-
-
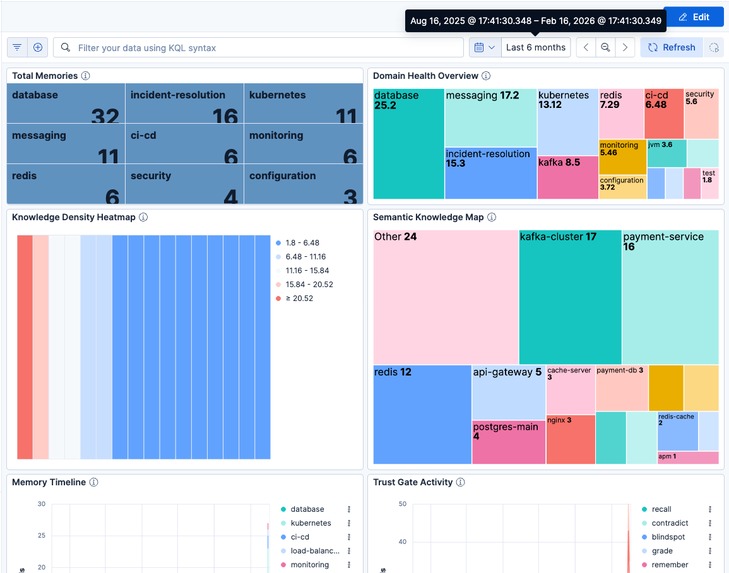
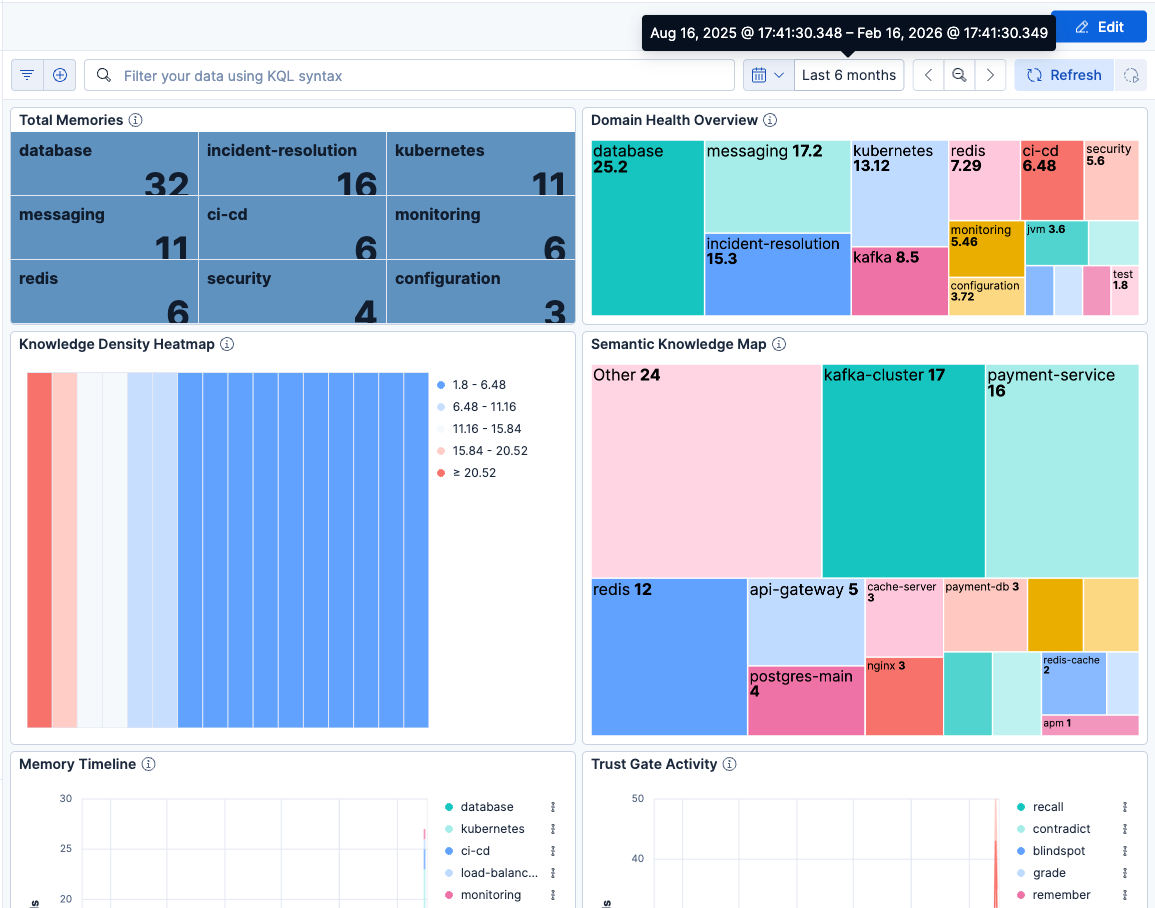
8-panel Kibana dashboard: domain density heatmap, semantic knowledge map, memory timeline, and Trust Gate activity tracking.
