-
Add Resumes
-
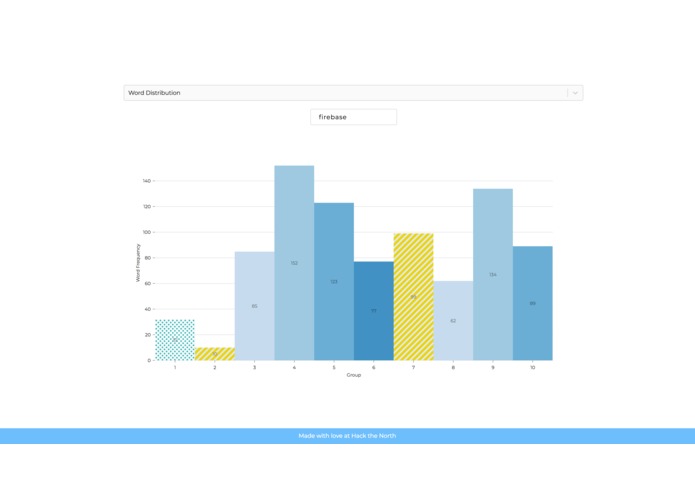
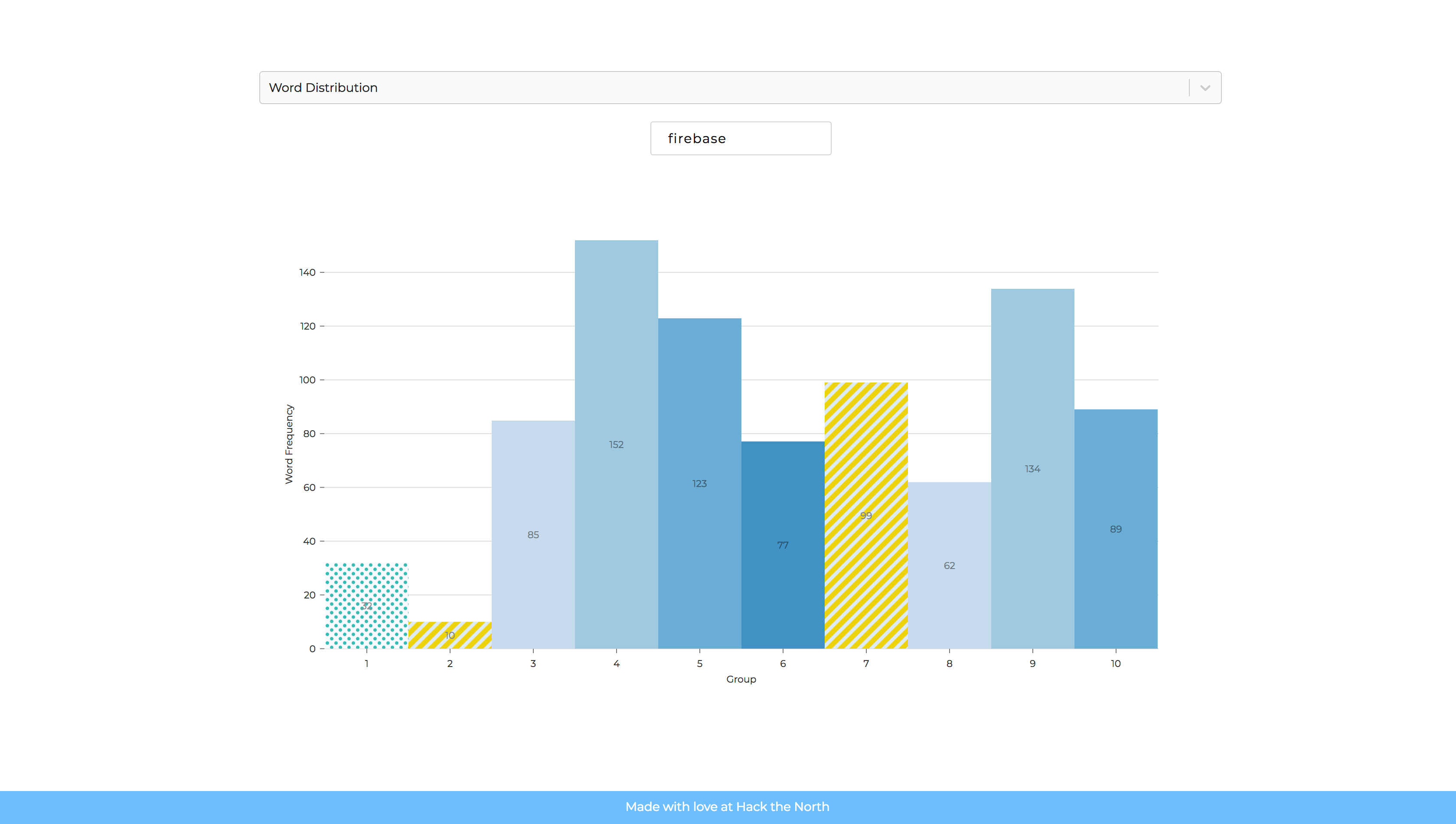
Frequency of Firebase as Keyword in Groups with Variations on Performance
-
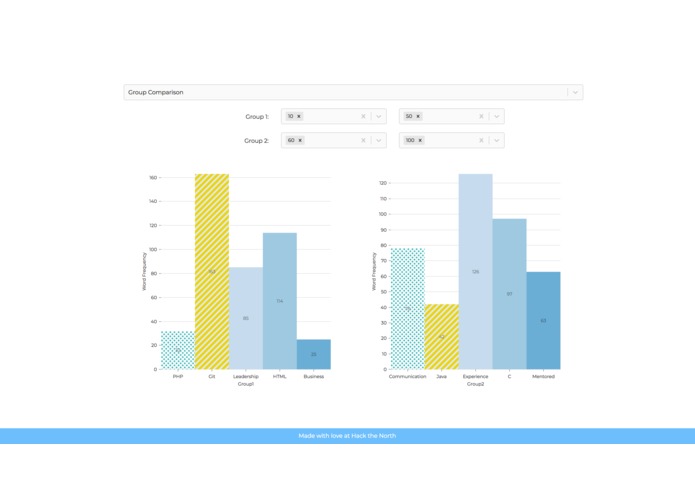
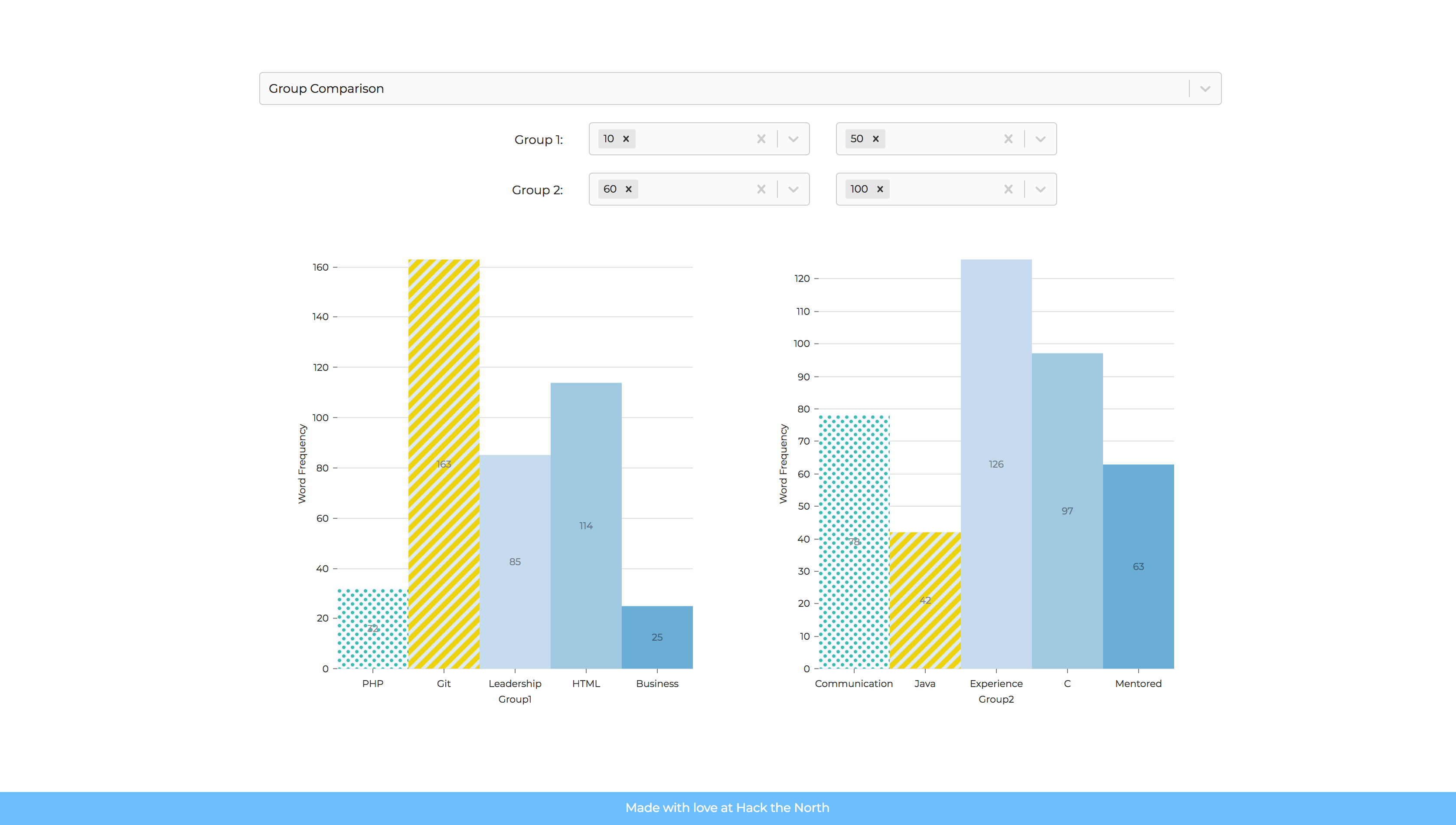
Most Popular Keywords Based on Employees' Performance with Frequency

Inspiration
Even with all of the technological advancements throughout various fields, human resources seems to be a sector that is being left behind. The entire process is completely determined by the HR manager's experience, and the search process is established upon his analysis of the job description. When there is automatic parsing, the keywords are extracted by the HR manager, otherwise, it is the same person who is scanning through the pile of resumes. It is not only problematic that we are placing so much trust in this person, but that as an organization, we are highly dependent on them. All the knowledge of the organization for hiring for any historical roles are lost with the leave of a hiring manager. Recruiters are being paid based on customer satisfaction, but will never receive feedback on exactly how exceptional hires differs from satisfactory ones. Our website HIREflection offers a BI (business intelligence) solution to some traditional HR problems.
What it does
HIREflection supports the submission of the resume of employees, and their corresponding review by their manager as a number between 1-100. The user is able to choose between two types of searching. The first being keyword based, where