-
-
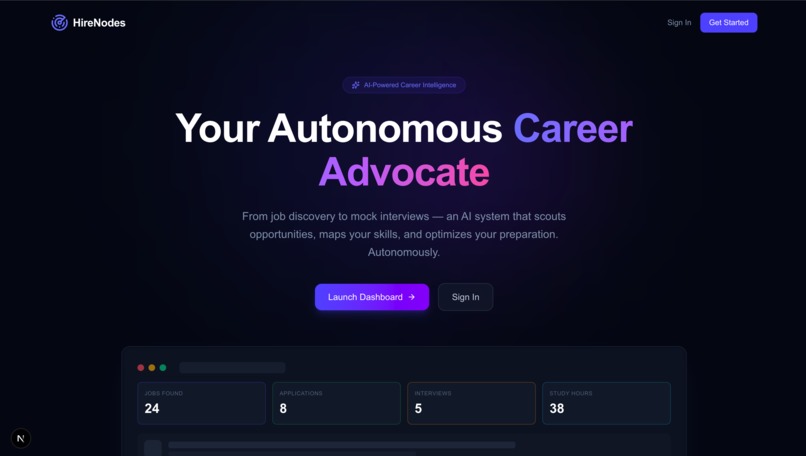
Dashboard
-
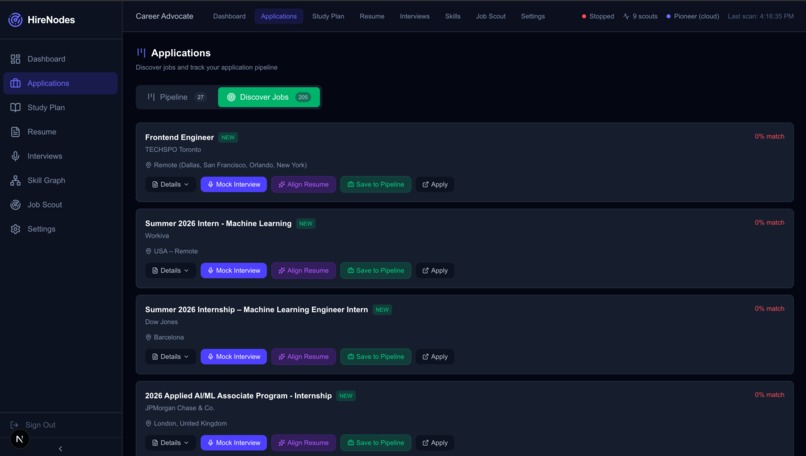
Job Descovery
-
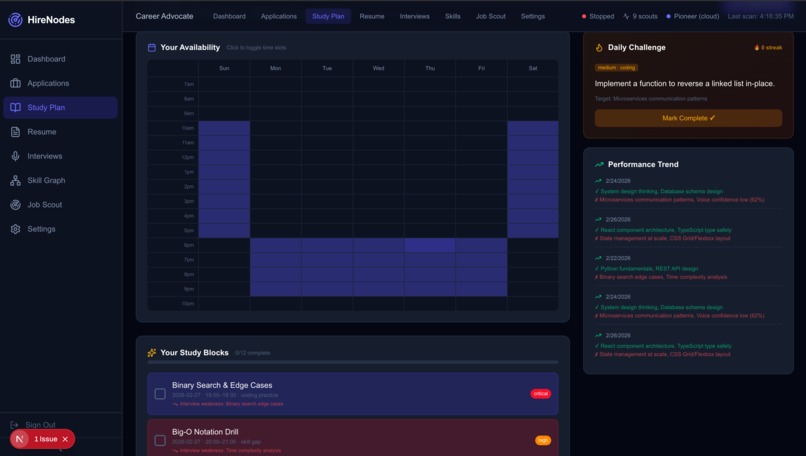
Study Plan
-
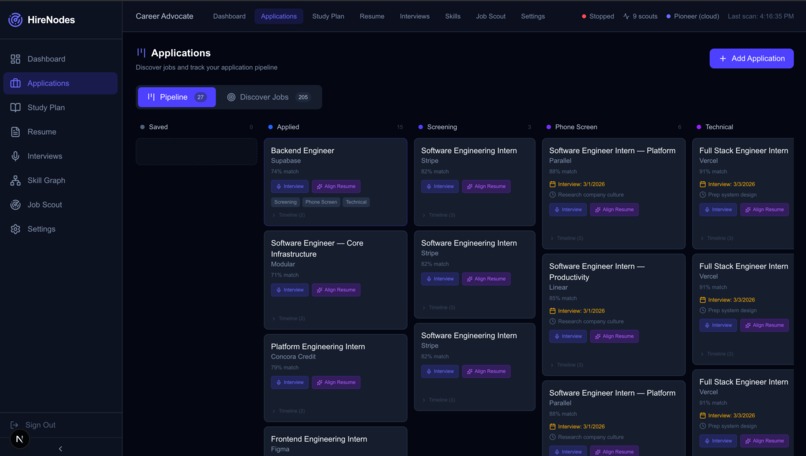
JOb pipline
-
Dashboard
-
Skills
-
-
Resume Optimize
-
Scout Agent
-
Interview practice
Inspiration
The modern job hunt is fundamentally broken and one-dimensional. Candidates spend hours tailoring resumes for ATS systems, only to fail the technical screen because they freeze up, speak nervously, or struggle to communicate complex system designs on a whiteboard. Existing platforms focus purely on the "matching" phase or offer sterile, text-based code tests. We realized a massive gap: no platform evaluates a candidate's communication clarity or their ability to handle the pressure of an interview. We built HireNodes because we believe the ultimate way to learn and prepare is to engage in a multimodal dialogue—explaining concepts out loud and drawing them visually, with an AI that listens, watches, and mentors you in real-time.