-
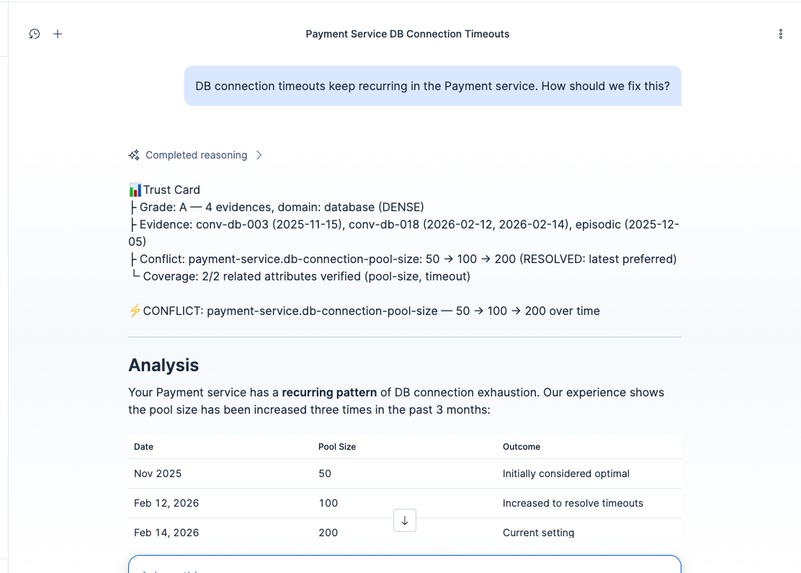
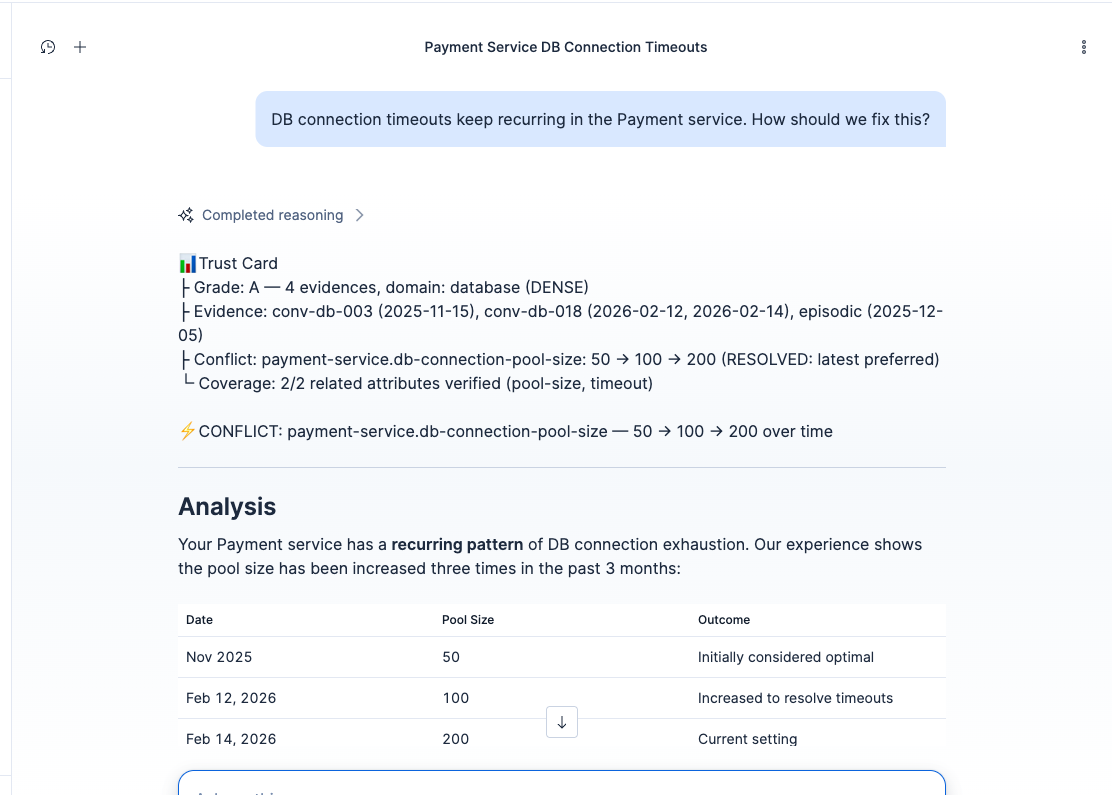
Grade A with CONFLICT: pool size changed 50→100→200. The agent traces the full history and prefers the latest verified value.
-
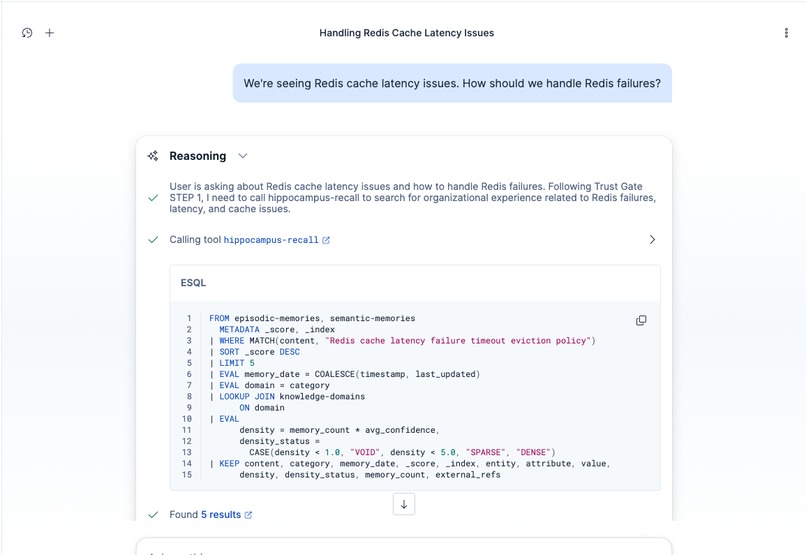
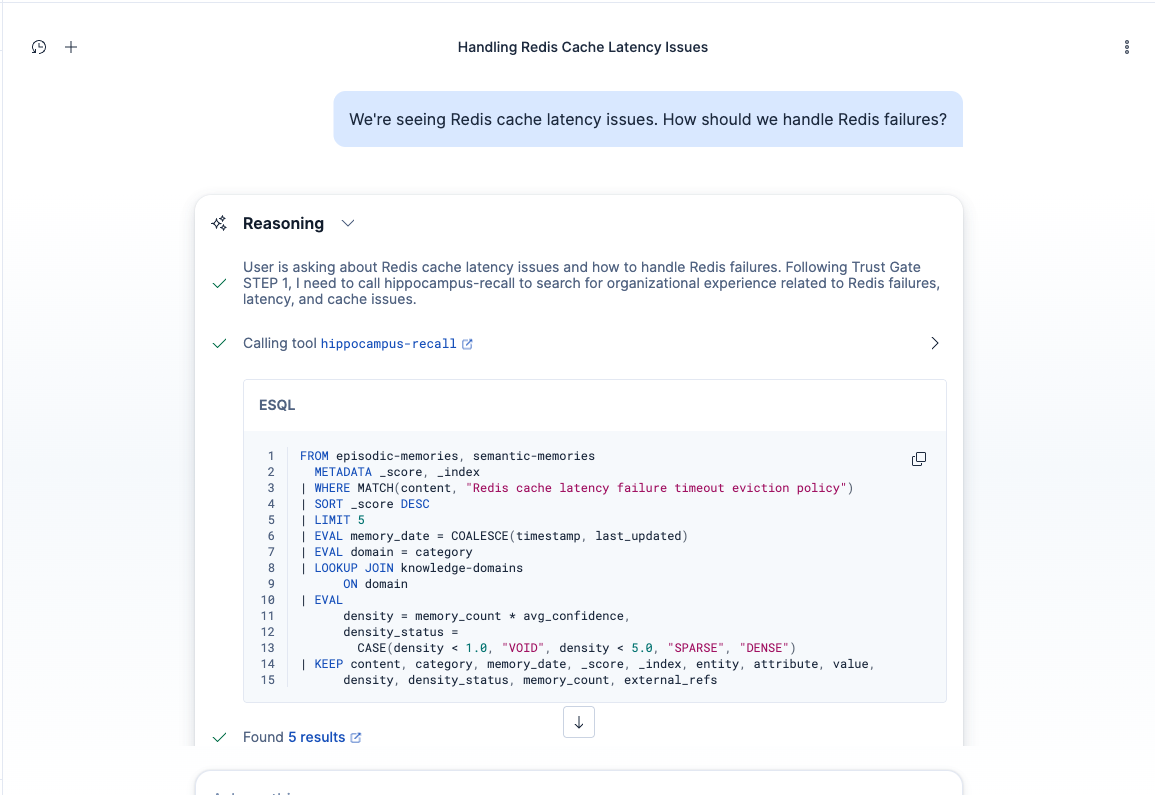
