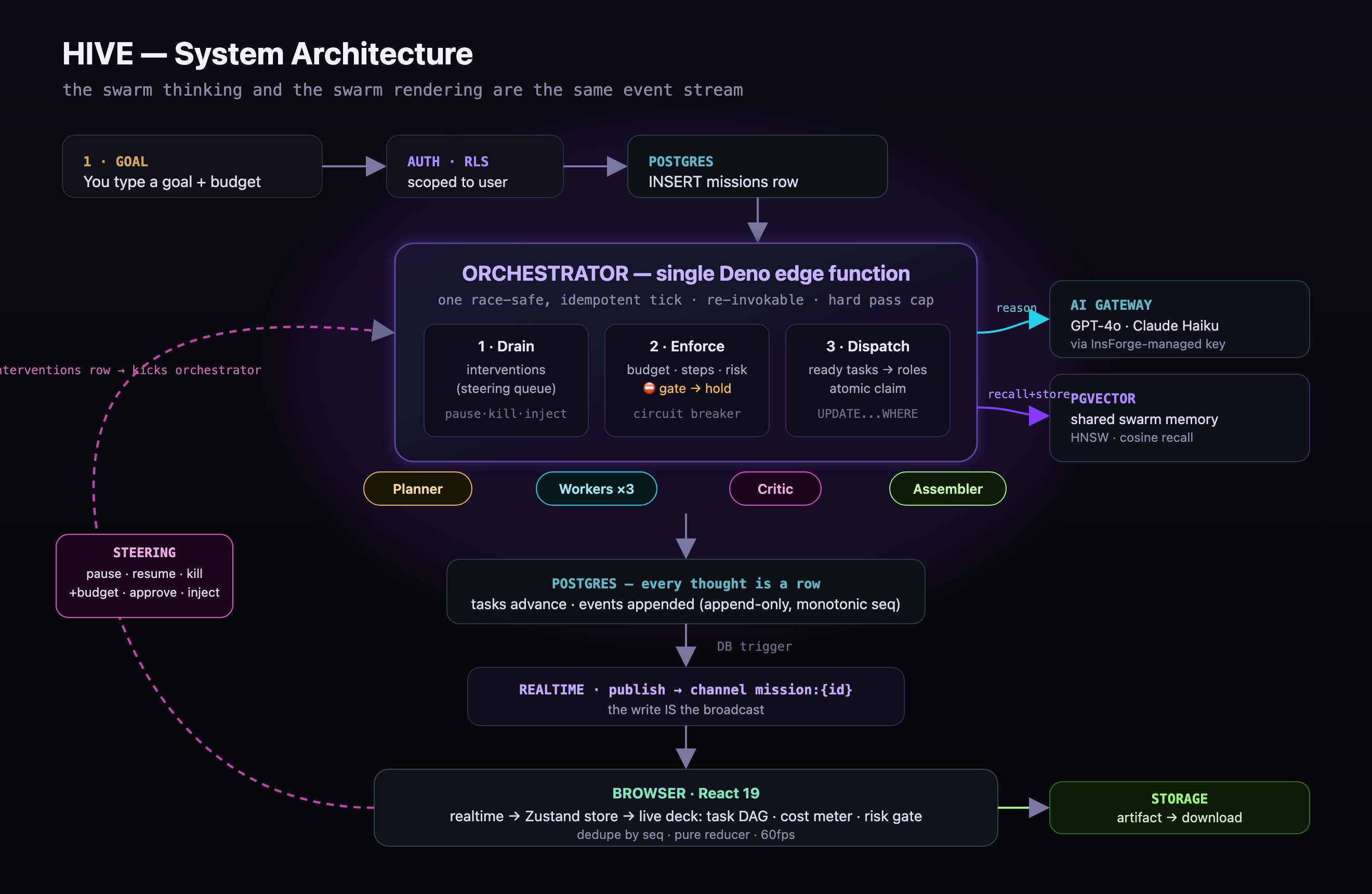
You give HIVE a goal, or point it at a GitHub repo. A planner agent breaks it into a task graph and assigns each task a specialist from a catalog of 700+ expert personas. Worker agents pick up ready tasks in parallel, recall relevant memories from a shared vector store, reason through an AI gateway, and write results. A critic reviews every result and can send weak work back for one retry. An assembler combines the accepted outputs into a finished, downloadable file.