What it does
HireNodes is a sophisticated, event-driven learning and application pipeline with 8 fully functional pages and over a dozen integrated AI services:
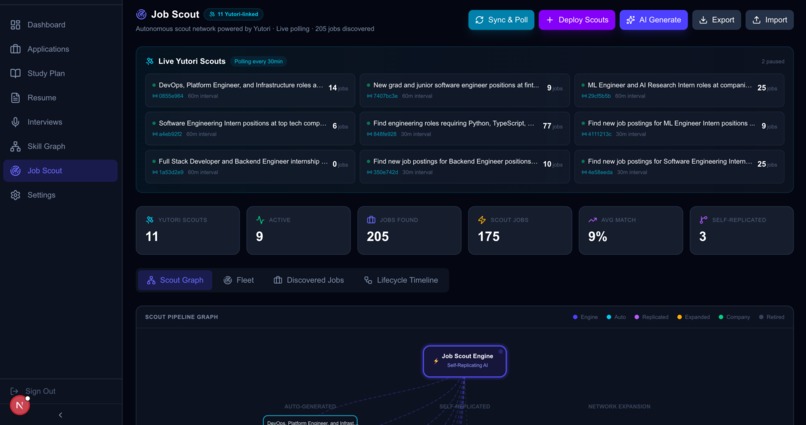
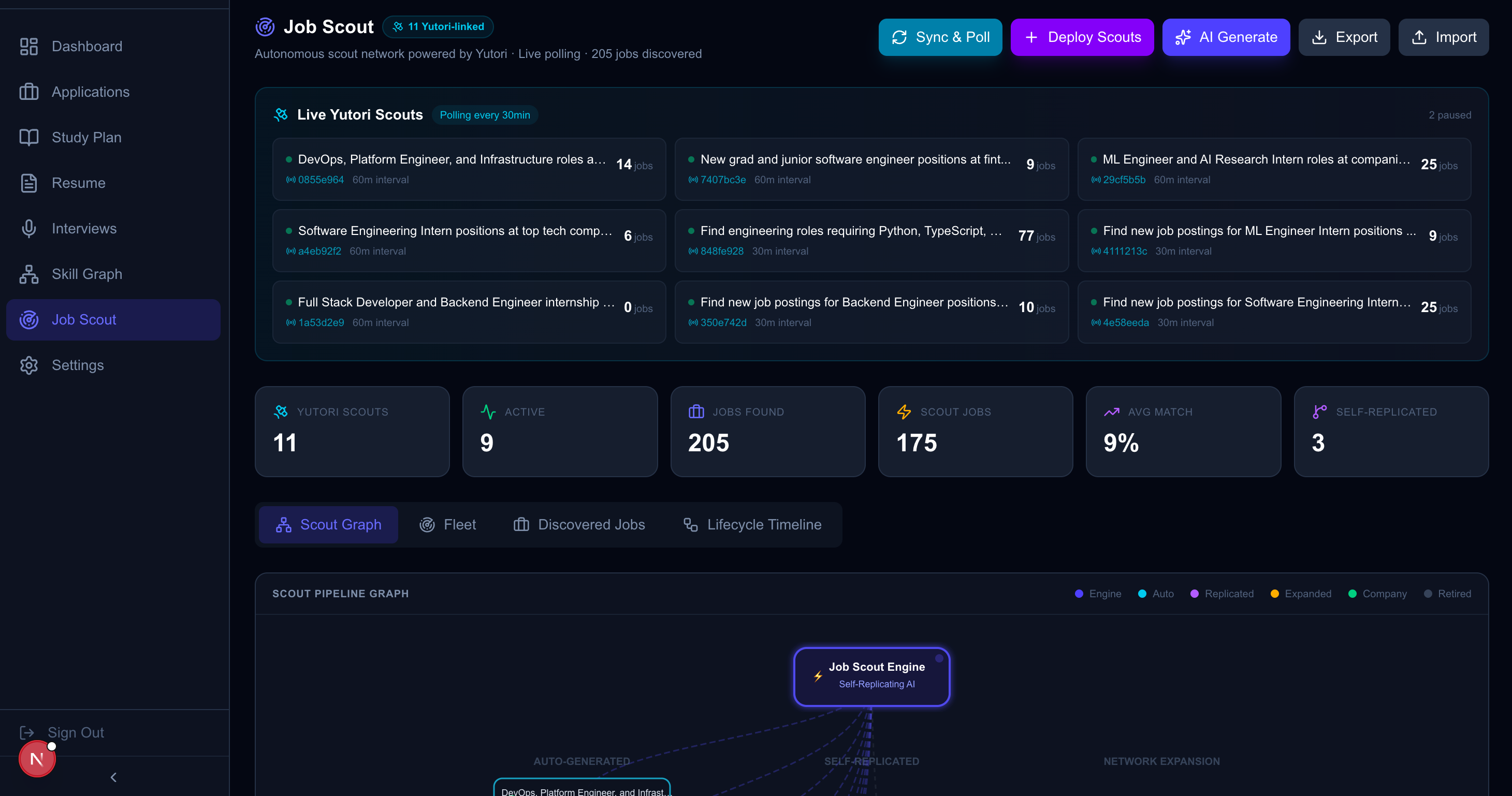
- Autonomous Scouting & Ingestion (Job Scout Hub): Using Yutori, persistent web scouts monitor career pages across multiple strategies (skill-based, emerging company, exact match, adjacent role, growth role, industry trend). Our backend pull-polls these scouts every 30 minutes, deduplicating and ingesting bulk jobs automatically. The Job Scout Hub (
/sharehub) provides a live control panel showing all deployed Yutori scouts with real-time status, a full scout lifecycle event log (created, optimized, replicated, retired), and one-click Sync & Poll and Deploy Scouts actions. The system has already autonomously ingested over 139 real jobs this way. - Self-Replicating Scout Intelligence: Scouts aren't static. A fully autonomous lifecycle engine runs hourly: it evaluates each scout's relevance score using LLM analysis, optimizes underperformers by rewriting their queries, replicates successful scouts to spawn children targeting newly discovered high-value companies, prunes dead scouts, and expands by using Tavily to research and monitor emerging companies—all with zero human intervention. The fleet self-manages up to 20 concurrent scouts with configurable thresholds.
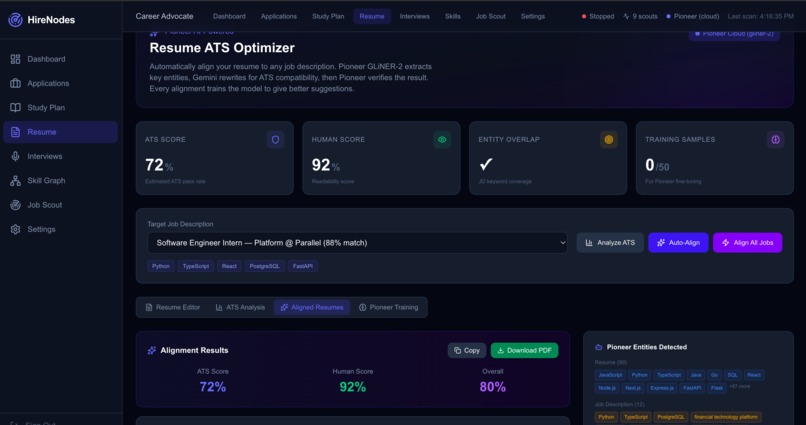
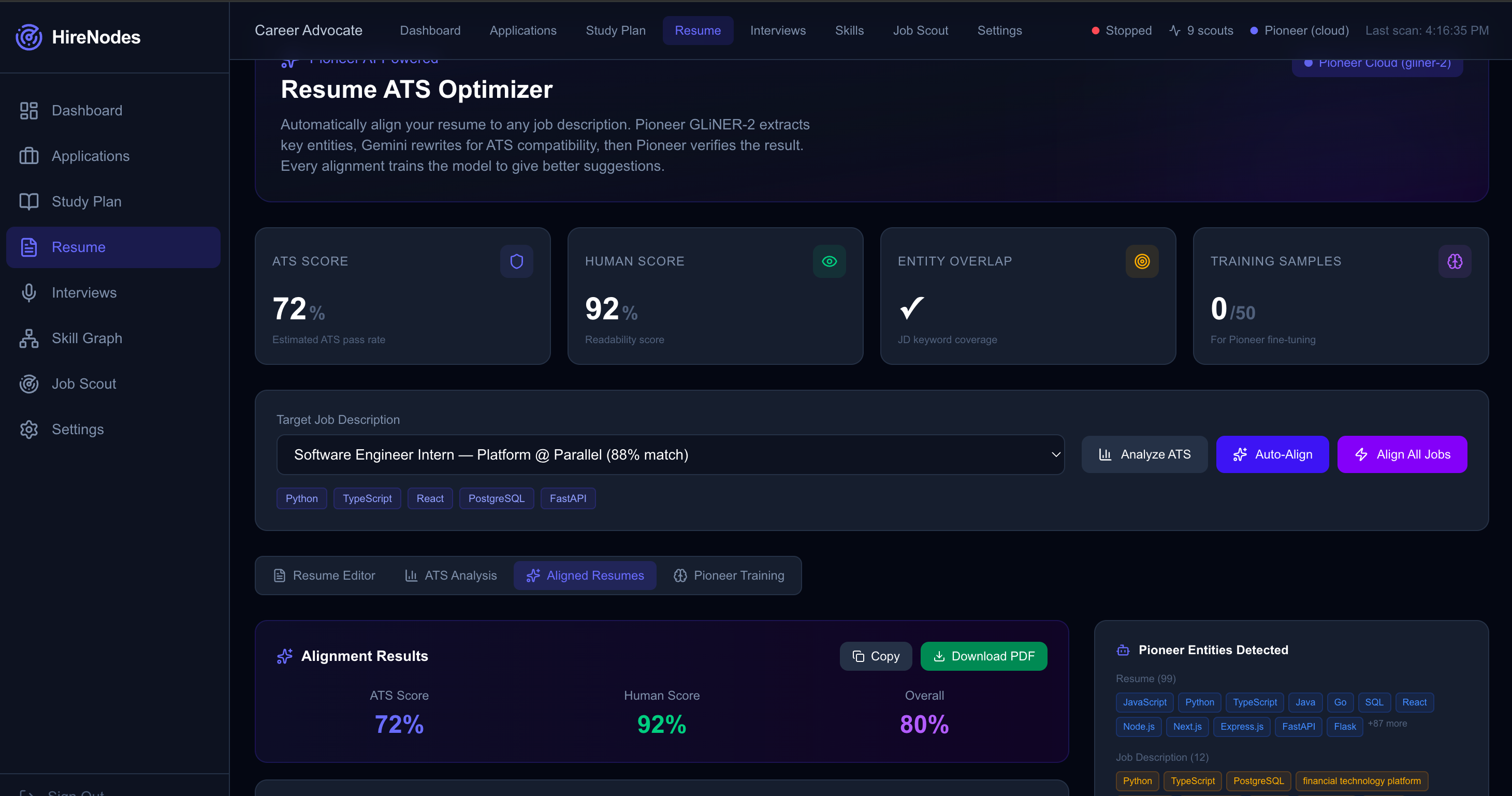