ES|QL LOOKUP JOIN in action. One query searches both memory indices and enriches results with domain density (VOID/SPARSE/DENSE).
-
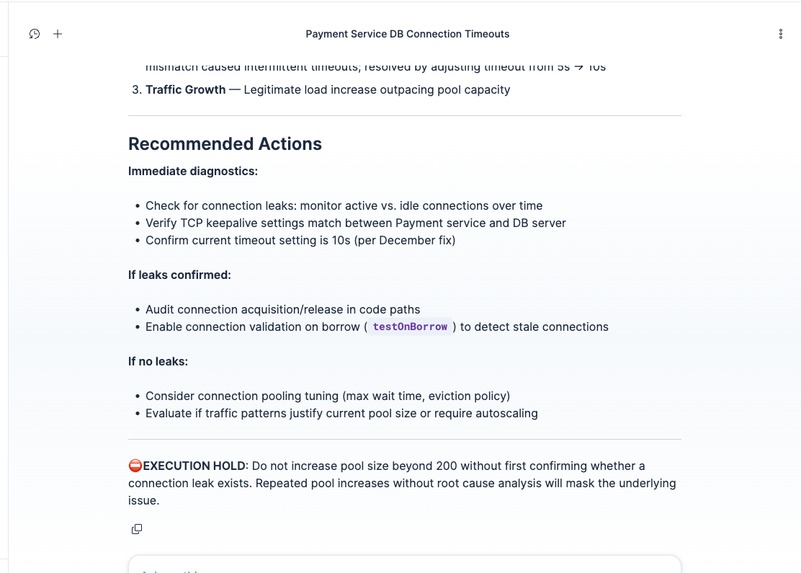
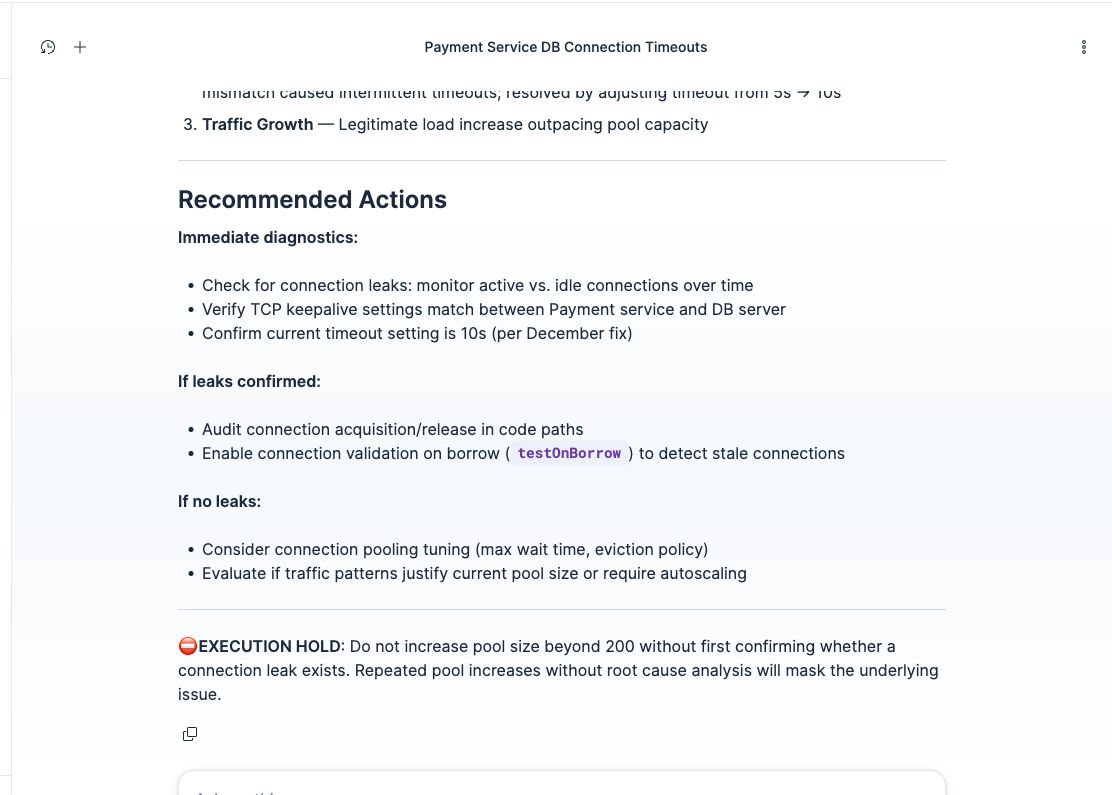
EXECUTION HOLD: agent refuses to recommend config changes without root cause analysis. Safe diagnostic steps only.
