-
-
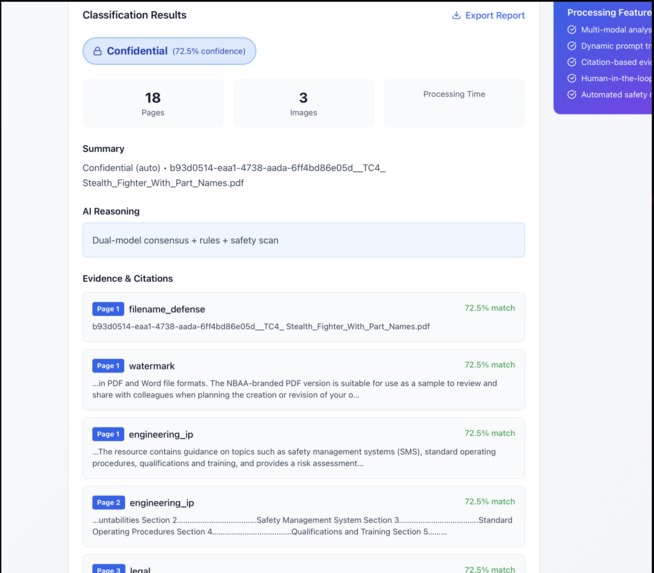
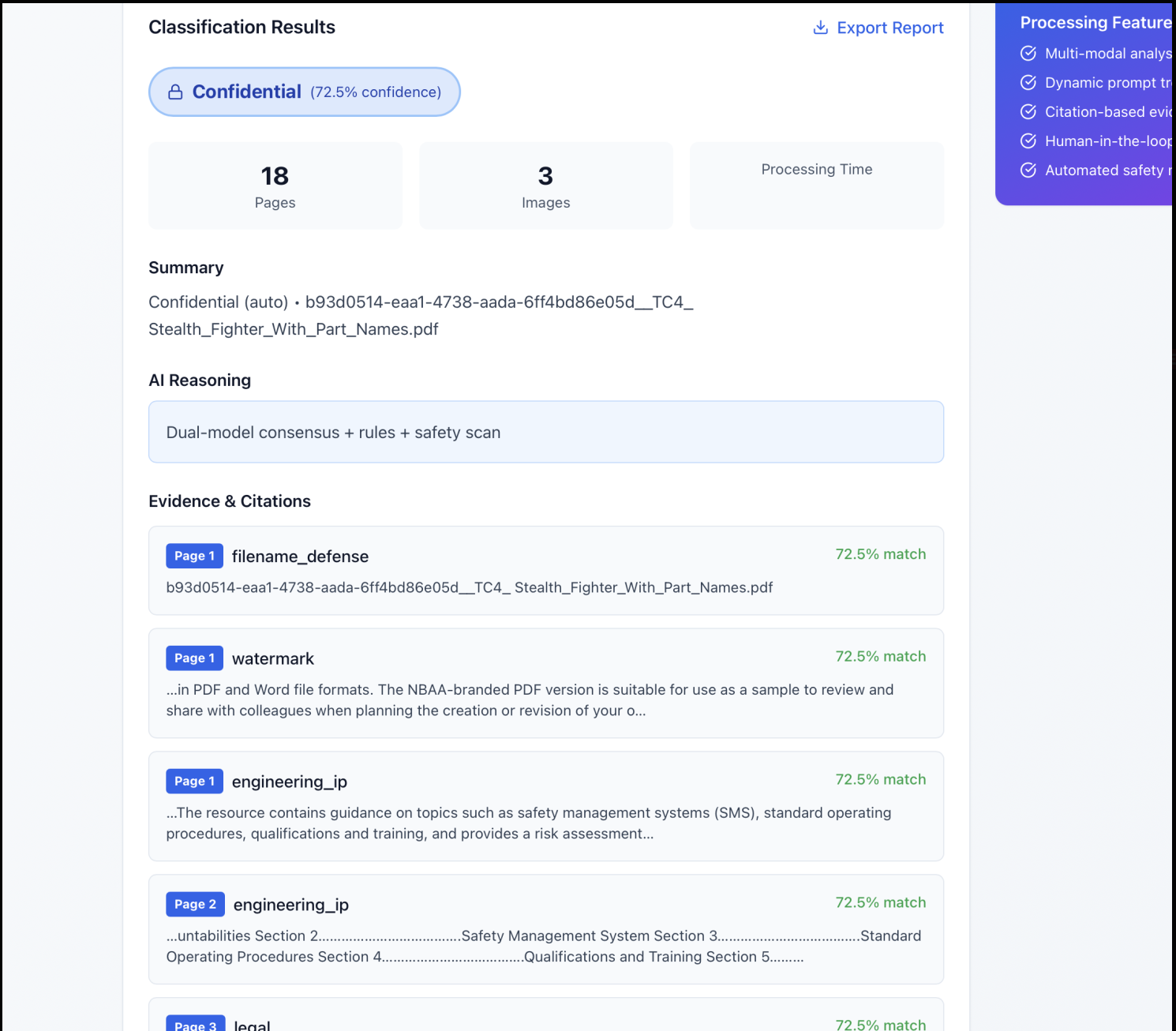
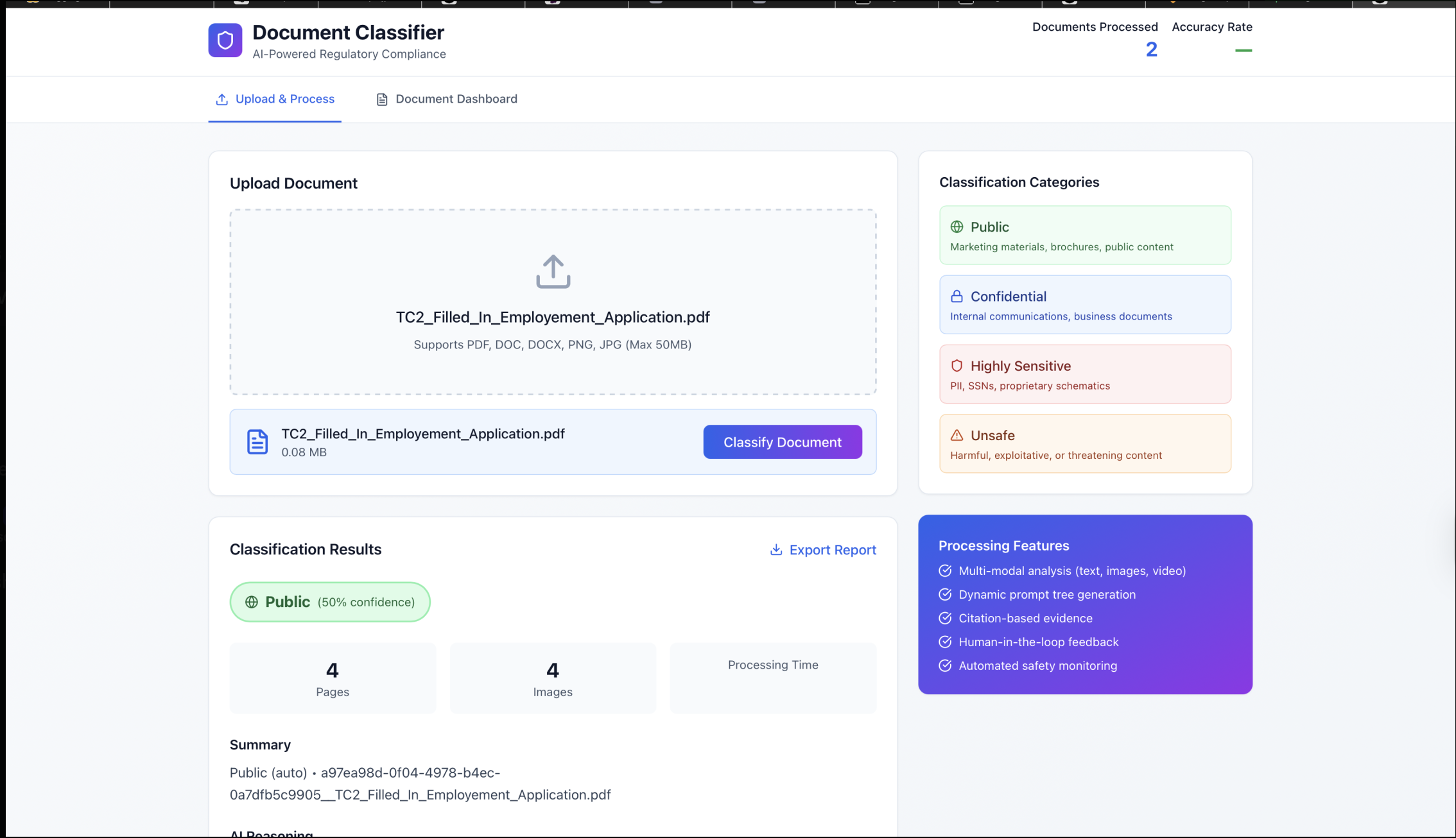
This shows the classification results along with additional information about the uploaded file.