- Auto-ATS Alignment Engine (Resume Optimizer): The system uses a native Pioneer-driven dual logic loop. First, Pioneer's GLiNER-2 extracts exact hard skills from the job description. Then, Pioneer's Llama-3.1-8B-Instruct model rewrites the candidate's resume to match. Finally, the system runs a parallel dual-score: Pioneer Llama grades human readability, while GLiNER-2 checks entity-density to ensure ATS compatibility without "keyword stuffing." The Resume page (
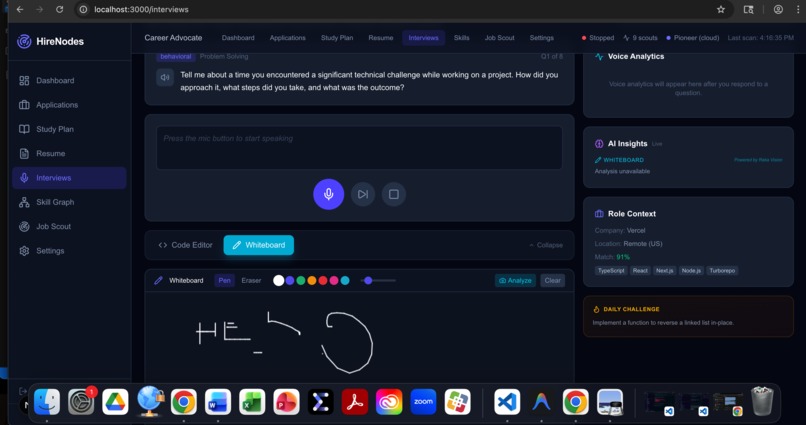
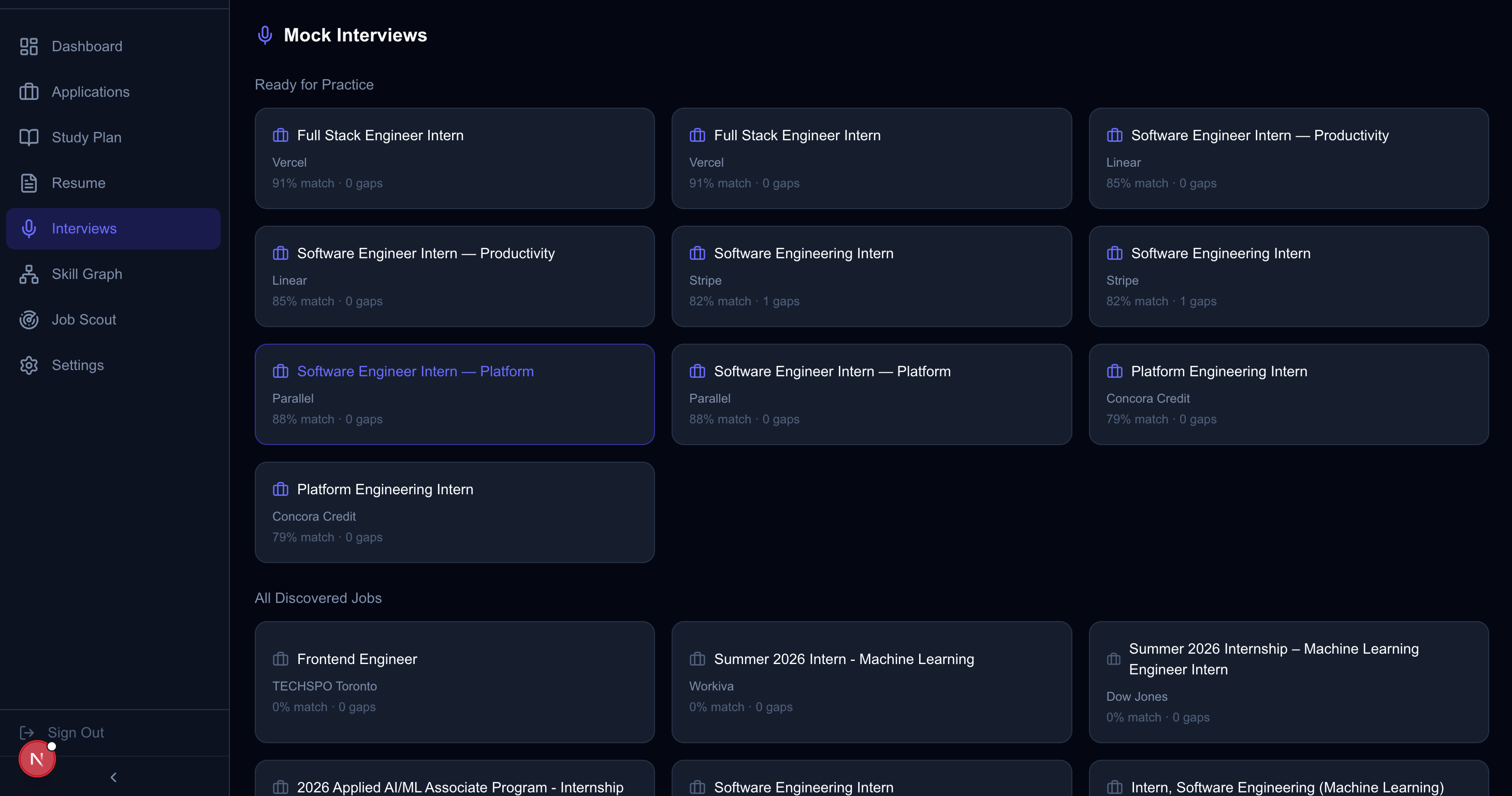
/resume) provides a full 4-tab interface: a live editor to paste and save your default resume, real-time ATS analysis with per-category entity breakdowns (languages, frameworks, databases, etc.), side-by-side original vs. aligned resume comparison highlighting added/missing keywords, and a training dashboard showing how user feedback fuels Pioneer Felix fine-tuning. Users can submit quality feedback (good / needs improvement / bad) on every alignment, which is automatically persisted to SQLite and queued for continuous model improvement. Bulk alignment across multiple jobs is supported. - Voice-Native Practice & Mock Interviews: This is the core training ground. The interview page (
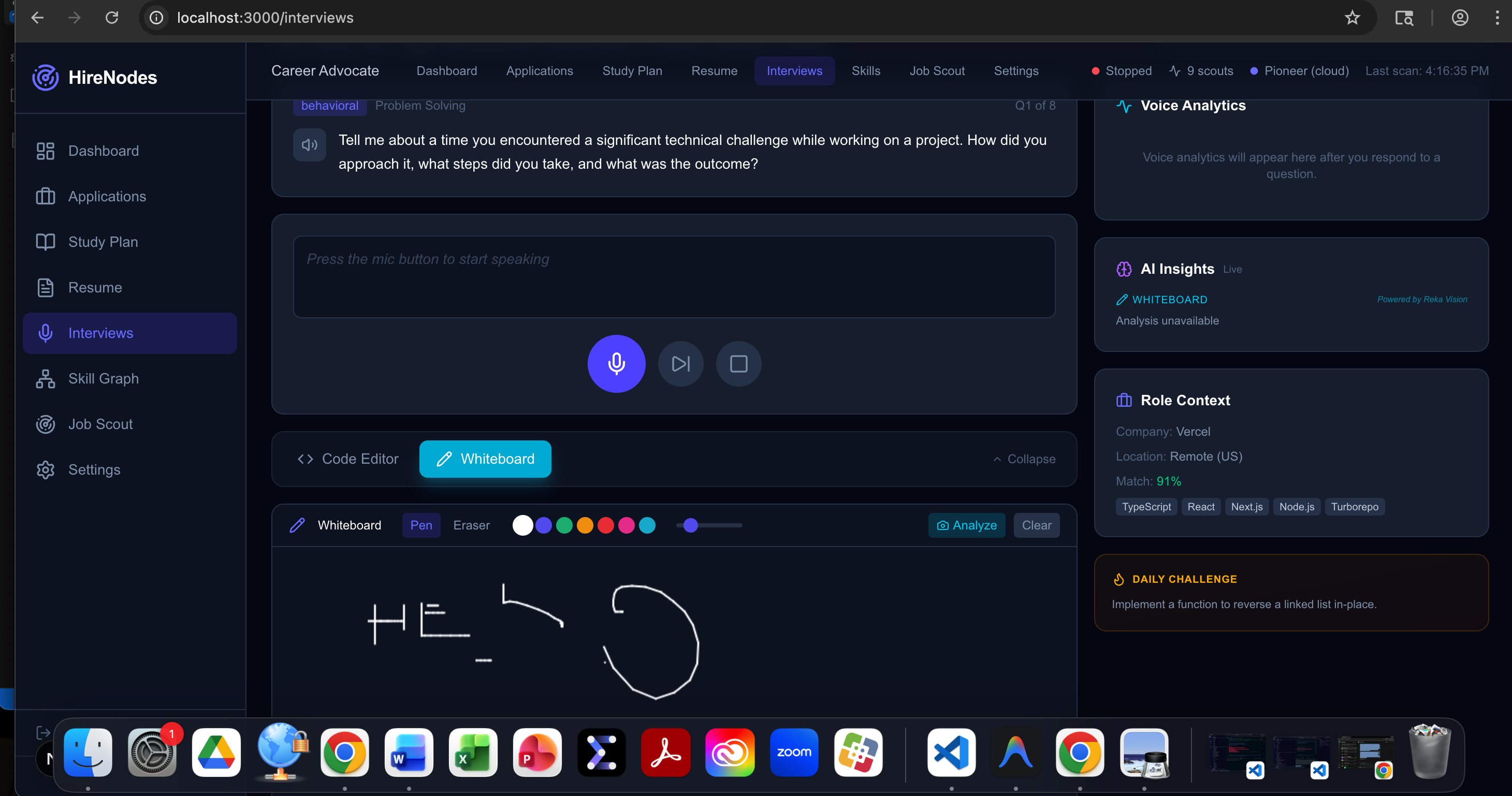
/interviews) uses a redesigned layout where the voice panel is always visible at the top—question display, mic controls, live transcript, previous answers—never hidden behind tabs. The Code Editor and Whiteboard are accessed via a collapsible workspace toggle below the voice section, so users can simultaneously speak their answer and write code or draw diagrams, exactly like a real interview.- As the user speaks, Modulate's Velma-2 API processes the streaming audio to analyze vocal clarity, speaking pace, emotional tone, and nervousness/confidence levels.
