-
-
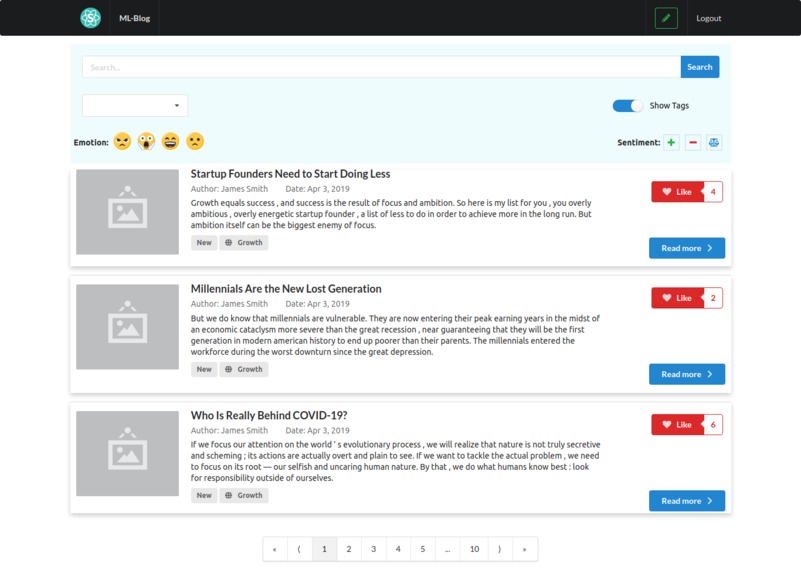
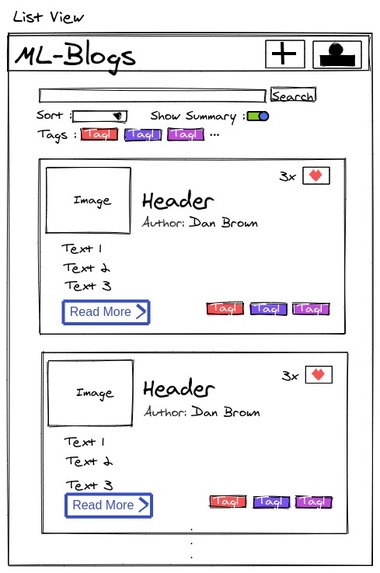
Main Page
-
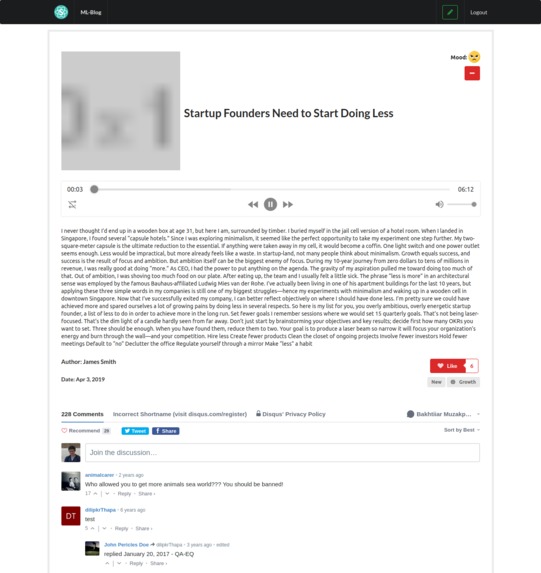
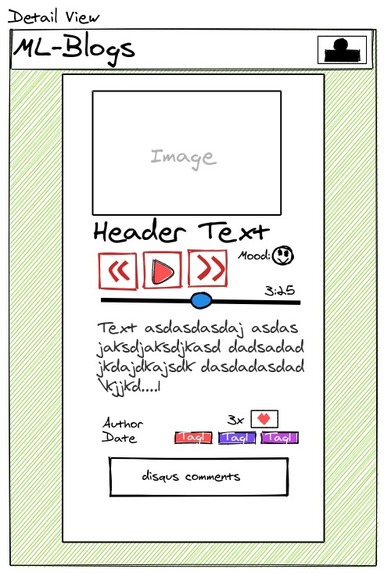
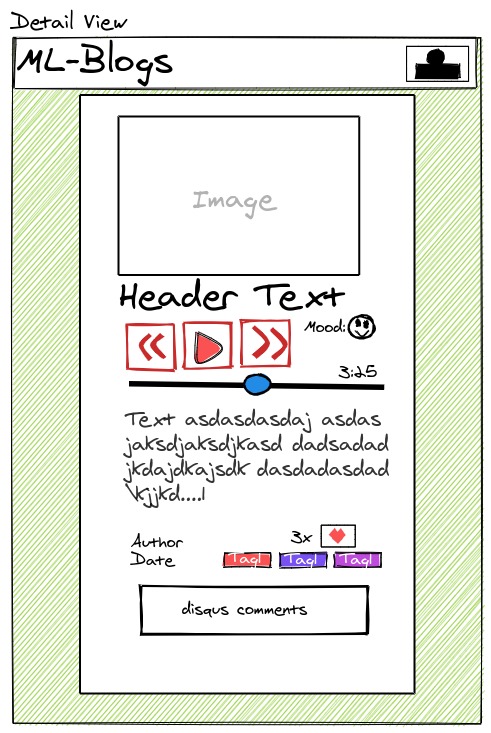
Detail Page
-
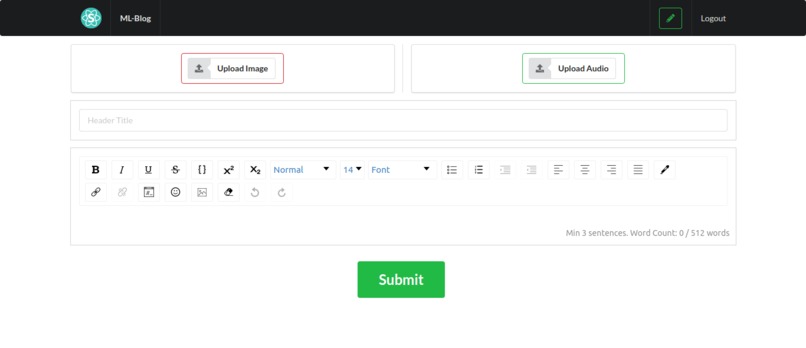
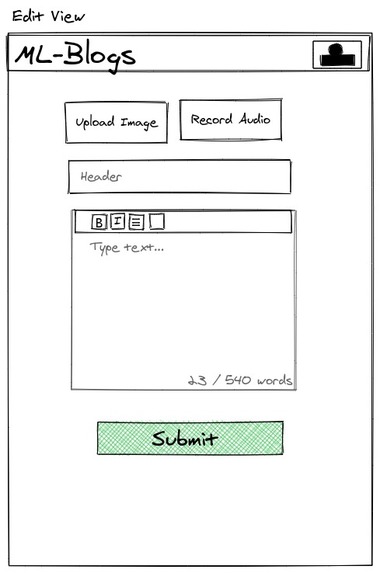
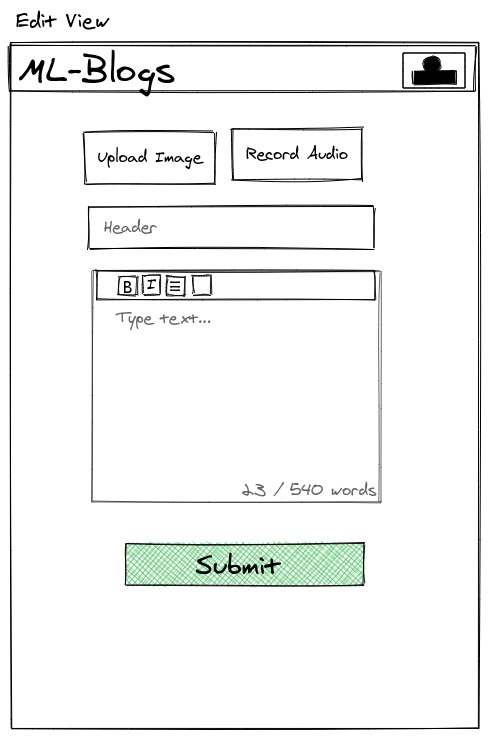
Editor
-
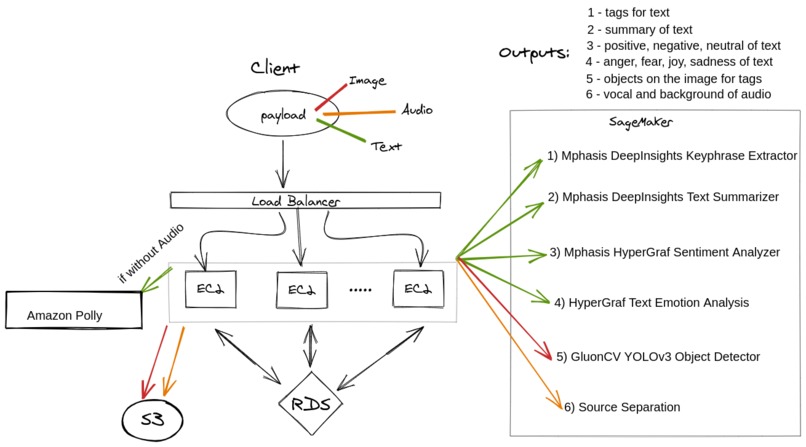
behind the scenes
-
ML-Blog designs
-
ML-Blog designs
-
ML-Blog designs
-

logo
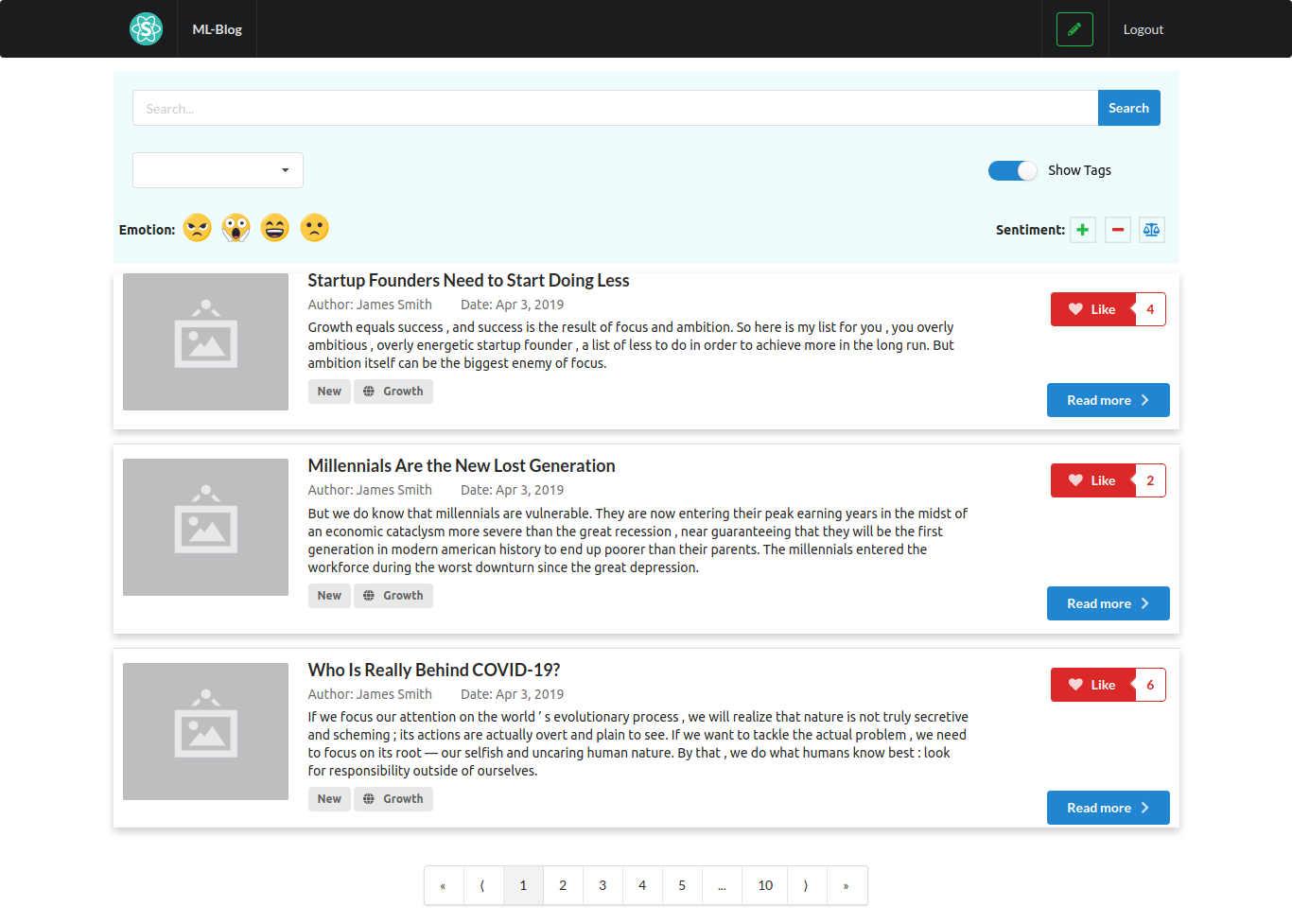
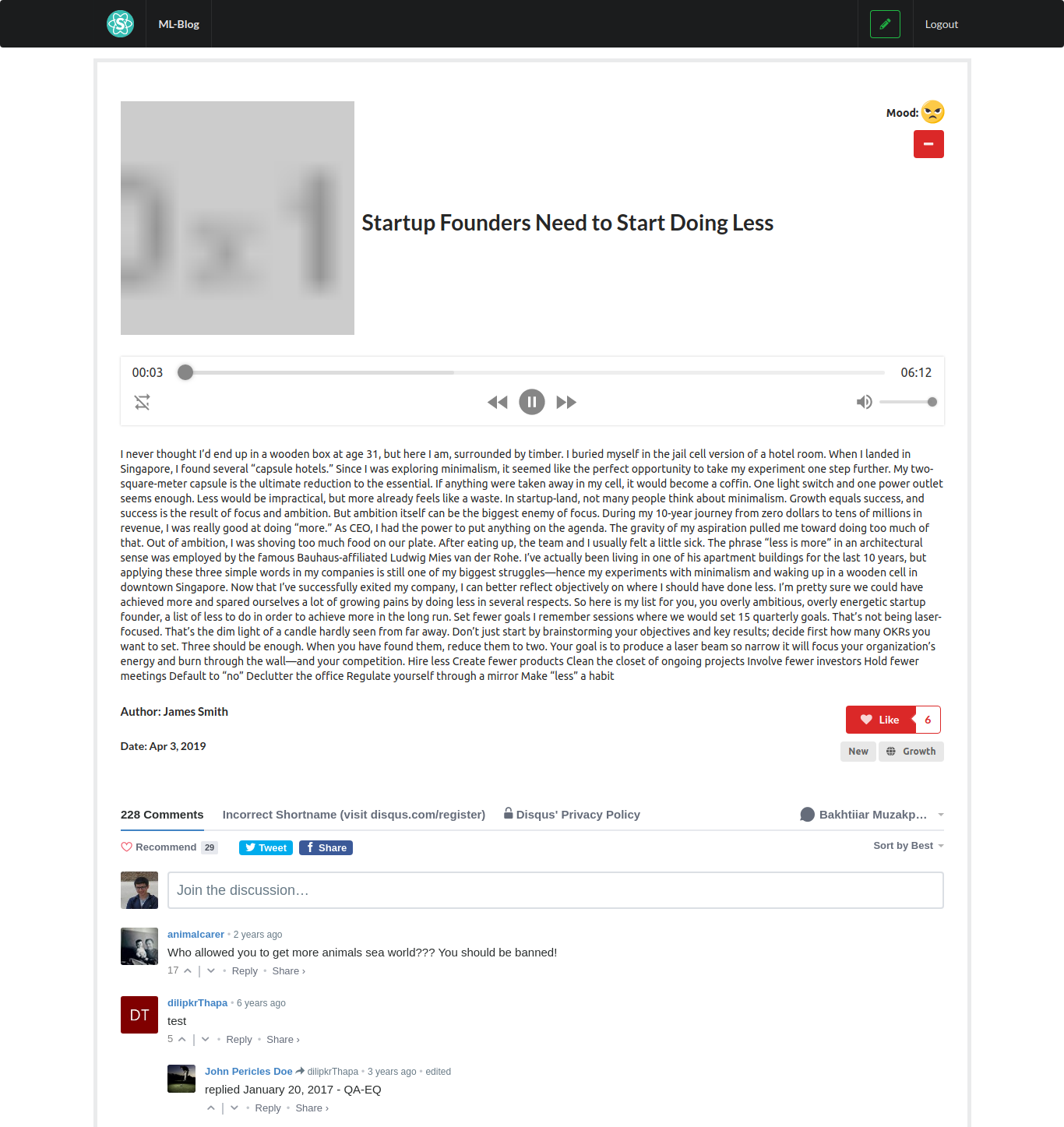
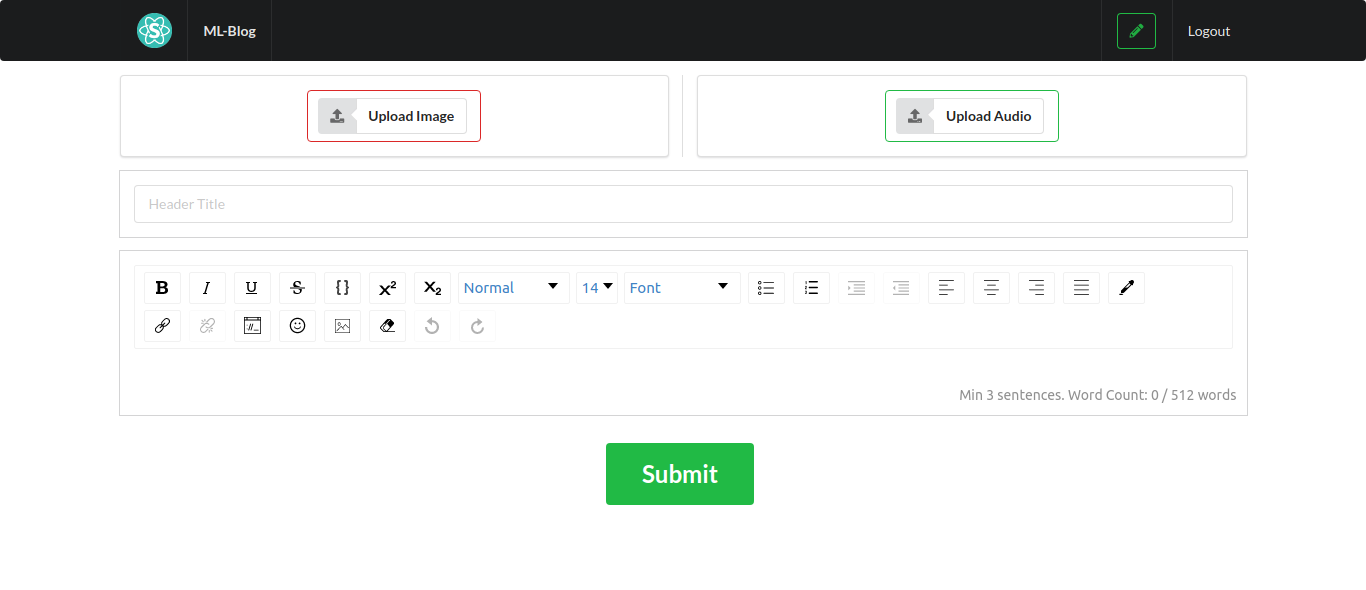
