Hippocampus
A vector database built for AI agents — not retrofitted from document search, but designed from the ground up for how agents actually manage memory.
Inspiration
The hippocampus is the part of the brain responsible for forming and retrieving memories. AI agents are becoming more powerful every day, but they remain unreliable without memory.
We built Hippocampus — a database that gives agents persistent, semantic memory so they never forget what matters.
What it does
Hippocampus is the core nervous system for AI agents, giving them persistent, semantic memory so they can reason, recall, and act consistently.
It is a vector database built specifically for AI agents, supporting two interaction patterns:
- Agent-Controlled Memory – Agents manage their own memories directly.
- Database-Curated Memory – An internal curation agent decomposes text into structured, meaningful memories.
The web UI is purely for non-technical users; AI agents and developers interact with Hippocampus directly via APIs
Key Features
- Per-agent isolation
- 100ms retrieval
- Agent-to-agent orchestration
- Production-ready, fully serverless architecture on AWS
Real-world impact: In our safety demo, an agent remembered a child’s shellfish allergy weeks later — preventing a dangerous mistake when a parent tried to buy shrimp.
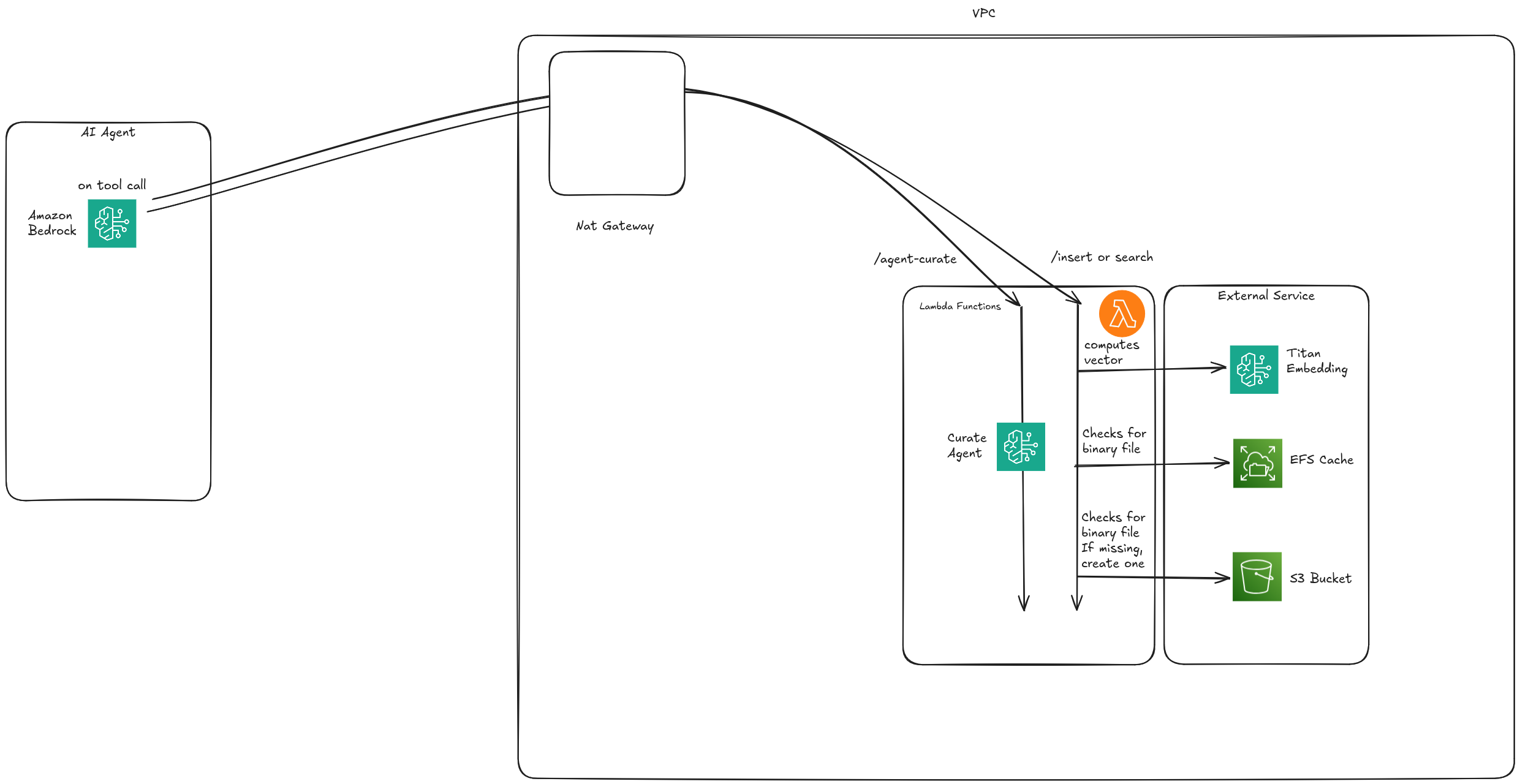
How we built it
- Custom 512-dimensional indexing using sorted arrays and binary search
- Binary serialization with file-based storage (inspired by SQLite)
- AWS stack: Lambda (pure functions), EFS (per-agent files), S3 (backups), and Bedrock (for embeddings and reasoning)
- Agent orchestration: External agents can call internal curation agents
- Built with Go (backend), Python (demos), and Terraform (infrastructure)
Challenges we ran into
- Cross-region Bedrock model availability — solved by making the region configurable
- Overly broad search results — solved with threshold and top-k filtering
- Lambda timeouts with large memories — delays are now configurable
- AWS SDK v1/v2 conflicts — fixed by generating configurations dynamically
- Scalability — redesigned from EC2 to pure Lambda for seamless scaling
Accomplishments that we're proud of
- Built a vector database from scratch, not on top of existing systems like Pinecone.
- Implemented real infrastructure: indexing, serialization, and search algorithms from first principles.
- Beat FAISS by a significant margin in the specific tests that agents actually need — exact search on small to mid-size memories, optimized for latency and determinism rather than throughput.
- Achieved autonomous agent-to-agent orchestration.
- Delivered a real-world safety demo with measurable impact.
- Fully serverless, multi-tenant, and scales elastically with Lambda.
What we learned
- Simplicity scales. Binary search is fast, deterministic, and reliable — billion-scale complexity isn’t needed for agents.
- Agents need databases designed for them, not repurposed document stores.
- Serialization is challenging but powerful when done right.
- Serverless architectures are a perfect match for agent workloads when designed around stateless, file-backed operations.
What's next for Hippocampus
Near term:
- Integration with Bedrock Agents
- Observability dashboard
- Batch operations
Long term:
- A fully managed AWS service for agent memory
- Deep integrations with Bedrock Agents, Amazon Q, and Amazon Connect
- Make Hippocampus the SQLite of AI agents — lightweight, open source, and ubiquitous.


Log in or sign up for Devpost to join the conversation.