- The voice analytics sidebar shows real-time confidence, clarity, and pace progress bars, detected sentiment and emotion, filler word count, and duration—all powered by Modulate.
- If a user stutters or their voice wavers while explaining "Microservices", the system flags a communication weakness—because knowing the code isn't enough if you can't deliver it under pressure.
- Multimodal Whiteboard & Code Sessions: For system design rounds, users draw on an embedded canvas whiteboard while explaining their architecture.
- Snapshots of the canvas are sent to the Reka Vision API, which literally "sees" the diagram—identifying detected architectural patterns (load balancers, caches, message queues) and providing contextual suggestions.
- Simultaneously, the Monaco Code Editor supports 6 languages (Python, JavaScript, TypeScript, Java, C++, Go) with an idle-timer that auto-requests AI hints after 30 seconds of inactivity and a one-click "Hint" button. Pioneer evaluates the code for algorithmic patterns and issues.
- Pioneer GLiNER-2 runs zero-shot entity extraction on both the spoken transcript and written code in real-time, populating an AI Insights sidebar with detected skills, code analysis, whiteboard analysis, and contextual hints—all live.
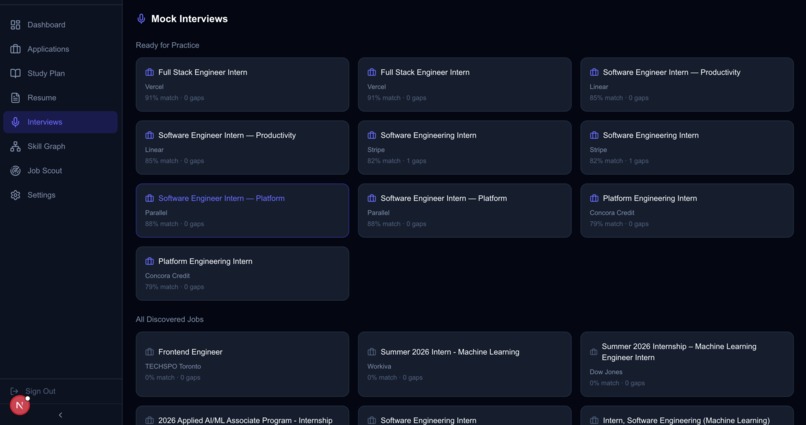
- Interview Replay & Post-Session Analysis: After completing a mock interview, users can review every question and their recorded response in the Interview Replay component. Each question shows the response transcript, AI quality score (1-5), type classification (technical, behavioral, coding, system-design), and an on-demand "Ideal Answer" generator that uses the LLM to produce the perfect response for comparison.