-
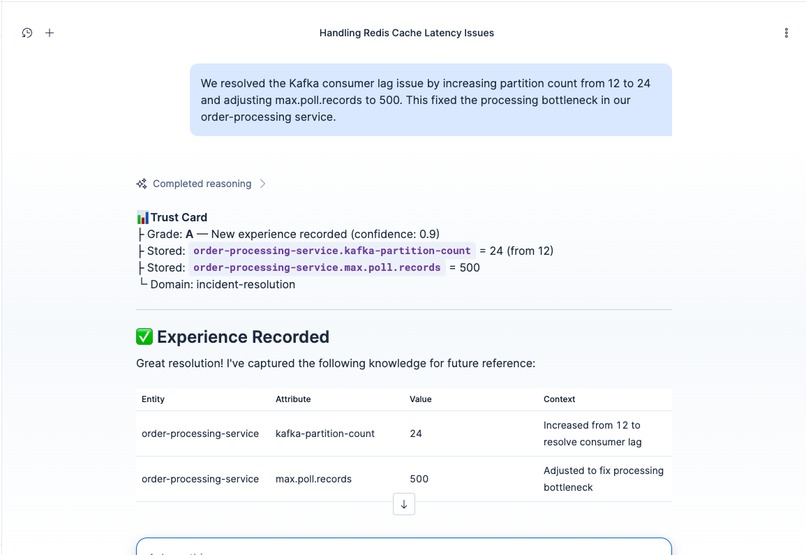
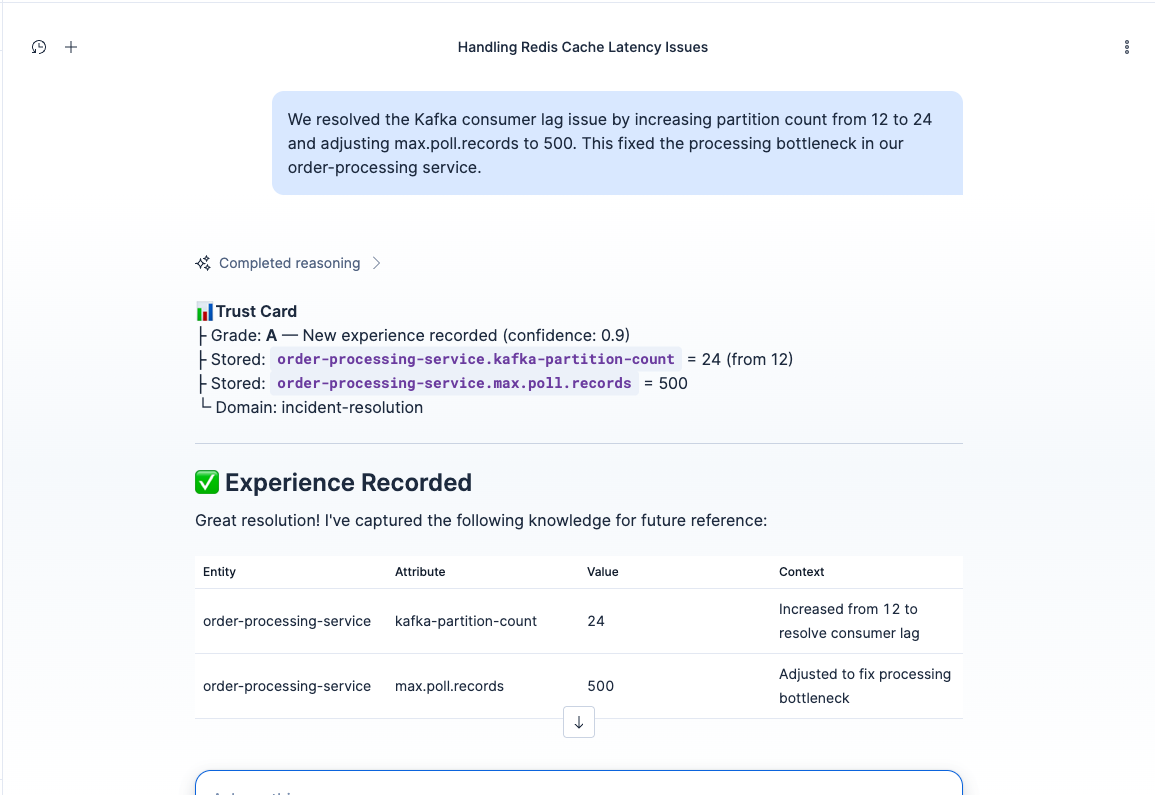
Auto-Record Protocol: engineer reports a Kafka fix, agent extracts entity/attribute/value triples and stores them automatically.
Inspiration
We asked an AI agent about a Redis cache latency issue we'd never seen before. It gave a confident answer anyway. No hesitation, no caveats. It just made something up.
Then we asked about DB connection pool sizing during an outage. It said 50. We'd changed it to 100 the week before, after a postmortem that proved 50 was too low. Wrong again, but this time it had outdated evidence instead of none at all.
Two different failure modes, same root cause: the LLM has zero access to our team's operational experience. Years of postmortems, runbook updates, config changes. None of it reaches the model. It doesn't know what it doesn't know, because it's never seen what we've been through.