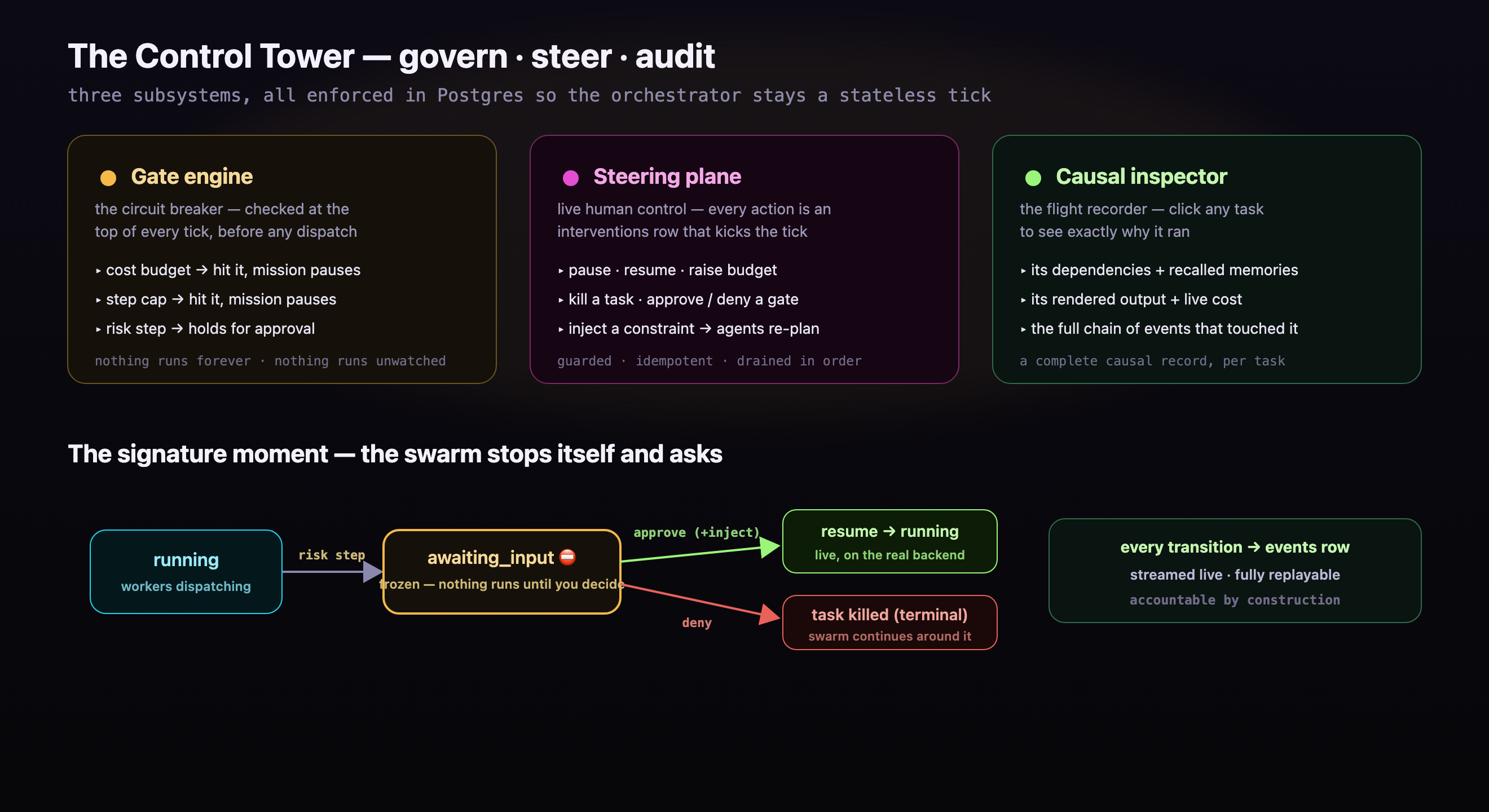
The whole run is governed and steerable:
- A live cost meter and step counter, measured per task.
- Hard gates: a budget cap, a step cap, and a risk gate on the one high-impact step. All are enforced in the backend before any work runs. Trip one and the swarm pauses and asks you.
- Live steering: pause, resume, raise the budget, kill a task, approve or deny a gated step, or inject a constraint the agents plan around. All of it works mid-run.
- A causal inspector: click any task to see why it ran, what it produced, and what it cost.
How we built it
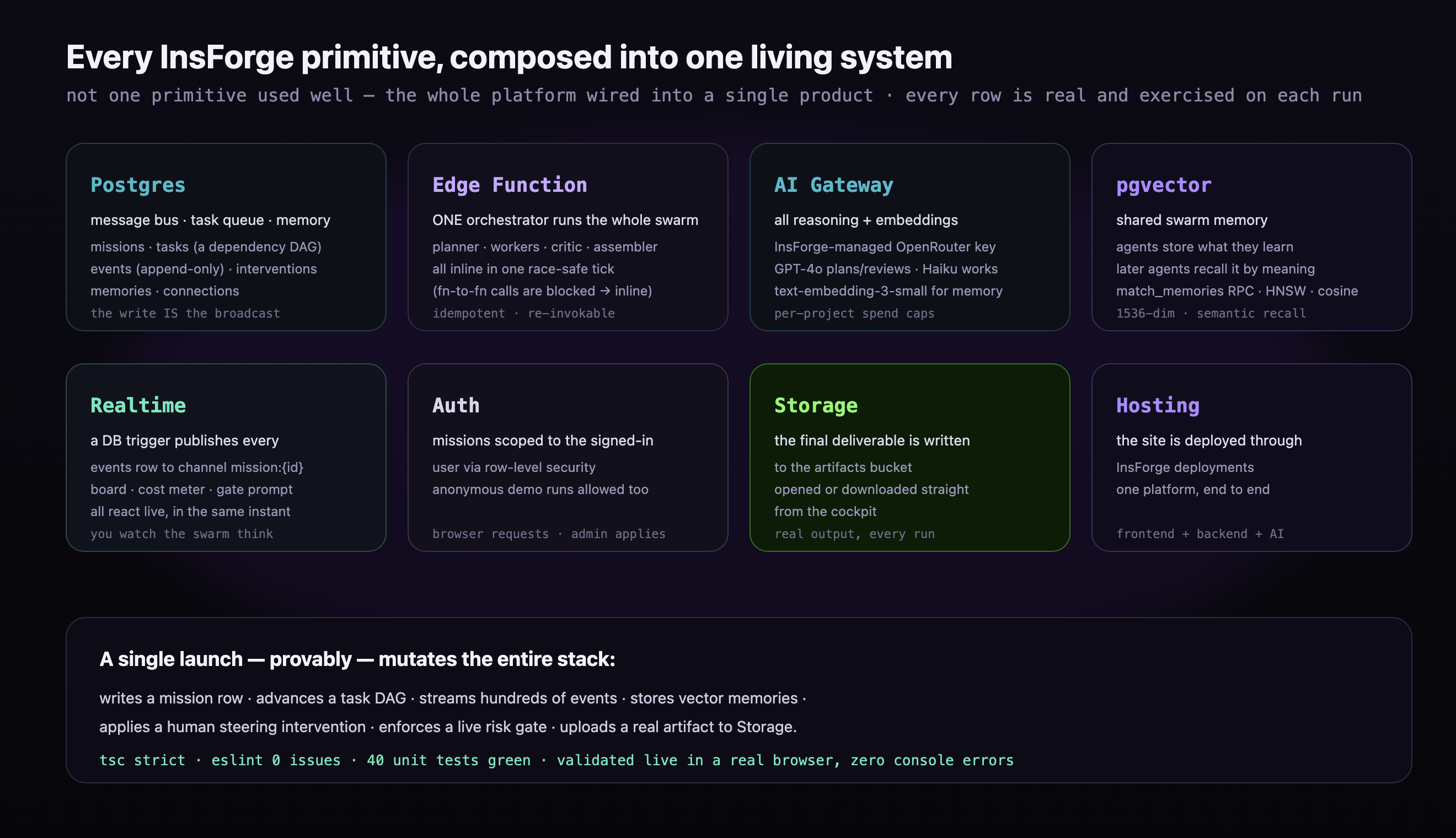
HIVE runs entirely on InsForge, and it uses every part of the platform.
- Postgres is the message bus, task queue, and memory. It holds missions, the tasks graph, an append-only events log, vector memories, and a steering queue.
- One edge function, the orchestrator, runs the whole swarm in a single safe tick. Every change is a guarded atomic update, so re-running it never double-does work and two ticks never collide.
- The AI gateway, an InsForge-managed OpenRouter key with per-project spend caps and usage logging, powers all reasoning and embeddings. GPT-4o plans, reviews, and assembles. Claude 3.5 Haiku does the work.
- pgvector is the shared memory. Agents store what they learn and later agents recall it by meaning.
- Realtime carries the live updates. A database trigger publishes every events row to a per-mission channel, and a Zustand store on the client turns them into the live deck.
- Auth scopes missions to the user, Storage holds the final artifact, and the site is hosted on InsForge.
The frontend is React 19, Vite, and TypeScript with a custom dark design system (Space Grotesk and Geist Mono, role-colored agents, glass cards, smooth motion). The backend connects through a thin adapter, so the UI is just a window onto real backend state.
Challenges we ran into