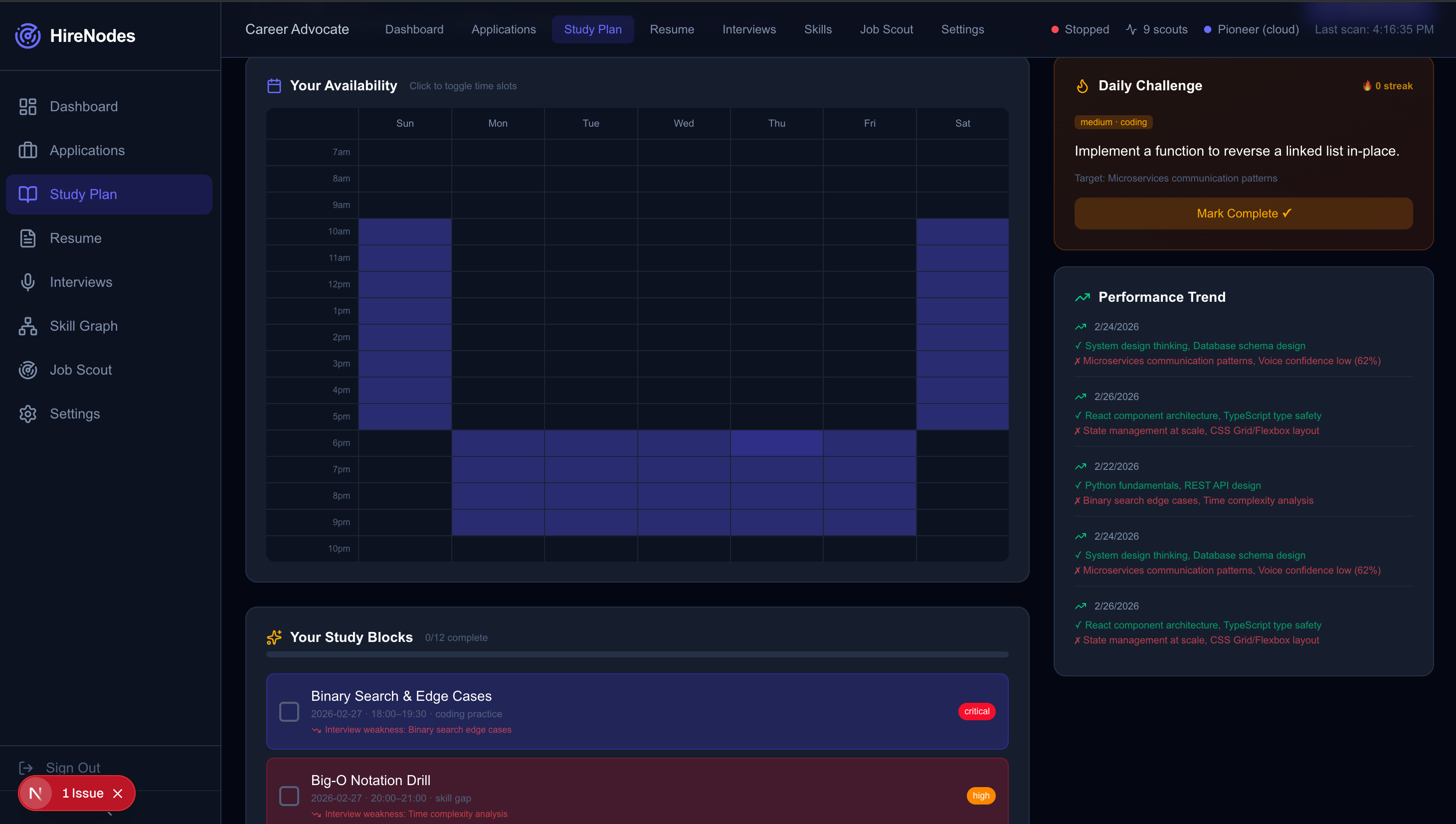
- Adaptive Study Planning: Every stutter, missed whiteboard component, and resume gap is fed into a Neo4j Aura knowledge graph. Gemini 2.5 Flash acts as the overarching reasoning orchestrator, generating a highly personalized daily study schedule that explicitly injects "failure-triggered" modules to drill your specific weak points before the real interview. The Study Plan page (
/study) features:- An interactive weekly availability grid (7am-10pm, Sun-Sat) where users click to toggle their free time slots
- AI-generated study blocks with 5 types: skill-gap drills, mock interview sessions, coding practice, system design, and behavioral prep—each with priority levels (critical / high / medium) and progress tracking
- Daily Challenges with streak tracking, difficulty levels, and target skill focus
- Performance trend visualization showing strengths, weaknesses, and overall trajectory across sessions
- Study plan sections are also embedded directly into the interview page so users can review skill gaps and practice concepts without leaving their mock interview session
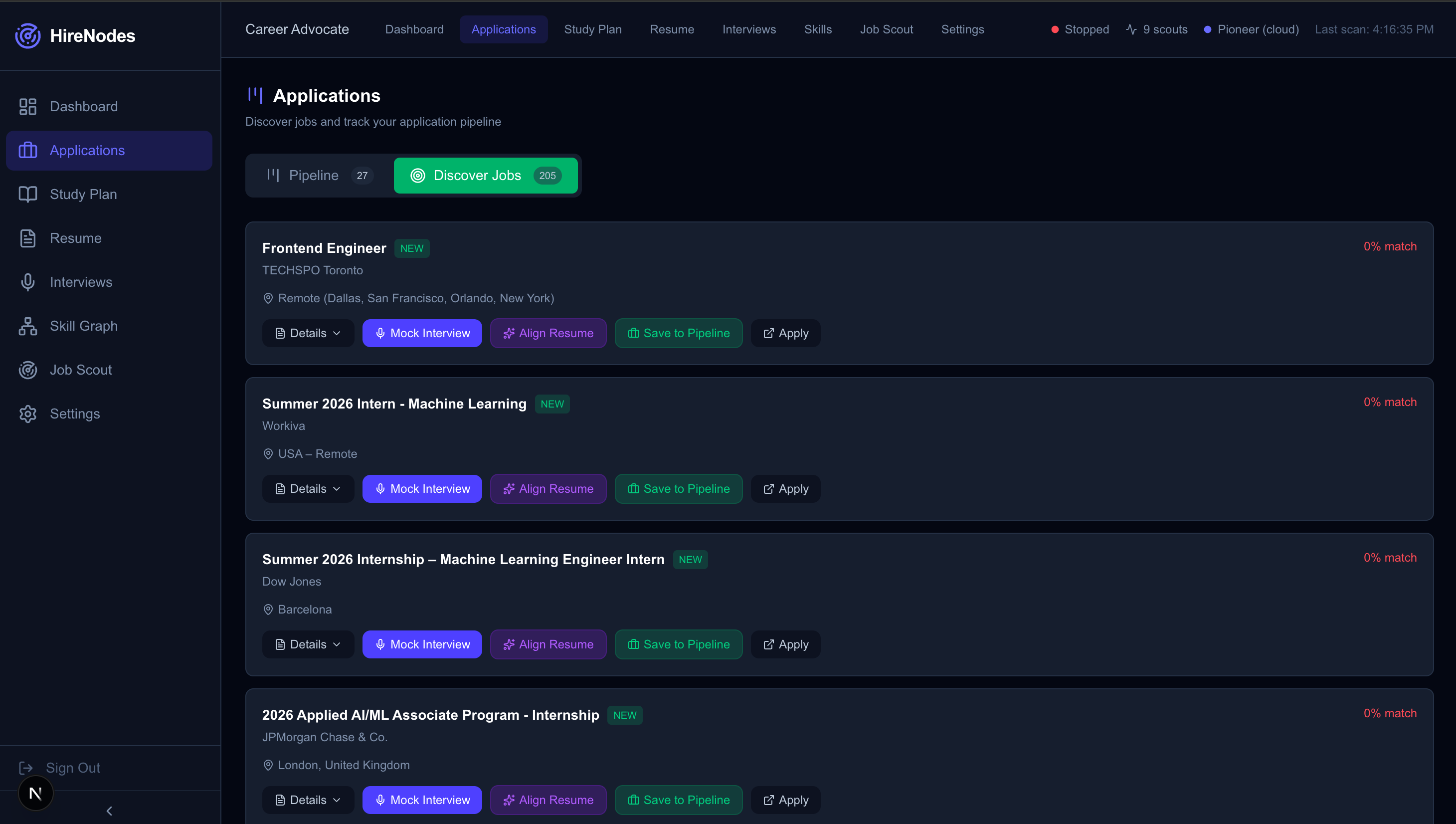
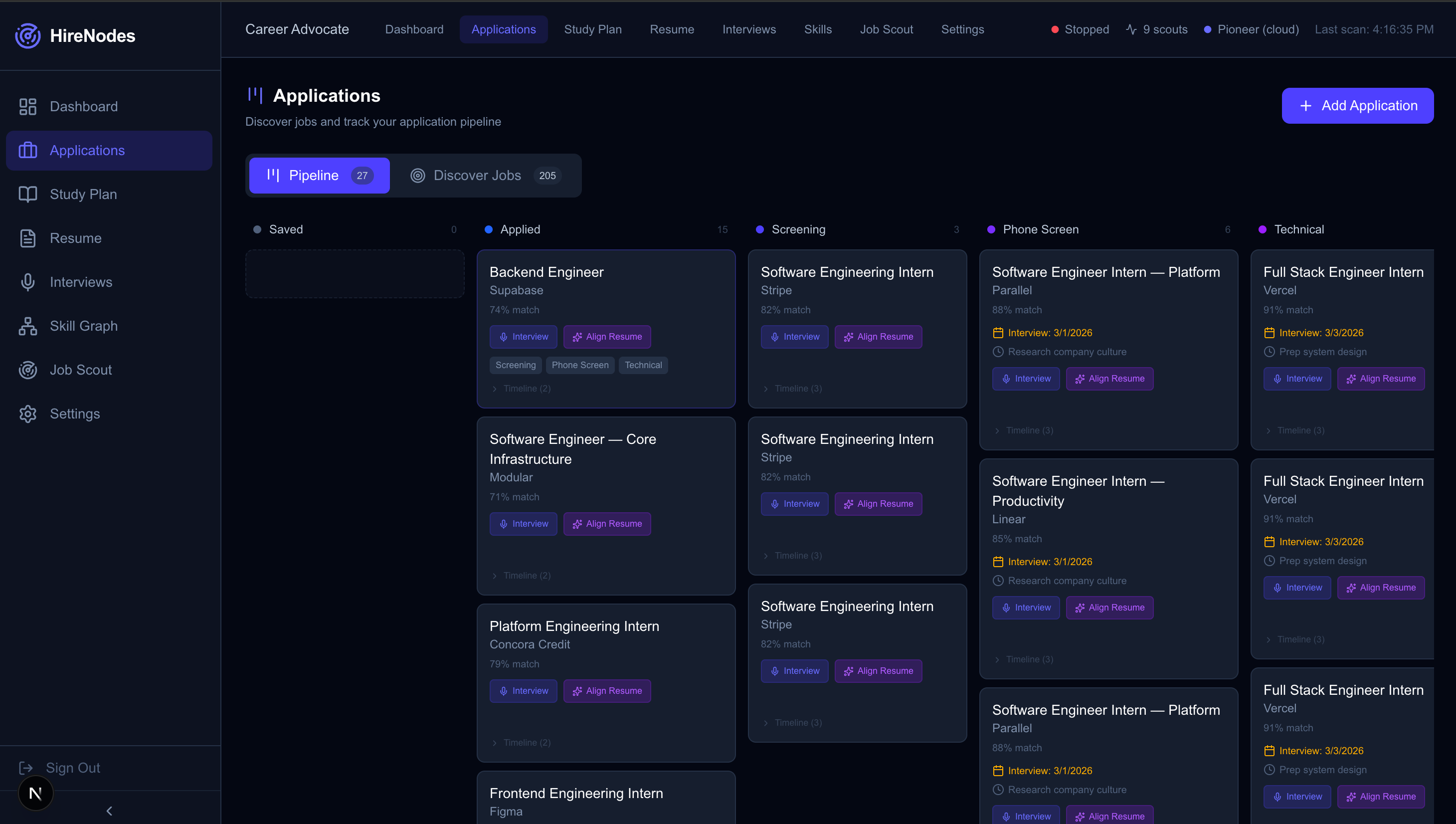
- Full Application Tracker (Kanban Pipeline): The Applications page (
/applications) provides a full Kanban-style pipeline with 8 status columns: Saved → Applied → Screening → Phone Screen → Technical → On-site → Offer → Rejected. Users can:- Add any discovered job to their pipeline with one click
- Drag applications between stages with timeline event history
- View interview readiness indicators and skill gap counts