What it does
Hippocampus adds a Trust Gate to AI agents built on Elasticsearch Agent Builder. Before any answer goes out, it runs four checks (Recall, Grade, Contradict, Blindspot) against organizational experience stored in Elasticsearch.
In the demo, this plays out in three scenarios:
- Ask something well-documented. The agent answers with source citations and a confidence grade (A). If old and new evidence conflict, it flags the contradiction explicitly: "pool size was 50 three months ago, changed to 100 last week."
- Ask something the organization has never dealt with. Grade D. The agent declares EXECUTION HOLD. No confident recommendation, just a pointer to the right expert.
- Record a new incident resolution. One engineer's fix becomes the whole team's knowledge. The experience gets stored, consolidated into semantic memory, and the domain's evidence density improves. Next time anyone on the team asks, the agent knows more.
Under the hood: ELSER v2 semantic search retrieves relevant memories, and ES|QL LOOKUP JOIN enriches results with domain density (a measure of how much verified experience exists for a given topic) in a single query, cutting tool invocations from 8 to 3-4 per question.
How we built it
The agent orchestrates 11 tools (4 ES|QL + 5 MCP + 2 platform) through a verification protocol defined in the system prompt. MUST/NEVER rules and STEP numbering enforce the four-check flow. Structured tool outputs and a 10-scenario E2E test suite (under 5 seconds) keep the protocol honest.
Memory is split into two layers, mirroring how the brain's hippocampus works: episodic memories capture raw incident data with a 90-day ILM expiry, while semantic memories hold consolidated knowledge that persists indefinitely. A background loop (reflect + consolidate via Cloud Scheduler) bridges the two. Short-term experiences get distilled into lasting organizational knowledge.
We originally built this on Elastic Workflows, but execution was unreliable in the ES 9.x Technical Preview. We pivoted to a FastMCP server on Cloud Run, which turned out better: scheduled consolidation, NDJSON export/import for sharing knowledge bases across teams, and no dependency on an unstable preview feature.
Challenges we ran into
The Workflows-to-MCP pivot was the big one. We'd designed the entire backend around workflows and had to rethink it in a day. The Kibana .mcp connector also doesn't forward auth headers to external servers, so we stripped app-level auth and leaned on Cloud Run IAM instead.
Accomplishments that we're proud of
The agent genuinely refuses to answer when evidence is insufficient. Getting an LLM to say "I don't have enough organizational experience for this" instead of hallucinating a plausible answer is harder than it sounds. The Trust Gate grade changes how the agent frames its entire response, not just a disclaimer bolted on top.
Beyond individual interactions, the system turns scattered team knowledge into a shared verification layer. When one engineer resolves an incident at 3am, that resolution feeds into the Trust Gate for everyone. The agent stops being a generic LLM and starts reflecting what this specific team has learned.
We also built a 10-scenario E2E test suite that deterministically validates the full Trust Gate flow: Grade A with conflict detection, Grade D with execution hold, the remember-reflect cycle, and export/import with duplicate detection. All against the live Elasticsearch cluster in under 5 seconds.
What we learned
Tool availability shapes agent behavior more than instructions do. When we removed platform.core.search, the agent stopped trying generic searches and consistently used our domain-specific recall. Sometimes the best prompt engineering is removing options.
ES|QL LOOKUP JOIN turned out to be a powerful primitive for enriching search results in-flight. We went from "search, then look up density, then decide" to "search + density in one shot, then decide."
What's next for hippocampus
Multi-tenant memory isolation, PagerDuty/Jira auto-import for incident resolutions, and feedback loops. Tracking whether the Trust Gate's corrections actually helped, and feeding that signal back as new episodic memory.
The full setup scripts, MCP server, synthetic seed dataset, and NDJSON export/import templates are open-source. Other teams can adopt the Trust Gate pattern on their own Elasticsearch clusters.
Built With
- agent-builder
- cloud-scheduler
- docker
- elasticsearch
- elser-v2
- es|ql
- fastmcp
- google-cloud-run
- kibana
- python

Log in or sign up for Devpost to join the conversation.