the user inputs a keyword, and a bar graph corresponding to the frequency of 10 categories of employees is shown. The second being based on the category of employees, the user submits two interested groups based on management's review, and the six most popular keywords of each group is shown with their frequency on a bar graph.
How we built it
Google Cloud Vision was used to process the resume in PDF format into a Json file with the complete text. The output was then entered into IBM Watson, which allowed us to select keywords. Google Cloud Vision and IBM Watson was selected because both are easy to use, from a trusted source, and there are more documentation available. The keywords returned is parsed using JavaScript and regex. A hashset was used to store the keywords for each resume to support fast retrieval, a dictionary was used to store the frequency of keywords among the collection of all resumes for collective statistics. The front end was built with react because of how it is easy to separate sections into components and the resulting interfaces looks very clean. The back end was built with Express.js since it works well as an interface for Node.js.
Challenges we ran into
Since the focus of HIREflection is on the data processing, it was a challenge for to acquire the keywords. It was difficult to go through two APIs without any previous experience. Due to the different components, it was also troublesome to manage the dependencies that were installed in various locations. For example, one set of node modules needed to be stored for the application server, whereas another for the web server.
Accomplishments that we're proud of
We are proud that we were able to address such a prevalent but unidentified problem in such a simple way. It is something that could be used by a large amount of organizations, and is highly scalable, seeing as the accuracy would only increase. We are also proud that we were able to integrate Express.js and React. We have never done this integration, and the merging conflicts were frustrating, but after completing the project, we could proudly say that we have passed this hurdle.
What we learned
We have never used Google Cloud Vision and IBM Watson, so we had to do a lot of research in the topic. We are not all very familiar with JavaScript, and it required us to write the data structures, so it took a lot of time to verify our syntax. The integration of Express.js and React was also something we have never done but turned out great.
What's next for Hireflection
To scale our application, it would require a database and queries to handle large datasets. The parsed information would also be labeled to allow for more varieties in HIREflection's data analytics and more informative graphs to be used. We would then move on to work with whole phrases instead of keywords, but that would require the implementation of AI. The returned relevancy score would also be used in the analytics.
Built With
- express.js
- github
- google-cloud-vision
- ibm-watson
- javascript
- react

Log in or sign up for Devpost to join the conversation.