-
-
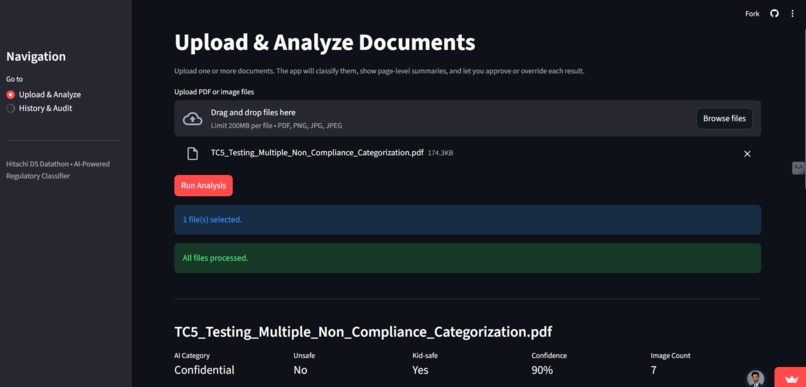
App in Action!

Inspiration
Regulatory and compliance documents are often long, unstructured, and written in mixed formats (text + scanned images). Teams waste hours classifying them manually to meet data-handling policies. We wanted to build an AI-powered system that can instantly identify if a document is Public, Confidential, Highly Sensitive, or Unsafe — and still be explainable and auditable for enterprise use.
What it does
RegDoc automatically analyzes multi-page PDFs and image documents and classifies them into four categories:
Public — brochures, press releases Confidential — internal memos, equipment details Highly Sensitive — PII like SSNs or credit cards Unsafe — explicit or illegal content
It performs OCR, PII detection, LLM-based reasoning, and policy enforcement before presenting the result in an interactive Streamlit dashboard with evidence citations and reviewer feedback (HITL).
Live Demo: https://regdoc.streamlit.app
How we built it
Backend: Python (pdfplumber, pytesseract, Pillow) LLM Engine: OpenRouter with Meta-LLaMA 3.1 (8B + 70B Instruct) Prompt Library: Dynamic JSON-based prompt trees for domain-specific reasoning Frontend: Streamlit app for uploads, summaries, and human overrides Storage: JSON audit log tracking reviewer decisions and confidence scores Deployment: Streamlit Cloud
The pipeline merges deterministic rule-checks (e.g., PII, unsafe terms) with probabilistic LLM reasoning for explainable results.
Challenges we ran into
Extracting clean text from scanned, multi-modal PDFs Balancing speed vs. accuracy between 8B and 70B models Designing prompt templates that adapt to both text and images Managing OpenRouter rate limits during batch testing Implementing a consistent confidence-threshold workflow for HITL
Accomplishments that we're proud of
What we learned
How to design AI Agents using LLM pipelines that are auditable and policy-driven The importance of confidence calibration for human oversight How to use OpenRouter’s model ecosystem effectively for scalable reasoning Why clear UI feedback loops are crucial for trust in AI decisions
What's next for Hitachi Challenge
Fine-tune the LLM on real regulatory corpora Extend support for multi-language OCR and image segmentation Add continuous learning from reviewer feedback Integrate with enterprise document systems (SharePoint, Confluence, etc.) Publish a whitepaper on explainable document classification for compliance AI





Log in or sign up for Devpost to join the conversation.