-
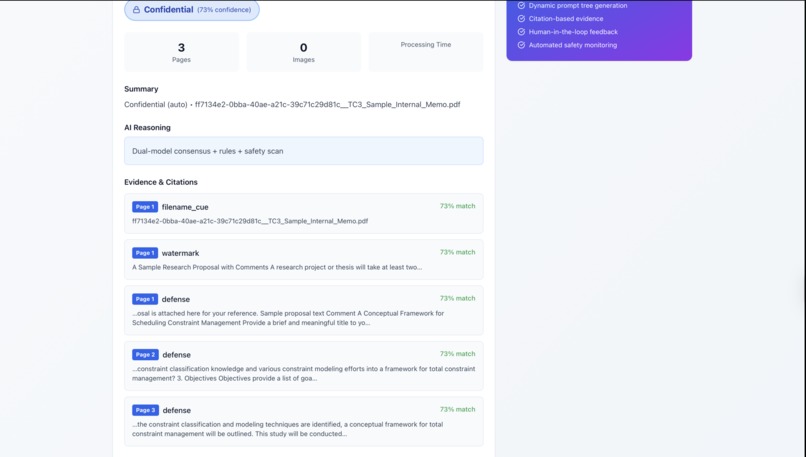
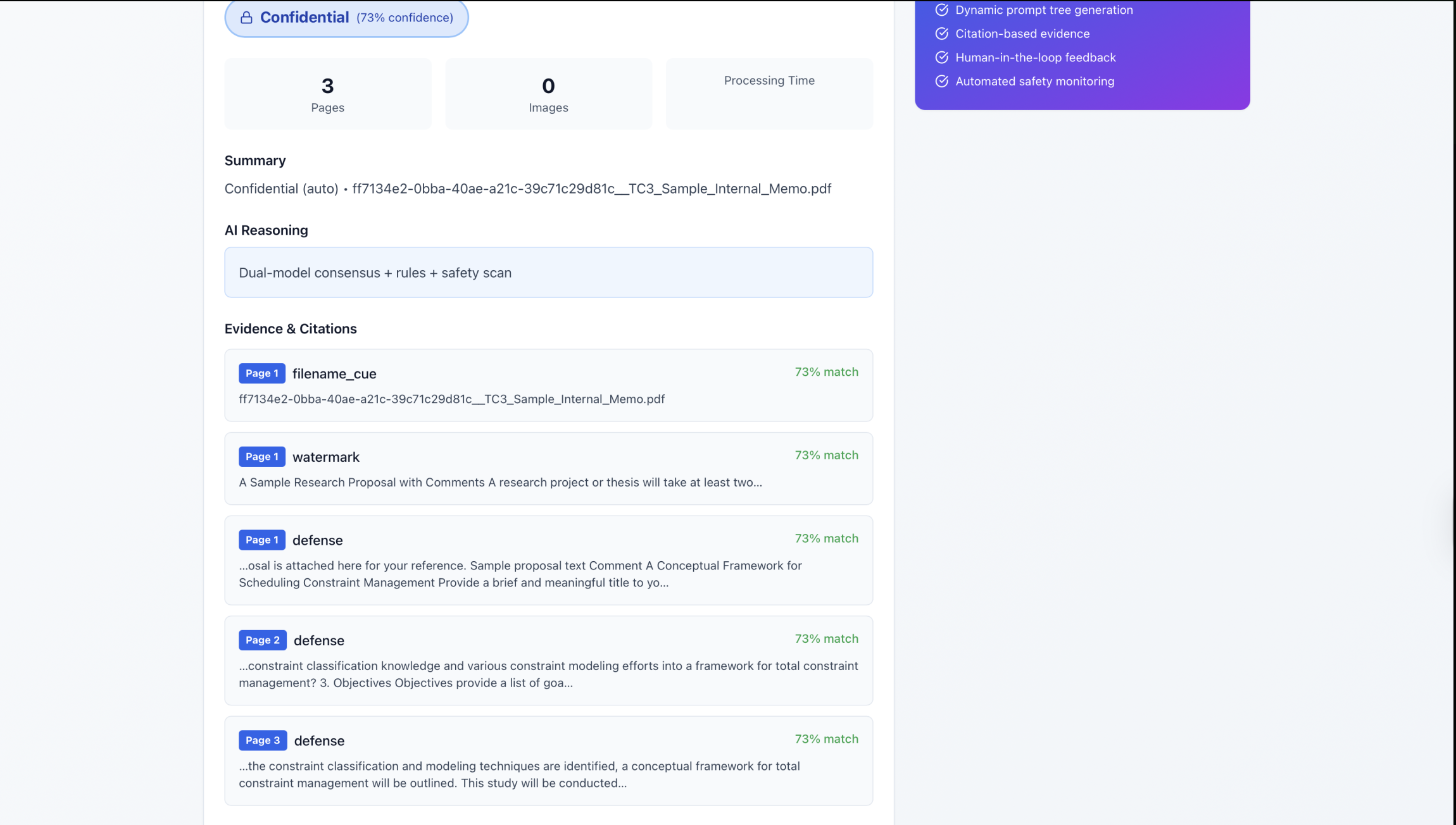
This showcases the evidence and citations behind the classification result.