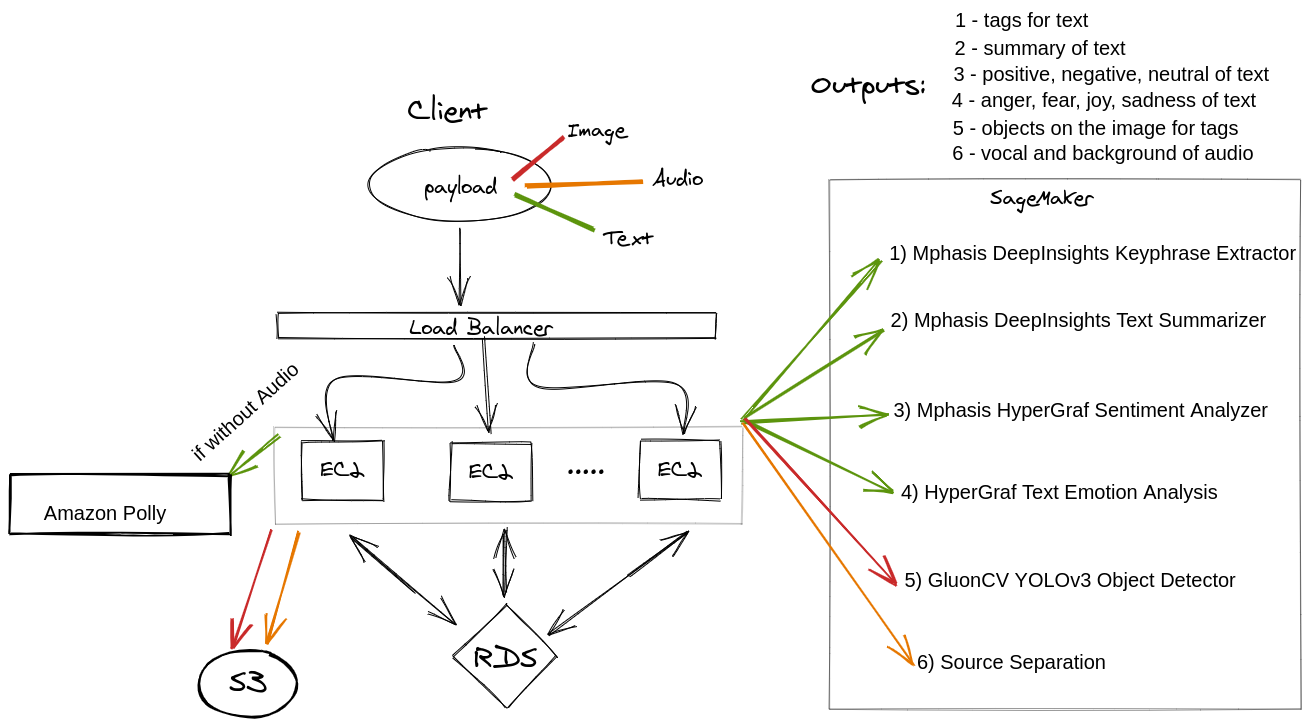
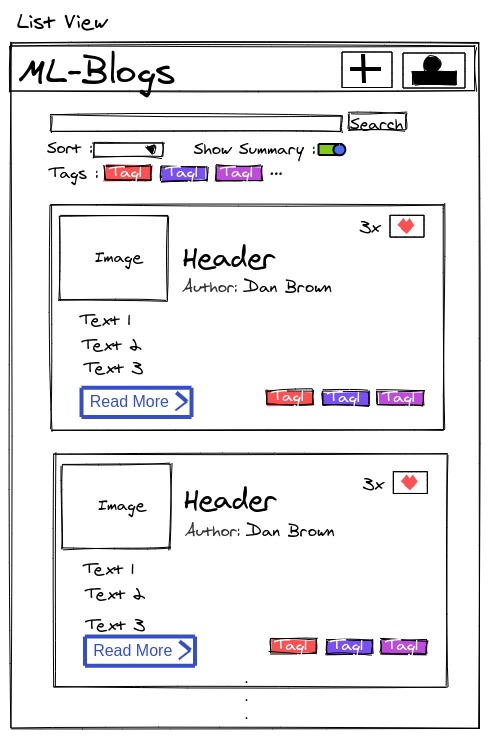

Inspiration
Today's users are overwhelmed with an inflow of information. There are so many interesting things to consume on the web - so many news, articles, and blogs to read as well as many cool podcasts to listen to. But all of us have limited time in a day and hence usually, we end up skimming a lot of text daily. But there is a potential of missing out a crucially important piece of information while skimming, also scrolling something you will not read is a waste of time, even if it is small. Wouldn't it be nice if there was a platform that helps to eliminate those risks and concerns?