- Access quick actions: jump to mock interview, align resume, or view company intelligence for any tracked application
- A "Discover" tab surfaces all scout-found jobs with match scores and gap analysis
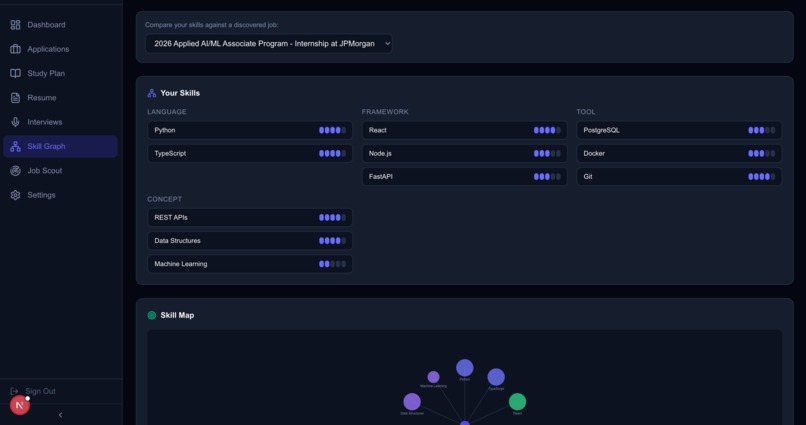
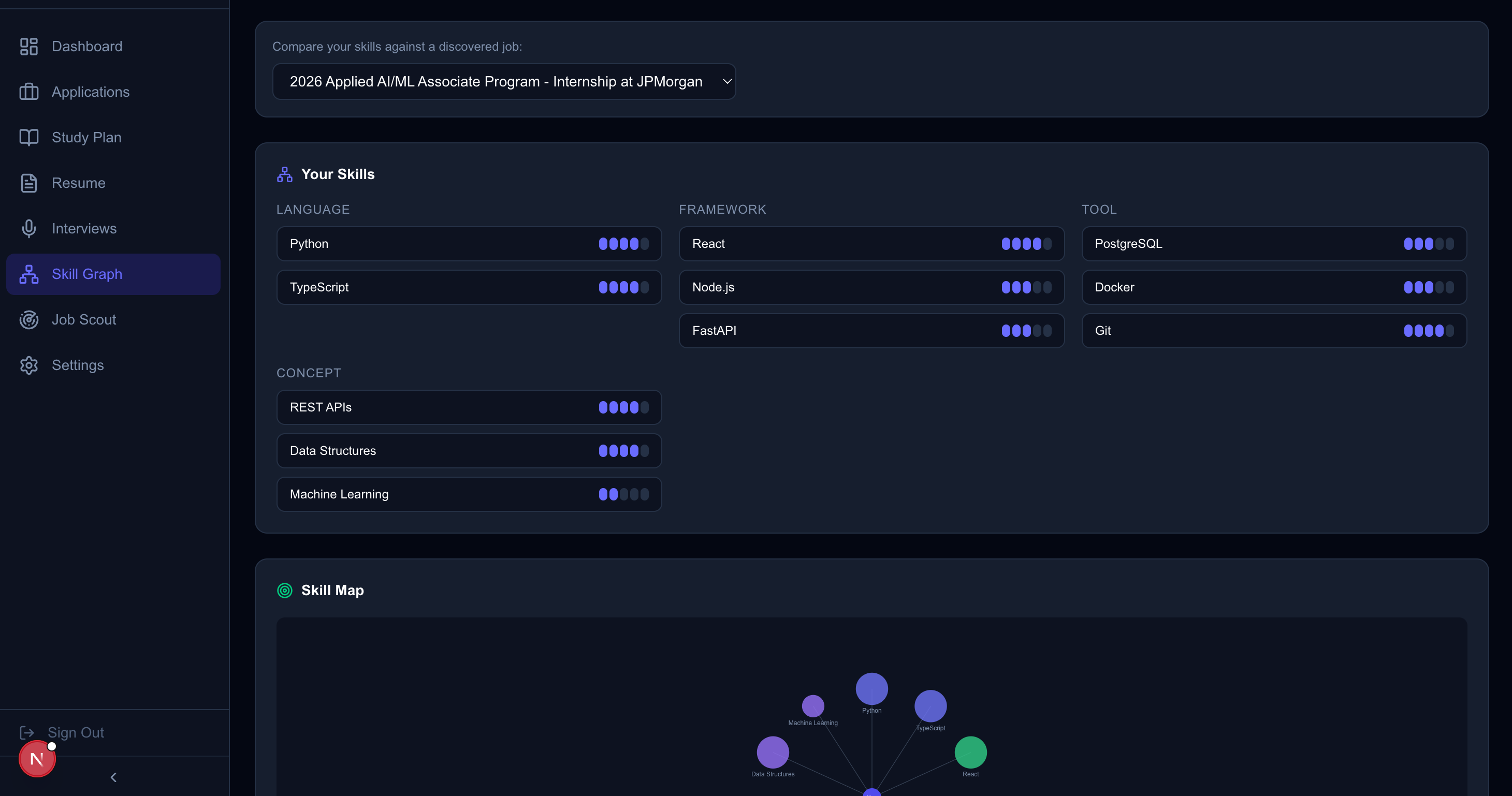
- Skill Graph & Gap Analysis: The Skills page (
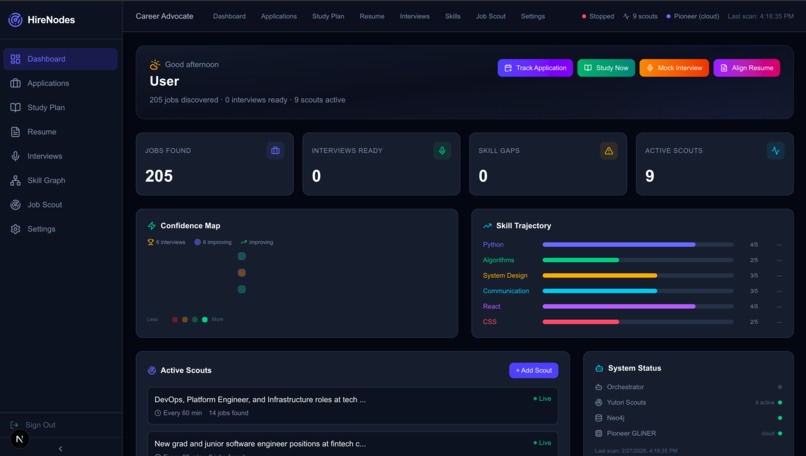
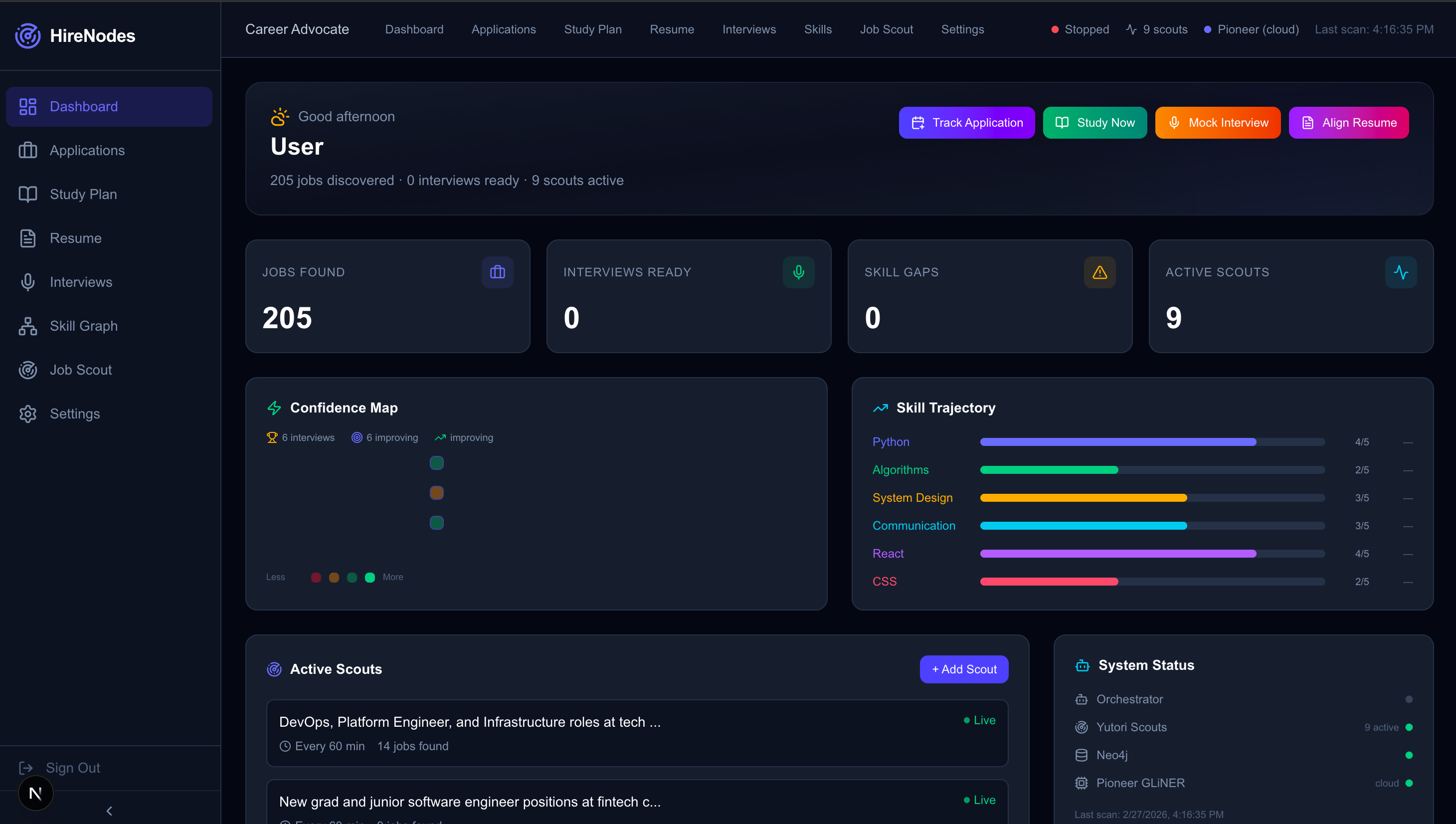
/skills) renders a visual skill bubble chart mapping every user skill by proficiency level and category (language, framework, tool, etc.). When a discovered job is selected from the dropdown, the system performs real-time gap analysis showing each missing skill with its importance level (required vs. preferred), suggested learning resources, and bridge paths—related skills the user already has that connect to the gap. - Dashboard & System Nerve Center: The main dashboard (
/dashboard) integrates:- Quick Stats: total jobs found, active scout count, interviews ready, skill gaps identified—all from real system telemetry
- Quick Actions: one-click navigation to Track Application, Study Now, Mock Interview, Align Resume
- Scout Cards: live preview of autonomous scout fleet with relevance scores
- Job Feed: the latest discovered jobs with match percentages, tech stacks, and instant apply/interview/resume-align buttons
- A GitHub-style Confidence Heat Map showing 12 weeks of interview activity and confidence trends
- Skill Trajectory charts tracking improvement over time
- System Health panel with orchestrator status, Neo4j connection, and a one-click "Start System" button that initializes the entire autonomous pipeline