-
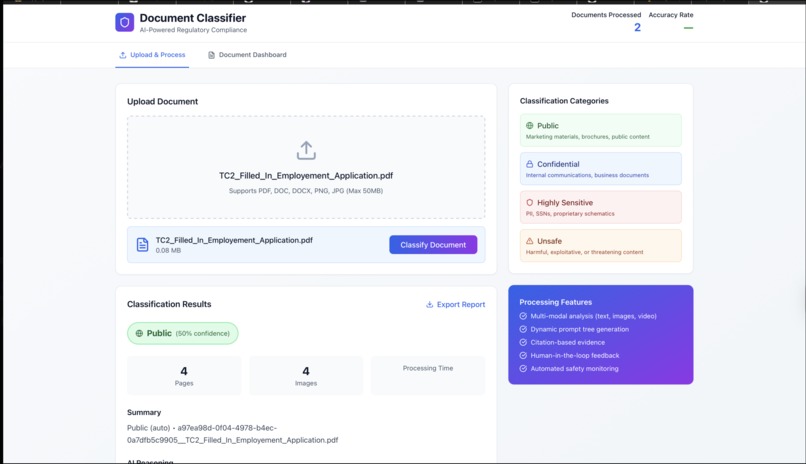
This where the user can upload their document.
-

This shows the confidence level for the file, date, and the need for review.

Inspiration
In regulated industries, teams deal with massive volumes of unstructured documents such as contracts, designs, reports, and images that often contain sensitive data. Manually labeling and reviewing each one for compliance is slow, inconsistent, and risky. Our team wanted to build a system that automatically understands documents like a human reviewer would, reading both text and images, identifying confidential or unsafe content, and explaining why it reached its decision with traceable citations. The goal was to reduce human effort while maintaining high compliance, confidence and transparency.
What it does
Hitachi Compliance Bot classifies any uploaded document (PDF, Image, or Word file) into one of four categories: Public, Confidential, Highly Sensitive, or Unsafe. The bot runs preprocessing checks (page count, image ratio, and legibility), and builds a dynamic prompt tree tailored to each file type, using AI reasoning pipeline to analyze content. It flags unsafe materials like hate speech or violent content, and detects PII such as SSNs or credit card numbers, and produces page-level citations that explain its reasoning. A Human-in-the-Loop (HITL) feature lets subject matter experts review low-confidence or flagged cases to improve accuracy over time.
How we built it
We built the entire solution using Python for both the frontend and backend to maintain a unified development environment. The backend, powered by FastAPI, handles document uploads, preprocessing, and classification. It connects directly to our custom-built agent.py file, which uses LangGraph to create a dynamic state graph for processing documents through multiple stages which include modality detection, policy evaluation, consensus classification, and human-in-the-loop validation. The agent extracts text from PDFs, DOCX files, and images using tools like pdfplumber, python-docx, and pypdf, while also detecting sensitive content such as PII, defense terms, and unsafe language. The frontend provides a clean and interactive interface for users to upload documents, view live processing updates, and review classification reports. We designed it to display results with clear visual cues, confidence scores, and citation-based evidence for audit and compliance transparency.
Challenges we ran into
One of the biggest challenges we faced was achieving accurate and reliable confidence scoring for each classification. Since our system uses multiple evaluation layers including rule-based detection, unsafe content checks, and dual-model consensus it was difficult to calibrate confidence values that truly reflected how certain the AI was about a document’s category. Early on, the confidence scores fluctuated heavily depending on document type, especially between text-based and image-based files. We had to fine-tune the scoring logic so that both models contributed meaningfully while still allowing the human-in-the-loop system to intervene when confidence dropped below a threshold.
Built With
- fastapi
- langgraph
- next.js
- python
- typescript
- uvicorn


Log in or sign up for Devpost to join the conversation.