What it does
ML-Blog is an easy-to-use blogging platform that helps you save time by summarizing long texts as well as providing crystal clear audio of the text from the author himself. Our platform dramatically simplifies blogging both for readers and writers. For the readers, it provides an accurate and short 3-sentence summary of the long texts making sure they don't miss out on what matters the most. Our readers can easily search and find interesting blogs by being able to sort and filter with comprehensive tags. Additionally, our readers will be able to listen to the crystal clear audio of the text narrated personally by the writer himself which opens an opportunity to self-educate yourself while running or driving. For the writers, we offer an intuitive editor interface where they can write without any distractions. As a saying goes: A picture is worth a thousand words. So, we ask a writer to upload an image that captures and conveys his main idea and optionally a recorded narration of the text. In the text area similar to twitter's character limit, we have a word limit of 512 words and at least 3 sentences. This is due to Sagemaker restriction and Model limitation, but also this kind of limitation often sparks creativity such as twitter with its 280-character limit and TikTok with 15-second videos. Once you submit, the entries will get sent to our server on EC2 which does multiple types of processing behind the scenes.
How I built it
This is a diagram of our infrastructure, the payload from the client gets sent to our servers running on EC2 instances passing through Load Balance which distributes traffic. As a database, we are using Amazon RDS. Before committing to the database our NodeJs server does necessary transformations to adjust to ML service input format and sends text to 1, 2, 3 ,4 in the diagram and gets back positivity, sentiment, tags, and summary of the text. Image is sent to 5 and we get back objects on the image. An audio file is sent to 6 and we save an audio file with just vocal without the background noise that is how we achieve crystal clear audio without noise to S3. Image is also stored in S3 with their IDs and relevant S3 links/references in RDS. This is our backend, which uses AWS services and ML solutions from AWS marketplace to do quite impressive things.
Challenges I ran into
It was hard to get accustomed to using ML models first since initially we thought we need ML background to use them.
Accomplishments that I'm proud of
Really proud of how much we could achieve with AWS, never thought we could do something like that, it is really empowering.
What I learned
As a front end developer learned a lot about AWS services and about AWS as well.
What's next for ML-Blog
I think we have great room for improvement and for adding a lot of useful features in the future.
Built With
- amazon-polly
- amazon-web-services
- javascript
- node.js
- python
- react
- s3
- sagemaker




Log in or sign up for Devpost to join the conversation.