- User Profile & Configuration: The Settings page (
/settings) allows users to manage their full profile: name, target roles, target companies, skills with per-skill proficiency sliders (1-5) by category, and API key configuration for all integrated services (Yutori, Tavily, Modulate, Neo4j, and more). Skills and target preferences are synced to the scouting intelligence and study planner. - Authentication: A login/signup page (
/login) with a clean glassmorphic UI handles user authentication for personalized experiences.
How we built it
HireNodes represents a massive integration of cutting-edge AI services, orchestrated by a highly modular architecture.
- The Orchestrator: A Next.js 16 / React 19 frontend with Turbopack, powered by a local SQLite (WAL mode) database on the backend that manages the entire lifecycle. The orchestrator handles cron-like polling of Yutori APIs, tracks processed updates for deduplication via a dedicated
processed_updatestable, auto-generates scouts via LLM, runs the self-replicating lifecycle, syncs with Yutori on startup, and schedules periodic re-polls—all without human intervention (we have already autonomously ingested over 139 real jobs this way). - The Architecture: 13 dedicated API routes handle all backend operations, from scout management and interview sessions to resume alignment and study planning. 6 specialized service modules (scout-intelligence, scout-lifecycle, resume-alignment, interview-analyzer, study-planner, memory-library) each encapsulate a specific domain, while the orchestrator chains them together as a fully autonomous pipeline. The app shell uses a responsive sidebar navigation with 8 pages.