- InsForge blocks function-to-function calls with HTTP 508. Our first design called a separate worker function. When we hit the 508, we put every role inline in one safe tick. It came out simpler and faster.
- Getting the AI gateway right. The older project /v1 endpoint is deprecated. The current way is to call OpenRouter directly with an InsForge-managed key that carries the per-project spend cap. So the spend you see in the cost meter is real and capped by the platform.
- Making realtime the architecture, not a feature. A trigger that publishes every events row means oversight is not bolted on the side. The swarm doing the work and the swarm showing up on screen are the same stream of events.
Accomplishments that we're proud of
- The whole InsForge platform working together as one product, not one feature used well.
- A safe, repeatable, gated tick orchestrator with per-step cost tracking, pgvector recall, and a critic that holds a high bar without looping forever.
- Agents you can trust in production. A single launch changes the whole stack: a mission row, a task graph, hundreds of events, vector memories, a human steering action, and a real file in Storage.
What we learned
- When the database is the broadcast, watching the system stops being a separate job and becomes the architecture.
- Governance, meaning budgets, gates, steering, and a record of why, is the missing piece that makes production agents usable. It is more convincing than another autonomous demo.
What's next
- More than one person steering the same mission at once.
- Bringing back the live browser research tool so workers can read real pages mid-mission.
- Replay and branch: fork a past mission from any point with a new constraint.
Built With
- claude-3.5-haiku
- deno
- edge-functions
- gpt-4o
- insforge
- openrouter
- pgvector
- postgresql
- react
- realtime
- three.js
- typescript
- vite
- zustand


Log in or sign up for Devpost to join the conversation.