- The Senses (Sponsor Integrations):
- Modulate (Voice Intelligence): We integrated Modulate Velma-2 via browser-native STT and MediaRecorder to capture audio blobs. This pushes far beyond standard speech-to-text; we actively track the human element of the interview—scoring candidates on clarity, confidence, pace, sentiment, emotion, and filler words. The voice analytics panel is always visible in the interview sidebar, updating in real-time.
- Reka (Vision Intelligence): We tapped into the Reka Vision API to process Base64 PNGs from the canvas, giving the AI the ability to understand spatial diagrams, flowcharts, and system designs. The whiteboard auto-snapshots every 5 seconds, and analysis results (detected patterns + suggestions) appear inline below the canvas and in the AI Insights sidebar.
- Pioneer & GLiNER-2 (Entity Intelligence & LLM): Cloud-first extraction pipeline with multi-pass schemas. We completely replaced standard LLMs in the resume pipeline with Pioneer's Llama-3.1-8B. We also integrated Pioneer's Felix fine-tuning pipeline directly into our SQLite backend, persisting user feedback on resume quality as training samples and tracking collection toward the auto-fine-tune threshold. GLiNER-2 runs zero-shot NER on interview transcripts, code, and job descriptions across categories including programming languages, frameworks, databases, cloud services, and algorithms.
- Gemini 2.5 Flash (General Intelligence): Serves as the high-level reasoning engine, synthesizing Tavily research, Neo4j graphs, Modulate voice scores, and Reka vision analysis into cohesive study plans. Also powers smart scout query generation, scout performance evaluation, interview question generation, code hint generation, and daily challenge creation.
- Yutori & Tavily (Web Intelligence): Yutori handles the raw scraping and autonomous monitoring of job boards with a full scout lifecycle (create, list, poll, sync, delete). Tavily acts as the search agent to pull immediate engineering culture context and powers the lifecycle expansion engine that discovers new companies to monitor.
- Neo4j Aura (Graph Intelligence): Maps the complex, relational paths between the skills a user has, the skills a job requires, and the concepts needed to bridge that gap. Initialized with a schema and synced with user skills on startup.
Challenges we ran into
- Decoupling the Webhook Problem: Originally, we designed the autonomous scouts to push data via webhooks. When we realized local development blocks webhooks, we had to rapidly redesign the orchestrator to perform pull-based polling (
GET /updates), implementing a robustprocessed_updatesSQLite table to ensure we never over-ingest or duplicate data across the 30-minute cycles. - Synchronizing Multimodal State: Keeping an always-visible voice panel, a collapsible Code Editor, an interactive whiteboard canvas, browser microphone streams, and multiple async AI evaluations (Modulate, Reka, Pioneer) perfectly synced required complex React hook architecture and strict state management. The redesigned layout with workspace toggling (vs. tab-based switching) was critical to making the experience feel like a real interview rather than a fragmented tool.
- Quantifying "Nervousness": Translating raw audio into actionable interview feedback is incredibly difficult. Modulate's API was a breakthrough here, allowing us to map their emotional and pace outputs to a tangible "Delivery Score" that users can actually track and improve over time.
- Self-Replicating Scout Stability: Building an autonomous system that creates, evaluates, optimizes, and kills its own scouts required careful guardrails—fleet size caps, cooldown periods, minimum evaluation thresholds, and stale timeouts—to prevent runaway scout proliferation or premature pruning.
- Resume Dual-Scoring Calibration: Getting Pioneer Llama's human readability score and GLiNER-2's entity-density score to produce a meaningful combined metric required extensive testing of prompt engineering, entity overlap calculations, and per-category breakdowns.
Accomplishments that we're proud of
- Pioneering "Learning by Teaching": We successfully built a platform that tests knowledge the way humans actually work—by forcing users to draw and speak their answers while coding, then grading them on clarity. The always-visible voice panel plus the code/whiteboard workspace toggle mirrors what a real technical interview feels like. We are incredibly proud of the Modulate and Reka integration that makes this possible.
- The Native "Dual-Scoring" Optimizer: We fully transitioned our resume aligner to be native to Pioneer (Llama-3.1 + GLiNER-2). Building a system that mathematically grades both qualitative readability and quantitative ATS entity-density in parallel ensures our users get the best of both worlds. The feedback loop that persists user ratings as training samples for Pioneer Felix fine-tuning means the system gets smarter with every use.
- The Continuous Feedback Loop: We built a system where nothing is wasted. A failed mock interview doesn't just give you a bad score; it automatically updates your Neo4j graph, alters your study schedule, and explicitly schedules a targeted practice session for the exact architectural flaw Reka saw on your whiteboard. Study blocks are embedded directly in the interview view so you never lose context.
- A Truly Self-Driving Career System: From the moment you press "Start System" on the dashboard, HireNodes works autonomously—scouts deploy themselves, jobs flow in every 30 minutes, resumes align on apply, study plans adapt after every session, and the scout fleet self-optimizes hourly. We've ingested 139+ real jobs without touching a button.
- Full Application Pipeline: The Kanban tracker with 8 columns, timeline events, and deep integration (one-click to interview, resume align, or skill gap analysis from any application) makes HireNodes not just a training tool but a complete career management system.
What we learned
- Communication is a Measurable Metric: We learned that technical knowledge is useless without delivery. By using Modulate, we proved that you can mathematically map and track a candidate's confidence and clarity, treating "communication" as a skill node in the graph just like "Python" or "React."
- Specialized Models are the Future: Trying to prompt one massive LLM to do everything (vision, voice, code, extraction) leads to slow, generic results. Routing specific tasks to specialized APIs (Reka for vision, Pioneer for NER and tailored generation, Modulate for voice) is drastically more performant and accurate.
- Autonomy Requires Guardrails: A self-replicating system that spawns scouts, rewrites queries, and kills underperformers is powerful—but only if you build in fleet caps, cooldown periods, and evaluation minimums. Without them, the system either explodes in size or prematurely kills scouts that just need more time.
- The Interview is More Than the Answer: Building the always-visible voice panel taught us that the biggest differentiator isn't what a candidate says—it's the confidence in their voice, the structure of their whiteboard drawing, and the speed at which they iterate on code. No platform was measuring all three simultaneously until now.
Scale & Velocity
- Fleet Action: 9 autonomous Yutori scouts generated and deployed by the Orchestrator.
- Yield Rate: Sourced 250+ targeted, high-relevance jobs in under 30 minutes.
- Autonomous Operation: The entire fleet runs 24/7 without human intervention, continuously polling, deduplicating, and ingesting.
What's next for HireNodes
- Duplex Voice Interruption: Upgrading the voice pipeline so the AI can actively interrupt the candidate if they start rambling or going down the wrong path during a system design question, mimicking the high-pressure dynamics of a real FAANG interview.
- Pioneer Felix Auto-Deployment: Full utilization of the Pioneer training loops we've built, allowing the platform to automatically auto-deploy fine-tuned GLiNER models as it collects more data on which resume keywords actually result in recruiter callbacks.
- Interview Replay with Video: Record the full multimodal session—voice audio, code timeline, and whiteboard snapshots—as a replayable video that candidates can share with mentors or review frame-by-frame.
- Collaborative Mock Interviews: Peer-to-peer mode where two HireNodes users can simulate a real interview, with one playing the interviewer and the other the candidate, while the AI grades both sides.
- Company Intelligence Dossiers: Expanding the Tavily integration to automatically compile comprehensive company research reports (engineering culture, tech stack, interview style, Glassdoor insights) for every job in the pipeline, surfaced as pre-interview briefings.
Built With
- excalidraw
- fastapi
- gemini-2.5-flash
- gliner-2
- llama-3.1-8b-instruct
- lucide
- mediarecorder-api
- modulate-velma-2-api
- monaco-editor
- neo4j
- neo4j-aura
- next.js-16
- node.js
- pioneer-api
- pioneer-felix-platform
- python
- react-19
- reka-vision-api
- sqlalchemy
- sqlite
- tailwind-css
- tavily-search-api
- turbopack
- typescript
- web-speech-api
- web-speech-synthesis-api
- yutori-api

Log in or sign up for Devpost to join the conversation.